HAL Id: hal-02408011
https://hal.archives-ouvertes.fr/hal-02408011
Submitted on 12 Dec 2019HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Brigitte Grau
To cite this version:
Brigitte Grau. Les systèmes de question-réponse. M. Ihadjadène. Méthodes avancées pour les systèmes de recherche d’information, Hesmès, 2004, Traité des sciences et techniques de l’information. �hal-02408011�
Les systèmes de question-réponse
1 Introduction
Les moteurs de recherche standard, tels les moteurs disponibles sur le Web, offrent tous le même type de formulation des requêtes. Hormis la requête élémentaire contenant une liste de mots, il est possible de préciser si on veut tous les mots ou au moins l'un des mots, certaines phrases ou expressions exactes, enfin on peut exclure certains mots. De plus, il est possible de préciser où ces mots doivent être cherchés (texte du document, meta-descripteurs, titre). Ces contraintes sont toutes destinées à décrire le type de document cherché : les documents qui contiennent ou non les mots donnés. Le type d'information cherchée n'est, lui, pas explicite, et il n'est pas précisé si effectivement on désire tous les documents qui parlent d'un sujet ou bien seulement une information précise ou encore une définition. Les moteurs sont conçus pour répondre à des recherches globales sur un thème donné, et c'est à l'utilisateur du moteur de transformer son besoin en une requête qui maximise ses chances de succès, et ensuite fouiller les documents retournés pour trouver sa réponse. Dans le cas d'un besoin précis d'information, qui peut s'exprimer en une question, il est intéressant de partir d'une formulation en langue et de fournir en résultat la réponse attendue, et non un document. Ainsi, si on veut savoir qui a tué Henri IV, il est plus confortable et surtout rapide de poser directement la question, et d'obtenir juste un nom, Ravaillac en l'occurrence, ce qui n'interdit pas la présence d'un document ou d'un passage justificatif. A l'heure actuelle, avec de la chance, on peut trouver la réponse dans l'extrait fourni par le
1
moteur, s'il en donne un, sans quoi il faut consulter les documents les uns après les autres.
Cette problématique n'est pas nouvelle et des travaux existent depuis les débuts du traitement automatique de la langue, afin de trouver la réponse à des questions précises constitue le problème en soi ou un moyen de vérifier qu'un texte a été bien compris (voir section 3). Dans le premier cas, il s'agit d'applications destinées à trouver des réponses factuelles dans une base de connaissances; dans le second les questions sont plus orientées vers l'explicitation d'inférences et d'explications.
2. Problématique
2.1. Où chercher ? Quelles conséquences sur le processus de recherche des réponses ?
Selon les applications, la recherche s'effectuera dans des ressources différentes. La veille technologique s'orientera vers le Web pour répondre à des questions telles que la liste des entreprises dont le chiffre d'affaire est en baisse au mois de juin 2003, ou les entreprises qui fabriquent des produits X ou Y. La recherche d'informations techniques, telles que « comment installer une imprimante ? » ou « quelle est la commande qui permet de recopier un fichier ?», s'effectuera dans des manuels ou sur le Web, ou sera traité plus spécifiquement par la recherche dans des FAQ2. Connaître le gagnant du prix Nobel en 1965 sera possible en consultant une
base d'articles de journaux ou le Web. On pourra aussi s'adresser à des bases de connaissances factuelles ou encyclopédiques, structurées ou semi-structurées, pour obtenir une information.
Quelles sont les différences induites par ces différents supports ? Premièrement la fiabilité de la réponse. Une base de connaissances sera considérée comme fiable si elle a été vérifiée lors de sa construction, de même que les manuels techniques ou les articles scientifiques. Ensuite viennent les articles de journaux, diffusant généralement une information vérifiée, enfin vient en dernière position le Web où il ne suffira pas de trouver une information, encore faudra-t-il la vérifier ou la valider. Deuxièmement, les techniques d'interrogation et d'extraction des réponses changeront si l'on connaît a priori le domaine de la question (comme pour des questions dans des manuels techniques ou des modes d'emploi) ou non. C'est pourquoi nous ne nous intéresserons pas à tous les types d'interrogation dans ce chapitre, mais nous nous centrerons sur les questions portant sur tout domaine, dont la réponse tient en quelques mots, et est recherchée dans des textes. Une deuxième caractéristique influant fortement sur les techniques utilisées est liée à la redondance des réponses existantes, en nombre et en variabilité dans leur formulation. Lorsque
l'on pose « a tué ‘Henri IV' » à Google3, la réponse arrive sous cette forme « …Mais
il se fait bloquer dans une rue du vieux Paris par Ravaillac, un catholique, qui le tue avec un poignard. Henri IV était peu populaire, il l'est devenu ... », en 7ème position. Il faut remarquer que si le passage est ici suffisamment explicite, l'extraction de la réponse seule relève d'un processus complexe si Ravaillac n'est pas reconnu comme un nom de personne, car la forme de la réponse correspond à une variante syntaxique de la question et ne peut être dérivée de façon immédiate. Si Ravaillac apparaît dans plusieurs passages, des techniques plus frustres, telles que le repérage des mots identiques dans les passages, pourront être appliquées. Néanmoins, une requête quasi identique à la forme originelle de la question est ici suffisante. Si l'information cherchée est plus rare et moins explicite, la requête devra en tenir compte et sera formulée différemment, avec utilisation du stemming pour gérer les variations morphologiques ou l’ajout de termes synonymes ou l'introduction d'informations caractérisant le type d'information cherchée, telles le type de la réponse (un nom de personne, une date). On voit ainsi se dessiner la complexité de la tâche, ainsi que la diversité des processus applicables pour la résoudre, où la difficulté pour résoudre une question n'est pas liée seulement au type de la question mais aussi aux propriétés de la base de connaissances par rapport à cette question.
