Semantic web technologies to reconcile privacy and context awareness
Texte intégral
Figure






Documents relatifs
The platform is composed of the Cube ontology 2 and the Project vocabulary 3 which is used to support data capture and analysis through the Cube methodology, a safety
Previous research work has developed tools that provide users with more effective notice and choice [9, 18, 19, 31]. With increasing concerns about privacy because of AI, some
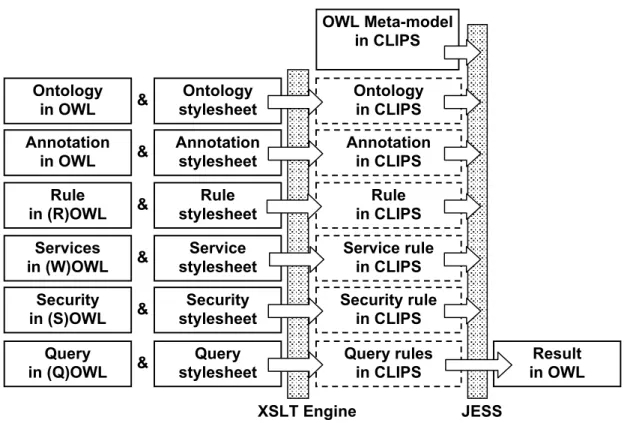
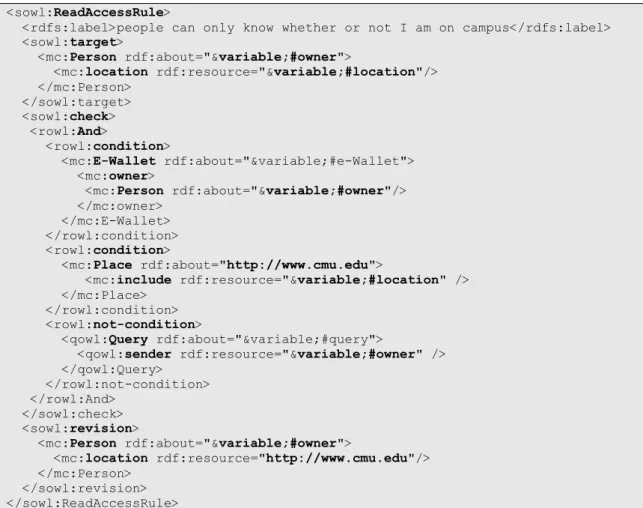
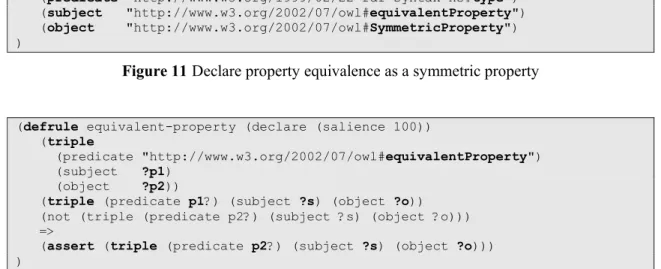
In our work, we use Semantic Web technology through an ontology to define a hierarchical context model for a user and a requester an rules are defined using the Semantic Web
In view of the large number of active substances and increasingly low MRLs, the analysis techniques used to analyse compounds must be reliable, highly selective and capable
We show through preliminary models of systems related to what is described in [18] as “privacy mirrors”, how the data integration, analytics and sense- making capabilities that
Considering the importance of a proper representation of relevant rules formulated for handling personal information, described in laws, guidelines, policies, and other
4.2 Computing the Observed Trust in Domains and Data Criticality Our goal here is, relying on the simple notion of data transfer defined above, to analyse the behavior of the user
Keywords: Behavioural Science, Behavioural Economics, Health Promotion, Public Health, Nudge.. David McDaid is Senior Research Fellow at LSE Health and Social Care and at
