Brian2GeNN: accelerating spiking neural network simulations with graphics hardware
Texte intégral
Figure
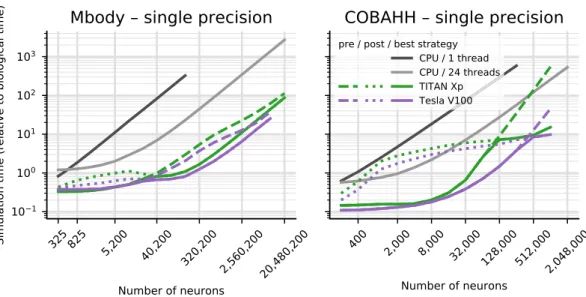
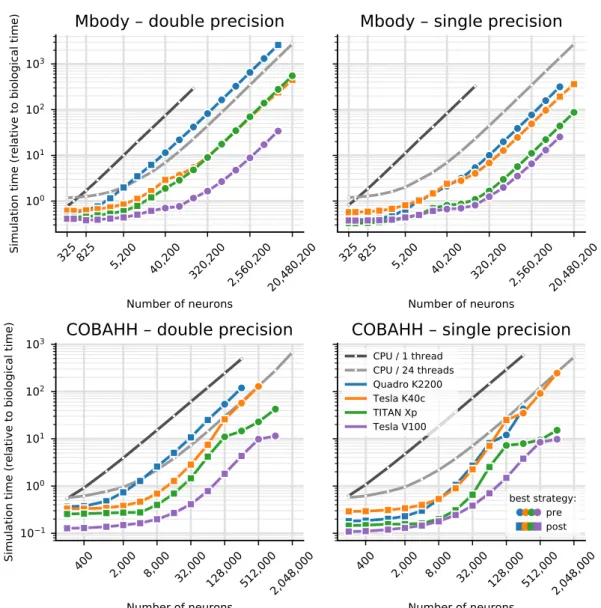
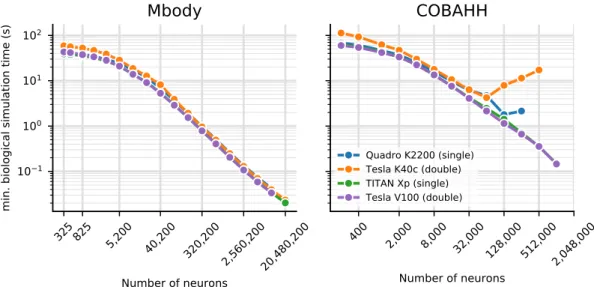
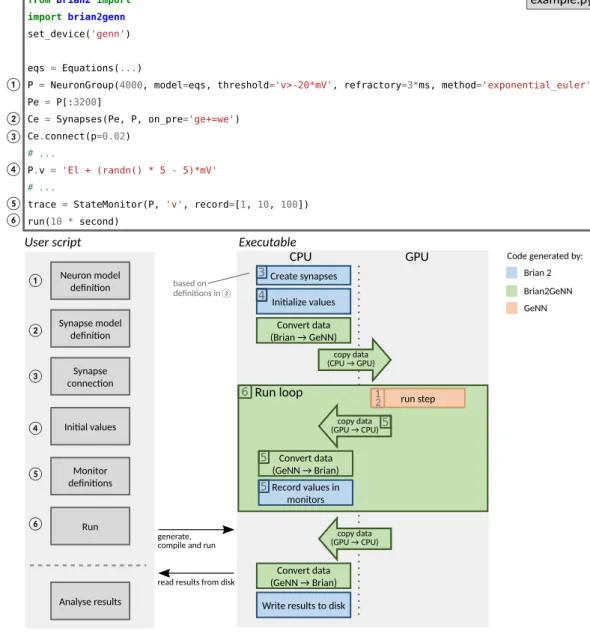
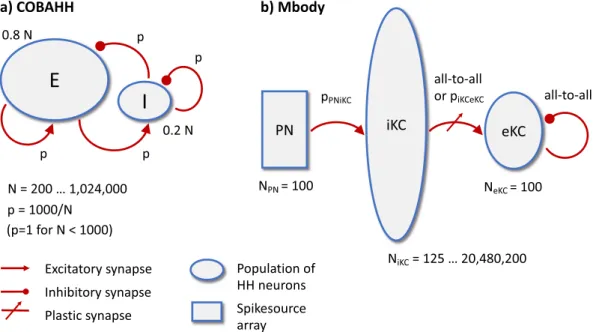
Documents relatifs
Onil Nazra Persada Goubier et al.: Wireless Sensor Network-based Monitoring, Cellular Modelling and Simulation UBO/LABSTICC developed PickCell / NetGen, a basic tool allowing
Unité de recherche INRIA Rennes : IRISA, Campus universitaire de Beaulieu - 35042 Rennes Cedex (France) Unité de recherche INRIA Rhône-Alpes : 655, avenue de l’Europe - 38334
In this pa- per, a finite element model with enhanced kine- matics for the simulation of structures with em- bedded anchors is presented.. An elemental en- richment is added to
In particular, a steady solution was obtained, even if in [19] experimen- tal measurements showed an unsteady behavior of the cavitating flow. This was due to the choice of
During all the access area, the request can be asynchronously treated because the simulation description ensures that the data will not be modified. At the end of
photons Collimator Detected photons Emitted photons ARF plane ARF-histo Emitted ARF-nn or One count in one energy window Detection probability in all energy windows Image
In addition, based on the observation that the full range of floating point accuracy may not be always needed, we propose and implement an initial design of the tolerance value
This garbage comes from the original clauses at the start of the DPLL (T ) rewriting sequence, which might have been simplified in later steps of DPLL (T ) but which remain unchanged