2.2. Quelle compréhension ? Quels mécanismes sous-jacents ?
Répondre à une question est vu ici comme un problème de recherche et d'extraction d'information : recherche des documents ou des passages susceptibles de contenir la réponse puis extraction de celle-ci. Sa résolution requiert la mise en œuvre de processus variés, modélisant des niveaux variables de compréhension, où les processus sont plus ou moins génériques, allant de l'utilisation de formes figées à l'utilisation de représentations sémantiques des phrases, de techniques d'application de patrons à des techniques d'appariement plus élaborées. Prenons l'exemple présenté figure 1 pour illustrer ces niveaux de compréhension.
Pour répondre à la première question à partir du texte donné, une stratégie de base consiste à déduire de la question que la réponse est un nom de personne, et comme ce type d'information est fréquent, on affine l'extraction en recherchant un patron de la forme donnée dans l'exemple, admettant des variations pour la conjugaison du verbe. C'est ainsi que l'on peut sélectionner Ravaillac dans la dernière phrase du texte. Notons qu'il faudra savoir associer patrons de réponse et questions. Ce type de patron consiste à rechercher une suite de mots donnés ou d'un type donné dans une phrase. Afin de limiter le bruit, on peut ajouter des contraintes syntaxiques sur la fonction grammaticale des composants cherchés (question 2). On gagne ainsi en fiabilité, mais aussi en flexibilité, car on ne travaille plus sur les mots
tels qu'ils apparaissent dans la phrase, mais sur le résultat d'une analyse syntaxique partielle ou totale, et donc sur une représentation syntaxique de l'énoncé qui s'est affranchie de l'ordre des mots. La question 3 propose une variante sémantique de la même question. Dans ce cas, en plus des processus précédents, il s'agira de faire varier les mots et de travailler sur le plan des concepts ou du moins d'ensembles de synonymes.
Ville ou Pays dans le contexte
ou
Tuer => Mort
Rendre son dernier soupir => Mort
1) Qui a poignardé Henri IV ?
3) Qui a tué Henri IV ?
4) Où a été tué Henri IV ?
Personne <poignarder> Henri IV
SUJET COD
Personne <poignarder> Henri IV
Tuer synonyme de poignarder Questions Critères pour extraire la réponse
2) Qui a poignardé Henri IV ?
SUJET COD
… C’est à Paris, rue de la Ferronnerie, qu’Henri IV a rendu son dernier soupir… D’autre part, on peut rappeler que les rues encombrées et étroites du Paris d’avant Haussmann étaient très favorables aux guets-apens. La facilité avec laquelle Ravaillac a pu poignarder Henri IV peut paraître incroyable ! …
Figure 1. Exemple de niveaux de traitement pour trouver une réponse
Quant à la quatrième question, si l'on déduit que la réponse est une ville (ou un pays) de la question, cette information ne suffit pas dans la mesure où la phrase mentionnant le fait que Henri IV a été poignardé ne contient pas de lieu. Il faut donc pouvoir délimiter un contexte autour d'un nom de lieu afin d'en déterminer sa portée, ou bien procéder à une analyse sémantique fine, et inférer que rendre son dernier soupir, présent dans la phrase mentionnant le lieu, entraîne la mort et qu'il en est de même pour tuer. Il s'agit ici de procéder à une analyse en profondeur de ce passage de texte.
Une caractéristique importante qui permet d’envisager des applications réelles question-réponse est la diversité des textes et des styles : une information sera souvent présente sous différentes formes, ou sous une forme courante, ce qui
augmente la probabilité de la trouver. Il reste néanmoins des informations rares pour lesquelles il est nécessaire de mettre en œuvre des processus complexes.
3. Historique
Les premiers systèmes de traitement de la langue des années 1960-1970 étaient des systèmes de question-réponse sur des domaines restreints, que ces systèmes aient été développés dans un but de recherche d'information ou d'interface en langue naturelle. Ainsi, BASEBALL en 1963 [GRE 86], SIR en 1968, LUNAR en 1973 et LADDER en 1977 (voir [BAR 81] pour une description de ces systèmes) permettaient tous trois d'interroger une base de connaissances structurée, en faisant éventuellement des inférences. BASEBALL disposait d'une base d'un an de faits concernant l'American League, et permettait de répondre à des questions du type «Combien de jeux ont joué les Yankees en juillet ?» ou «Contre qui ont perdu les Red Box le 5 juillet ?» ou encore «Est-ce que chaque équipe a joué au moins une fois dans chaque stade chaque mois ?». SIR répondait à propos de faits qu'il avait interprétés et stockés et enfin LUNAR et LADDER offraient une interface en langue naturelle sur une base de connaissances, représentant les informations sur la composition du sol lunaire rapportées par la mission Apollo 11 d'une part et des informations pour un système d'aide à la décision pour la Navy. LUNAR autorisait des questions enchaînées du type «Quels échantillons contiennent du P205 ? », Donne-moi les analyses du P205 dans ces échantillons». On peut toutefois noter des différences dans l'analyse des questions. Alors que BASEBALL fonctionnait par une décomposition en groupes et l'utilisation de mots-clés, SIR utilisait des patrons et LUNAR (ainsi que LIFER, l'interface de LADDER) intégrait une analyse de phrases par une grammaire ATN complétée d'une analyse sémantique.
