A MRF Shape Prior for Facade Parsing with Occlusions
Texte intégral
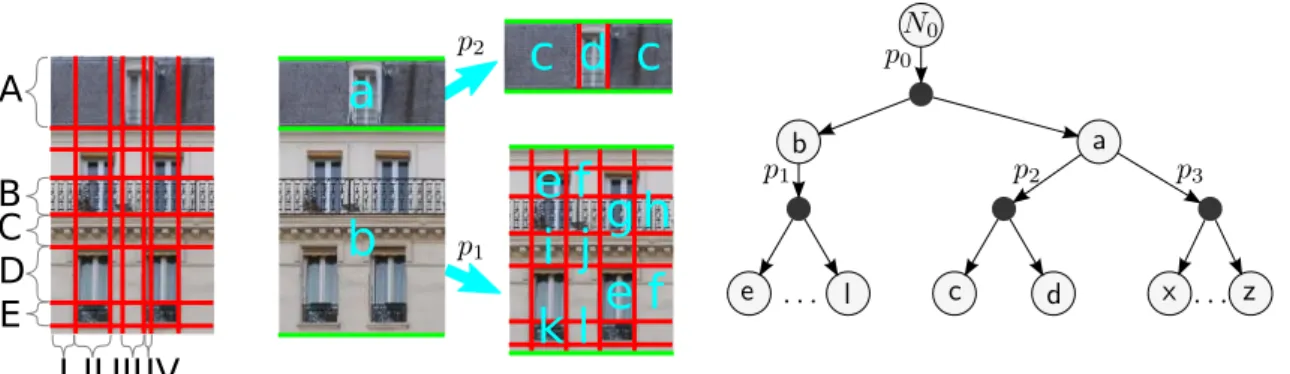
Figure
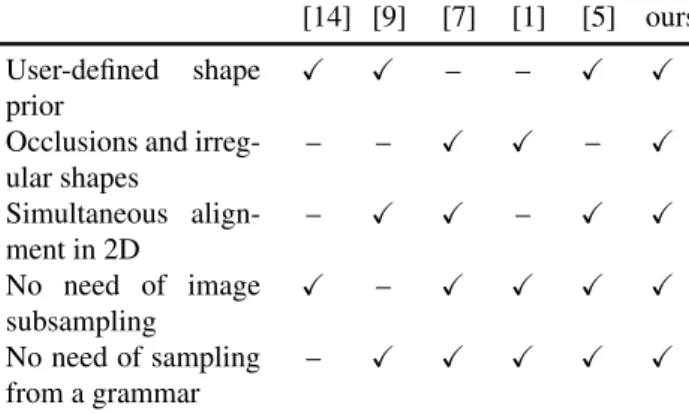


![Table 4. Performance on the eTrims dataset with RNN-based unar- unar-ies. Starting from left: score using raw unaries, layer 3 of [7], results of [1] and our results.](https://thumb-eu.123doks.com/thumbv2/123doknet/14516848.530677/8.892.66.415.260.464/table-performance-etrims-dataset-starting-unaries-results-results.webp)

Documents relatifs
Results obtained on both synthetic and digital radiographs reconstruction (DRR) show that the proposed model improves on existing prior and non-prior shape based image
Convergence histories for the chaining procedure of topological and geometric optimization methods; (left) the ‘classical’ level set method is performed on a fixed triangular mesh
While the con- tact mechanics analysis is simplified, they are nevertheless commonly accepted and experimentally validated models for calculating contact pressure distributions (P˜
Section 2 presents the frictionless contact model and gives four different friction conditions depend- ing on the chosen model: Tresca, Coulomb, Norton Hoff and normal
Village leaders not accountable for all villagers.. How to mitigate the vertical constraints?. Step by step towards a dialogue between villagers & National
Figure 4: Small extracts of the OCR results obtained on scanned document images: (a) input image (no restoration); (b) k-means segmentation + restoration; (c) single MRF
ABSTRACT: By combining the use of a coupling feed and a band-stop matching circuit, the proposed small-size loop antenna for the tablet computer application can operate at
Using this information, we develop a procedure to estimate the drift rate of thermistors deployed in the field, where no reference temperature measurements
