Algorithms and systems for low power time-of-flight imaging
Texte intégral
Figure

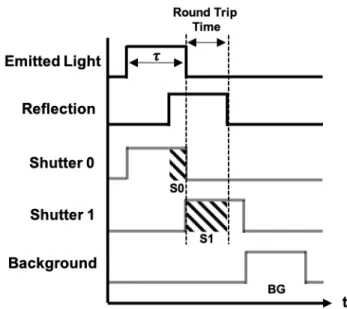



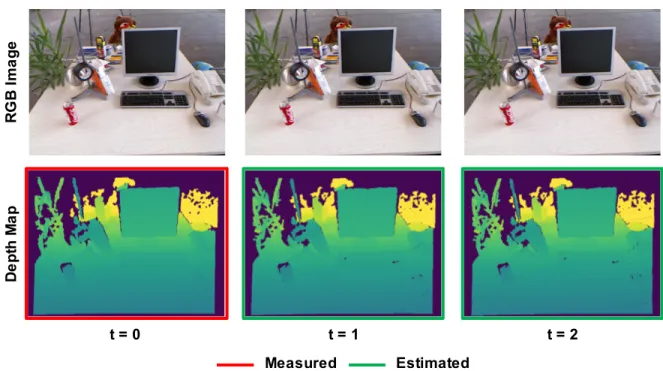

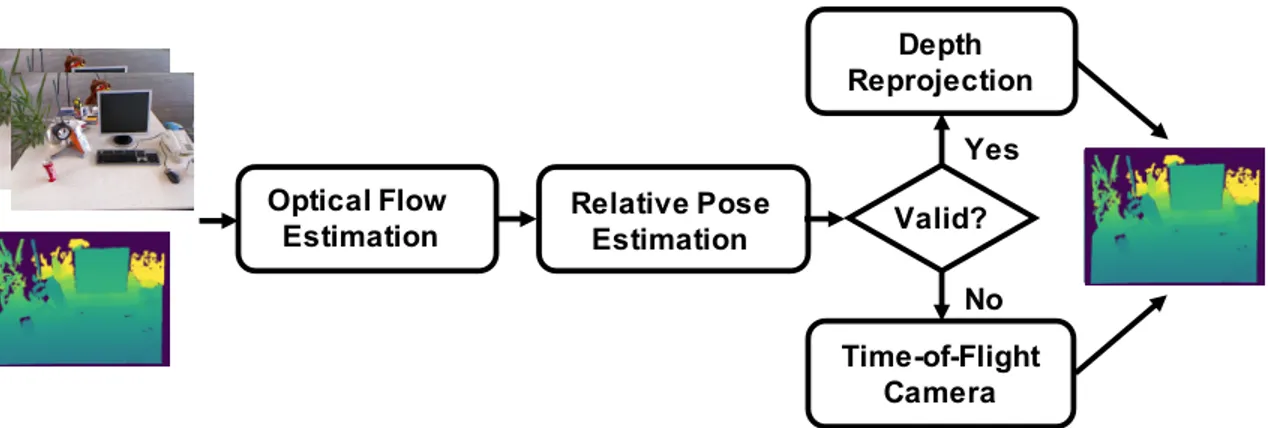
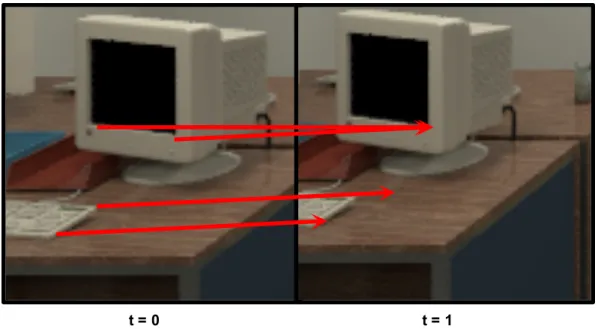
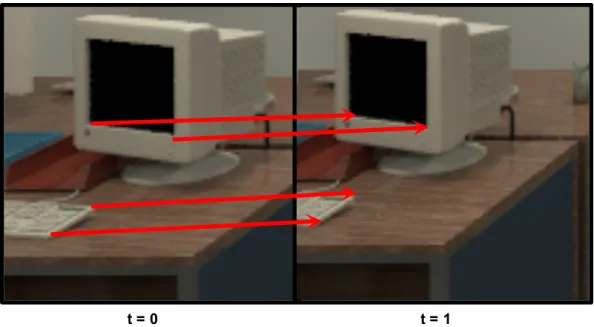
Documents relatifs
This strongly suggests that orbit of the Teichm¨ uller flow of an element of D in the door direction should accumulate a moduli space of translation tori (which lies in the boundary
We all want to be friendly with our neighbours, but we also need our privacy. Some neighbours may be too friendly to the point that they start to become nosy, and far too friendly
We prove that there exists an equivalence of categories of coherent D-modules when you consider the arithmetic D-modules introduced by Berthelot on a projective smooth formal scheme X
This conjecture, which is similar in spirit to the Hodge conjecture, is one of the central conjectures about algebraic independence and transcendental numbers, and is related to many
Ne croyez pas que le simple fait d'afficher un livre sur Google Recherche de Livres signifie que celui-ci peut etre utilise de quelque facon que ce soit dans le monde entier..
Indeed, in Escherichia coli, resistance to nonbiocidal antibio fi lm polysaccharides is rare and requires numerous mutations that signi fi cantly alter the surface
Where depth cannot be recov- ered using purely local information, the depth evidence from the epipolar image provides a principled distribution for use in a maximum-
La plénitude dans le ciel, ou cercle de Gwenved ; et sans ces trois nécessités, nul ne peut être excepté Dieu. îS Trois sortes de nécessités dans