Alors que pour tous ces systèmes le problème central n'était pas le traitement de questions, mais la recherche d'information ou la réalisation d'une interface en langue, Lehnert, avec son système QUALM [LEH 77], s'est posé le problème de la modélisation des questions et de l'élaboration de stratégies selon le type d'information demandé. Elle a ainsi proposé une classification en treize classes qui ont servi de base à bon nombre de systèmes actuels, même si certaines de ses catégories doivent être raffinées pour une recherche dans des textes portant sur tout domaine pour lesquels le processus d'interprétation est forcément moins approfondi. En effet QUALM permettait de poser des questions sur des histoires analysées par les systèmes SAM et PAM [SCH 77], avec une représentation des informations sous forme de dépendances conceptuelles et de scripts. La stratégie de résolution des questions, et donc les heuristiques appliquées, différait selon la catégorie de question. Cette catégorisation permettait aussi de déterminer le type d'information à fournir en réponse. Même si ce type d'approche peut théoriquement s'appliquer sur des textes portant sur tout domaine, elle requiert des bases de connaissances très
structurées représentant la sémantique et la pragmatique de la langue et du monde en général, connaissances qu'il n'est pas envisageable ni même possible de fournir à un système. Néanmoins, une approche purement TAL peut être réalisée pour un domaine d’application limité, tel que cela a été fait dans le système Extrans [MOL 00] qui répond à des questions portant sur les commandes Unix. Extrans repose principalement sur une analyse syntaxico-sémantique du manuel Unix permettant la réalisation d’inférences par la mise en œuvre d’un raisonnement logique. Le domaine étant celui des commandes disponibles dans un système informatique, on peut développer une base de connaissances précises pour le représenter, que ce soit pour le lexique, où on peut limiter les ambiguïtés, ou pour les connaissances sémantiques. Signalons que ce système propose aussi un mode de fonctionnement dégradé en cas d’échec de la première approche, mode reposant sur l’exploitation de mots-clefs.
Afin de passer outre la nécessité d'une analyse complète des textes pour répondre à des questions de tout type et portant sur tout domaine, le problème peut se poser différemment : au lieu d'envisager des questions dont les réponses sont des types très génériques, on précise le type d'information cherchée afin de la retrouver et l'extraire de textes. On se place ainsi dans le domaine de l'extraction d'information. Les conférences MUC4, organisée par le DARPA, qui ont vu le jour à la fin des années
80 et ont duré jusqu'en 96, ont permis une avancée rapide du domaine. A l'instar des systèmes de question-réponse, les systèmes en extraction d'information sont complexes et comportent de nombreux composants (voir [HOB 93] pour une description générique). L'extraction d'information consiste à définir la requête par un patron, et à chercher à remplir ses différents composants selon l'information contenue dans les textes. Par exemple, dans MUC-4 [ARP 92], le but était de retrouver des informations sur le terrorisme, à savoir celui qui a réalisé un attentat, quand, quelle victime, etc.
Les premiers systèmes visaient la réalisation d'une analyse complète des phrases des textes (des articles de journaux). Cette approche a été abandonnée au profit d'analyses de surface des textes, comme cela peut être illustré par les travaux du SRI qui a abandonné l'approche générique de TACITUS pour un système dédié, FASTUS [HOB 96], se focalisant sur l'information cherchée uniquement. C'est ainsi que se sont notamment développées les recherches sur les entités nommées, à savoir le repérage de noms de personne, d'organisation, de lieu, de date, etc. et les systèmes ont réalisé des performances de plus de 90% dans cette tâche.
Les systèmes d'extraction d'information sont principalement fondés sur l'utilisation de patrons d'extraction, tels que <PERSON> was <killed/murdered> qui permet de remplir l'acteur de l'attentat par l'entité nommée PERSON. Ces patrons étaient principalement créés manuellement, même si des travaux concernant leur
acquisition automatique, ou semi-automatique, sans qu'il y ait nécessité de disposer d'un gros corpus annoté ont vu le jour [RIL 96], mais sans apporter de véritable réponse au problème de devoir recréer, pour chaque type d'information cherchée, un ensemble de patrons d'extraction. Néanmoins, on peut considérer que ces systèmes ont jeté les bases de techniques reprises dans le cadre des systèmes de question-réponse.
Les différentes approches développées en extraction d'information sont elles-aussi significatives de l'évolution du TAL en général, qui est passé de l'étude de mécanismes généraux jusqu'à la fin des années 80 et le début des années 90 à l'étude de mécanismes dédiés, notamment en analyse, avec l'étiquetage morpho-syntaxique, les analyses robustes de surface des phrases, le repérage de marqueurs dans des textes, les traitements statistiques, etc., approches qui ne requièrent pas nécessairement des bases de connaissances sémantiques. L'idée de construire une large base de connaissances générales est cependant restée, et ont eu lieu notamment les travaux de Lenat sur la constitution de bases encyclopédiques (CYC [LEN 95]), et les travaux sur WordNet, visant la construction d'une base lexicale sémantique [FEL 98]. Si le projet CYC pas donné lieu pour le moment à des avancées significatives dans le domaine de la compréhension de la langue, WordNet est largement utilisée. Cette base organise les concepts en une hiérarchie et fournit un ensemble de relations pouvant être lexicales telles la synonymie, ou conceptuelles telles l'hyperonymie. Des définitions en langue sont en outre associées aux concepts. Cette ressource est largement utilisée dans les systèmes de question-réponse.
Avec le niveau de réalisation atteint par les travaux précédemment cités, ainsi que la multiplication des documents en ligne, qui peuvent être considérés comme une très vaste base de connaissances même si elle n'est pas structurée, la problématique question-réponse a pu à nouveau être abordée, mais avec une vision différente des premières approches. Ainsi, lors de la conférence TREC-8 en 1999 [VOO 01], la première évaluation de systèmes de question-réponse a vu le jour et connaît un important succès depuis lors. Le principe est de répondre à des questions factuelles, questions de type encyclopédiques dont la réponse peut-être formulée en peu de mots, sans limitation du sujet, par extraction d'un passage de texte. La base de documents est constituée d'articles de journaux.
Le fait de s’intéresser à des questions factuelles et encyclopédiques portant sur des événements dont on a rendu compte dans des textes, et non à des questions visant à connaître les tenants et les aboutissants d’une histoire, permet de mettre en œuvre des méthodes efficaces reposant sur des ressources et outils actuellement disponibles. Dans ce contexte, il s’agit de retrouver une réponse telle qu'elle figure au sein d’un ensemble de textes, ensemble le plus vaste possible car sa taille est en relation avec les chances de trouver une réponse à la question posée. Des méthodes de type recherche d’information sont utilisées pour sélectionner des passages
intéressants dans un grand corpus. Cette première sélection permet ensuite d’appliquer des traitements, génériques ou dédiés à cette tâche, reposant souvent sur des approches issues du TAL, pour analyser plus en détail ces passages. C’est ainsi que les modules TAL utilisés permettent un typage de la réponse attendue lors de l’analyse des questions, la reconnaissance d’entités nommées correspondant aux types de réponse gérés, ainsi que la gestion de la variation linguistique entre la formulation de la question et la formulation de la réponse dans les documents.
4. Descriptif général d'un système de question-réponse
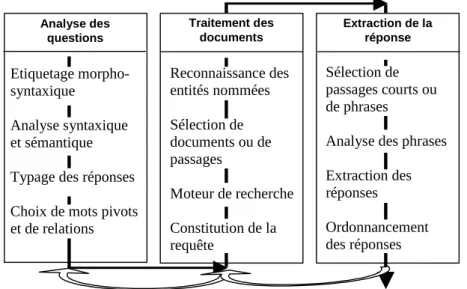
Les systèmes de question-réponse comportent de nombreux processus. Cette section vise une présentation générale de ces processus, de manière à donner une vision globale d'un système. Il est bien entendu que leur nombre, leur mise en œuvre ainsi que leur agencement dans une architecture globale seront différents d'un système à l'autre. On peut cependant dégager trois modules principaux (figure 2), toujours présents même si leur contenu varie : l'analyse des questions, la recherche et l'étiquetage des documents et enfin l'extraction de la réponse.
Traitement des documents Extraction de la réponse Reconnaissance des entités nommées Sélection de documents ou de passages Moteur de recherche Constitution de la requête Sélection de passages courts ou de phrases
Analyse des phrases Extraction des réponses Ordonnancement des réponses Analyse des questions Etiquetage morpho-syntaxique Analyse syntaxique et sémantique Typage des réponses Choix de mots pivots et de relations
Figure 2. Schéma général d’un système de question réponse
Généralement les systèmes suivent une architecture pipe-line, mais on trouve aussi des architectures en cycle ([MOL 00], [HAR 01], [MAG 02]) qui permettent
d'appliquer des stratégies différentes selon les résultats partiels ou finaux obtenus, et non selon des critères définis a priori.
L'analyse des questions vise à extraire des informations permettant la constitution des requêtes et la caractérisation des réponses cherchées. Le module documents, outre la recherche dans la collection, enrichit les documents retenus, typiquement par l'étiquetage des entités nommées. Enfin, la dernière étape consiste à extraire la réponse, qu'il s'agisse d'une chaîne de caractères de taille limitée ou bien uniquement des termes de la réponse, et à en fournir une évaluation ou une justification. Nous allons présenter ces différents modules dans les sections suivantes, en détaillant plus particulièrement leur réalisation dans QALC, le système développé dans le groupe LIR au LIMSI ([FER 01], [FER 02a], [FER 02b], [CHA 03], [BER 03]). Beaucoup d'exemples seront en anglais, essentiellement lorsqu'il s'agira de mettre en relation des questions et des extraits de corpus, ceux-ci étant extraits des corpus de TREC.
5. Analyse des questions
L'analyse des questions vise à déduire le plus d'informations possibles concernant le besoin utilisateur, notamment en caractérisant le type d'information cherchée. En l'absence de contexte, la détection de ce type d'information ne dépend que de la formulation de la question. C'est aussi de cette analyse que l'on extrait différents critères permettant le repérage de la réponse, par exemple les mots importants et les relations entre eux que l'on pourra retrouver dans les phrases réponses. Il s'agira plus généralement de retenir les caractéristiques et contraintes qui permettent de déduire la formulation de la réponse en fonction de la formulation de la question et d'extraire uniquement la réponse des passages candidats. Quelle que soit l'approche choisie, l'analyse minimale consiste à déduire de la question le type de réponse attendue. On rejoint ici le modèle de Lehnert [LEH 77], avec des adaptations en ce qui concerne les catégories de questions. Le type de réponse attendue correspond moins à une catégorie conceptuelle assez large et plus à un type de réponse directement identifiable dans les textes ou vérifiable dans une base de connaissances, souvent WordNet ou une base qui en est dérivée. Ainsi, Prager et al [PRA 00] ont défini 50 types de réponses, le système Webclopedia [HOV 01] en recense 122, appelées qtargets, reconnues par un ensemble de règles ou de patrons, constituées de noms d'entités nommées classiques et de catégories sémantiques venant d'une base de connaissances. Une classification très large est encore plus développée dans [HAR 00] qui s'appuie essentiellement sur WordNet. Ittycheriah et al [ITT 01] utilisent quant à eux une approche statistique pour typer les réponses (31 types divisés en 5 grandes classes), mais leurs performances restent limitées (56%
des questions étiquetées, soit 280 sur 500), et une écriture manuelle de règles reste la meilleure solution.
Au delà de ce typage, les systèmes extraient des caractéristiques comme les mots clés, des traits linguistiques correspondant à des relations syntaxiques devant être trouvées ou vérifiées dans la phrase réponse, dérivent des synonymes ou conservent l'analyse syntaxique complète ou une représentation sémantique (voir section 6).
Dans QALC, les caractéristiques extraites de la question sont utilisées dans différents modules. Le typage de la question concerne premièrement des types d'entités nommées classiques (figure 3); seuls sont détaillées les entités numériques en typant les différentes mesures (vitesse, montant financier, quantité physique, pourcentage, etc.) et les différents types de date (date comportant l'année, date ne donnant que le jour de l'année ou le mois, etc.). Pour des types correspondant à des classes sémantiques (ex. animal, fleur, etc.), celui-ci est considéré comme le type général de la question, et ne sera pas utilisée de la même manière, dans la mesure où les textes ne seront pas étiquetés préalablement à la sélection de la réponse. Il joue un rôle pour la validation sémantique de la réponse.
Figure 3. Hiérarchie des entités nommées de QALC
Une autre caractéristique concerne le focus de la question, défini dans QALC de manière légèrement différente de la plupart des systèmes (QUALM [LEH 77], LASSO [MOL 99]) qui considèrent que le focus d'une question est le concept recherché et représenté par le type de réponse. Pour QALC le focus est l'élément de la question sur lequel porte la question, et désigne l'entité à propos de laquelle une information doit être donnée. Comme dans [ITT 01], il constitue un point d'ancrage qui permet de trouver la réponse dans la mesure où la formulation de celle-ci reprendra souvent ce terme (ou un équivalent). Enfin, la dernière information retenue concerne le type de la question qui correspond à une forme syntaxique générique destinée à catégoriser les types de formulations possibles des réponses, vues dans QALC comme des reformulations partielles à l'affirmative des questions. Pour les trouver, QALC utilise des connaissances syntaxiques et sémantiques. Les informations syntaxiques sont fournies par un analyseur syntaxique robuste [AIT 97]
qui renvoie une segmentation en groupes ainsi qu’un ensemble de relations syntaxiques entre ces groupes. Les règles pour trouver le focus, le type de la question et le type attendu de la réponse ont été écrites à partir de ces représentations syntaxiques. Les connaissances sémantiques, proviennent de WordNet [FEL 98], et permettent de compléter les lexiques correspondant à chaque type d'entité nommée afin d'améliorer la détermination du type attendu de la réponse.
5.1. Le type attendu de la réponse
Dans un premier temps, le module d'analyse essaie de trouver si le type attendu de la réponse correspond à une ou plusieurs entités nommées classées par ordre de préférence. Les règles de reconnaissance utilisent essentiellement le type de l’interrogatif et l’appartenance du nom sur lequel il porte à l’une des listes constituées pour chaque catégorie.
Exemple : Question : What female leader succeeded Ferdinand Marcos as president of the Philippines?
(Quelle femme a succédé à Ferdinand Marcos en tant que présidente des Philippines ?)
Type attendu EN de la réponse = {PERSONNE}
Ensuite, si le type de la réponse n’est pas une entité nommée, QALC essaiera de déterminer un type sémantique plus général correspondant au nom sur lequel porte l’interrogatif si ce nom est une entrée de WordNet.
Exemple : Question : What is the name of the volcano that destroyed the ancient city of Pompeii?
(Quel volcan a détruit la ville de Pompéi ?) Type attendu général de la réponse = volcan
5.2. Le focus de la question
Pour chaque question, QALC détermine le focus, ainsi que ses modifieurs (adjectif, complément du nom) qui interviendront également dans la recherche de la réponse. Les règles déterminant le focus dépendent essentiellement de la forme de la question, et celui-ci correspond souvent au sujet, sauf en cas de présence de mots caractérisant des catégories abstraites.
Exemple : Question: What is the chemical formula for sulphur dioxide? (Quelle est la formule chimique du dioxyde de soufre ?) Groupe nominal du focus = sulphur dioxide
Focus = dioxide
Modifieurs du focus = COMP sulphur
5.3. Le type de question
La détection de la catégorie de la question permet de différencier les patrons syntaxiques d’extraction à appliquer aux phrases candidates à la réponse. La catégorie de la question correspond à la forme syntaxique de la question, plus ou moins détaillée.
Exemples : Question: What do bats eat? (Que mangent les chauves-souris ?)
Catégorie de la question = What-Do-GN-VB5
Question: When was Rosa Park born? (Quand Rosa Park est-elle née ?)
Catégorie de la question = When-Be-NP-born
6. Traitement des documents
La recherche des documents peut être une recherche classique, mais souvent les systèmes effectuent une recherche de passages. En effet, comme on désire trouver une réponse précise, le niveau document n'est pas pertinent, et un critère de sélection toujours utilisé pour localiser une réponse consiste à privilégier les passages où les mots de la question sont le plus dense. De plus, la sélection d'unités réduites permet d'appliquer ensuite des traitements assez coûteux comme l'analyse syntaxique de phrase. Pour effectuer cette recherche, les moteurs booléens sont très largement utilisés; lorsque l'on cherche à localiser précisément une réponse, il semble plus efficace de mettre en œuvre une stratégie de recherche selon des critères précis et maîtrisés. Par exemple, Magnini et al. [MAG 02b] constituent une requête à partir des mots de la question, de leurs synonymes après désambiguïsation, et effectuent la recherche à l'aide d'un moteur booléen, MG6 [WIT 99], sur la collection découpée en
paragraphes de 20 lignes maximum. La recherche est effectuée itérativement avec simplification de la requête jusqu'à obtenir 150 paragraphes candidat. Dans QALC, les documents de la collection ont aussi été découpés en paragraphes, de 20 lignes approximativement, avec un chevauchement pour éviter des coupures au milieu d'un segment homogène. Ces paragraphes ont ensuite été indexés par MG. La stratégie appliquée ensuite diffère puisque le principe est d'effectuer une interrogation ramenant beaucoup de documents à partir d'une requête de base, sans expansion,
5 GN signifie groupe nominal, VB signifie verbe, et NP, nom propre. 6 http://www.cs.mu.oz.au/mg/
puis de sélectionner sur des critères plus fins par la suite. QALC construit sa requête en se fondant uniquement sur les mots de la question et en leur appliquant du stemming. De ce fait, il retient un grand nombre de paragraphes (1000), et ceux-ci sont ensuite réindéxés par Fastr [JAC 99] [JAC 01] qui y recherche les termes simples et composés de la question sous leur forme d'origine ou avec des variations [FER 01], [FER 02a]. Ces variations prennent en compte des variations sur les groupes nominaux de type morphologique (passage du nom au verbe par exemple), syntaxique (insertion d'adjectifs par exemple) et sémantique (les synonymes). Ittycheriah et a. [ITT 01] ont testé différentes interrogations, avec et sans expansion de requête, et leurs résultats sont meilleurs quand ils appliquent les mécanismes d'expansion comme critères de sélection de la réponse dans les documents retrouvés par le moteur plutôt que donner au moteur des requêtes étendues.
La partie sélection de passages joue un rôle important et les critères semblent être les mêmes dans tous les systèmes, leur combinaison différant ensuite. Il en ressort les critères suivants ([CHA 03], [MAG 02], [ITT 01]):
– le nombre de mots pleins de la question, généralement pondérés que ce soit de manière absolue selon leur degré de spécificité dans la langue ou selon le rôle qu'ils sont censés jouer dans la réponse (le focus par exemple);
– des extensions de ces mots, par leurs synonymes ou des mots de la même famille morphologique, de manière à essayer de couvrir toutes les formulations du concept sous-jacent que l'on peut trouver dans une réponse;
– l'entité nommée cherchée;
– la proximité des mots repérés dans le passage.
Ces critères peuvent être appliqués quelle que soit la longueur du passage visé. Ce dernier peut aller de plusieurs phrases à une seule, la sélection sur une phrase étant généralement faite dans un deuxième temps. Une sélection en deux temps vise à ne travailler que sur un contexte pertinent lors de l'extraction elle-même. Il est à noter que l'utilisation de la présence de l'entité nommée cherchée, quand un type de réponse a été déduit de la question, sert souvent de critère absolu et entraîne l'élimination de passages.
On peut cependant distinguer les stratégies d'interrogation du Web vs la collection de référence, notamment en ce qui concerne la constitution de la requête. Dans le cadre de l’évaluation TREC, de nombreux participants se sont appuyés sur le Web afin de trouver des réponses, mais aussi afin de confirmer ou d’évaluer les réponses de leur système. Brill et al. [BRI 01] ont uniquement interrogé le Web privilégiant le fait qu'une réponse à plus de chance d'être trouvée sur le Web car elle y figurera en plus grand nombre que dans une collection plus limitée, même de taille importante. Clarke et al. [CLA 01] sélectionnent 40 passages parmi les 200 premiers documents retournés par deux moteurs standard du Web et 20 passages du corpus de
référence, dans lesquels la réponse est extraite, à condition qu’elle appartienne à la base de référence. Le Web est ici utilisé pour augmenter le facteur de redondance des réponses candidates. Cette approche leur a permis d'améliorer leurs résultats de 25 à 30%.
6.1. Interrogation Web
Les systèmes opérant une interrogation du Web ont effectué une réécriture spécifique des questions. Devant la grande redondance des informations présentes sur le Web, il est admis qu'il est possible de trouver des documents pertinents même avec une requête très spécifique et qu'une telle requête permet d'obtenir les documents susceptibles de contenir la réponse classée dans les premières positions. Ainsi, Brill et al. [BRI 01] gardent les mots de la question dans leur ordre original et déplacent les verbes dans toutes les positions possibles. Le moteur effectue une comparaison entre chaînes de caractères. Hermjacob et al. [HER 02] engendrent des variantes de la question en utilisant des règles de paraphrases syntaxiques et sémantiques. Ces paraphrases sont utilisées pour former des requêtes booléennes (3 paraphrases par question en moyenne) afin d'interroger le Web.
Dans QALC, les questions sont reformulées sous une forme affirmative avec aussi peu de variations que possible par rapport à la formulation d'origine. Par exemple, pour la question « Quand Wendy's a-t-elle été fondée ? », il est censé exister un document contenant la réponse sous la forme : « Wendy's a été fondée le... ». QALC recherche donc d'abord sur le Web les chaînes exactes fournies par la reformulation, comme dans [BRI 01] et non pas les différents mots de la requête reliés par des opérateurs AND, OR ou NEAR comme dans [MAG 02b] ou [HER 02]. QALC ne sélectionne qu’un nombre réduit de documents, 20 dans les expériences effectuées [BER 03].
La réécriture des questions utilise des schémas de reformulation. Les questions sont classées en fonction du type de la réponse attendu et du type de la question. Rechercher un nom de personne ou bien un lieu ne mènera pas à la même reformulation, même si les deux questions sont syntaxiquement similaires. “Qui est le gouverneur de l'Alaska ?” et “Où est la tour du diable ?” n'attendent pas des réponses formulées exactement de la même manière : la requête “, gouverneur de l'Alaska” fonctionne pour la première question puisqu’un nom est souvent donné en apposition, tandis que “La tour du diable est située” est une requête possible pour la seconde. Ces reformulations ont été préalablement essayées manuellement sur le Web avec Google pour pouvoir trouver les types de schémas les plus fréquemment couronnés de succès, pour environ 50 questions et leurs réponses. Ces tests ont montré la nécessité de définir un critère supplémentaire pour obtenir une réécriture suffisamment précise : il s'agit ou bien d'un mot introduisant un modifieur dans la
forme minimale de la question ou bien d'un mot de la question qui entraîne l'ajout d'un mot (souvent une préposition ou un verbe) qui introduit de façon spécifique l'information recherchée dans la forme affirmative. Par exemple, le mot « quand » introduisant un modifieur est conservé et la présence du mot « année » dans une question portant sur une date cause l'ajout de la préposition « en » à la forme affirmative.
QALC associe un ou plusieurs schémas à chaque type de question, les schémas supplémentaires correspondant souvent au relâchement de contraintes par rapport au schéma primitif. Un schéma de réécriture est construit en fonction des caractéristiques syntaxiques de la question : le focus, le verbe principal, les modifieurs et éventuellement les relations introduisant des modifieurs du verbe ou de l'objet. La réécriture la plus simple est construite avec tous les mots de la question à l'exception du pronom interrogatif et de l'auxiliaire, comme pour les questions du type « WhatBe ».
Par exemple, la question « Quand est né Lyndon B. Johnson ? » se réécrit en : « Lyndon B. Johnson est né le », en appliquant le schéma de réécriture « <focus> <verbe principal> né le ». Google trouve avec cette requête, et en première position, la réponse « Lyndon B. Johnson est né le 27 août 1908 ». Pour éviter d'être trop restrictif, les requêtes sont soumises à Google avec et sans guillemets (recherche de la chaîne exacte ou avec seulement l'ensemble des mots).
L'évaluation de ce module a été réalisée en recherchant les patrons des bonnes réponses aux questions de TREC11 dans les 20 premiers documents renvoyés par Google. 372 questions peuvent être résolues, ce qui représente 74,4% des réponses. Parmi ces questions, 360 fournissent plus d'un document pertinent.
6.2. Etiquetage des documents par les entités nommées
Les entités nommées constituent des indices précieux lors de la recherche d’une phrase contenant la réponse et sont véritablement très importantes lorsque l’on veut ne sélectionner que le groupe de mots formant la réponse. Les types retenus dans QALC sont définis de manière similaire à ce qui a été fait dans les évaluations MUC [GRI 95] et sont reconnus à partir d’une combinaison de :
– consultations de lexiques (pour trouver des traits syntaxiques et sémantiques associés aux mots simples) et de règles exploitant ces traits en complément de traits lexicaux, et
– recherches dans des dictionnaires d’entités nommées.
Nous ne détaillerons pas ce processus ici, celui-ci n'étant guère différent de ce qui s'est fait dans MUC. Signalons cependant que de nombreux systèmes ont établi
une catégorisation spécifique à la tâche question-réponse et cherchent à reconnaître des entités telles que le code postal, les titres d'œuvre, c'est-à-dire des types spécifiques figurant souvent dans les questions de TREC. En allant plus loin, il est intéressant de constituer des bases de données par extraction de ce type de connaissances à partir de textes afin de répondre rapidement à des questions. Cette approche a été notamment développée par [BEL 02] et [CLA 02].
7. Extraction de la réponse
On considèrera ici le problème du repérage de la réponse dans un court passage, généralement une phrase, et de la délimitation de l'ensemble des mots qui constitue la réponse. Cette partie demeure le point le plus délicat, surtout lorsqu'il ne s'agit pas d'une réponse de type entité nommée.
En effet, lorsqu'il est possible de repérer le type cherché dans les textes, indépendamment de la question posée, ce qui est le cas pour les entités nommées, le repérage et la délimitation des réponses potentielles sont déjà réalisés. Le choix final résulte en général d'un calcul de poids analogue à ce qui a été présenté dans la section précédente. Il reste néanmoins à sélectionner la réponse en cas de présence de plusieurs entités de même type dans la phrase, ce qui se fait souvent par l'application d'heuristiques portant sur la distance entre la réponse et un mot de la phrase ou l'ensemble des mots de la phrase, comme c'est fait dans QALC. Même si beaucoup de systèmes ont privilégié cette stratégie, certains ne différencient pas les techniques utilisées selon ce critère et appliquent la même approche pour tous les types de réponse ([MOL 02], [SOU 01]), approche présentée ci-dessous.
Dans le second cas, il faudra être capable d'associer à une question des formulations de ses réponses. C'est ici que les informations tirées de la question jouent un grand rôle. On peut savoir que l'on recherche une réponse dont on connaît éventuellement l'hyperonyme, comme c'est le cas pour les questions demandant «Quel X ...?» ou «Quel est X ...?», par exemple «Quel animal est le plus rapide à la course ?», ou «Quelle est la monnaie de la Chine?». Ou alors, on catégorise le type d'information demandé comme c'est le cas pour les définitions, les explications, les causes ou, plus spécifiquement, les raisons d'être célèbre par exemple (catégorie WHYFAMOUS chez Hovy [HOV 01]). Et il reste toujours un type générique tel que «GN» lorsqu'on ne sait pas qualifier précisément la réponse. Ce typage, très différent d'une approche à l'autre, permet de définir la formulation des caractéristiques cherchées alors que le type de la question permettait à Lehnert [LEH 77] de choisir la stratégie à développer pour fournir une réponse. On retrouve cette catégorisation permettant de relier le type d'information, à propos d'une entité, que doit fournir le système, à une caractérisation de la réponse dans les travaux sur la génération. Par exemple, McKeown [McK 85] définissait cinq manières de donner une définition à
partir de l'étude des textes figurant dans des encyclopédies et des dictionnaires: a) donner l'hyperonyme de l'objet b) donner les constituants de l'objet (les méréonymes) c) donner les caractéristiques de l'entité d) utiliser une analogie et e) donner un exemple. Bien que les réalisations dans les deux domaines soient très différentes, le principe qui les sous-tend reste identique. On s'aperçoit cependant que plus on utilise des techniques d'analyse de surface, plus il est nécessaire de typer finement l'information cherchée et ses formulations possibles. En effet, il s'agira d'envisager toutes les variations possibles :
– les variations sémantiques avec l'utilisation de synonymes, d’hyperonymes ou d'hyponymes entre mots de la question et de la réponse.
Utilisation d’un hyponyme dans la phrase réponse : What was the name of the dog in the Thin Man movies?
Réponse : The Thin Man (1934): <REP> Asta </REP>, the wire haired terrier …
Utilisation d’un hyperonyme dans la phrase réponse : What is the name of the canopy at a Jewish wedding?
Réponse : … was planning a full Jewish ceremony, complete with the traditional <REP> huppah </REP> canopy, …
– variations morphologiques avec le passage d'un nom au verbe ou inversement, ou le passage d'un nom de pays à l'adjectif
Who won the Nobel Prize in 1992 ?
Réponse : <REP> Menchu </REP>, the winner of the 1992 Nobel Prize – variation syntaxiques
– des combinaisons de ces variations
What is the legal age to vote in Argentina ?
Réponse : Voting is mandatory for all Argentines aged over <REP> 18 </REP>.
Ici, il y utilisation de termes sémantiquement liés (legal et mandatory), de variation morphologique (age comme nom et aged comme verbe), et variation syntaxique (la réponse ne correspond pas à une reformulation sous forme déclarative).
La gestion de ces variations va de la définition de patrons, plus ou moins nombreux et plus ou moins figés, qui permettent de décrire des règles locales s'appliquant sur les phrases ([SOU 01], QALC [FER 02a]) à l'appariement entre les représentations syntaxiques de la question et de la phrase candidate [BUC 01], [LIN 01] ou entre les représentations sémantiques de ces deux entités [MOL 02b].
7.1. Application de patrons d'extractions
La définition de patrons conduit à la production de formules plus ou moins flexibles et génériques. On retrouve ici les approches qui ont été appliquées en extraction d'information. Soit on donne au système les expressions régulières visant à décrire toutes les expressions d'une information, et cette technique est très liée à l'application et à l'exhaustivité dans l'explicitation de ces types d'information, soit on essaie de mettre en œuvre une approche plus générique avec une catégorisation de l'information à trouver fondée sur des critères indépendants de l'application et propres à la langue. La première approche a été appliquée avec succès par Soubbotin et Soubbotin, [SOU 01], [SOU 02]. Par exemple, lorsque l'on recherche une information sur une personne, il est prévu de rechercher des postes ou des fonctions, et les expressions régulières codent les formulations de ce type d'information. Autre exemple, si l'on cherche une capitale, le patron suivant s'appliquera «City name; comma; country name», quelle que soit la thématique du texte. Il en sera de même pour la recherche de définitions, etc. Afin de contraindre l'application de ces patrons, des mots amenant à nier cette information sont recherchés dans le voisinage immédiat. Ensuite, les réponses choisies seront celles qui seront proches des mots de la phrase. Le système trouve 271 réponses sur 500 à TREC 11 (2002) et deux tiers des 289 réponses correctes de TREC 10 (2002) sont obtenues par des patrons. Cette approche présuppose que l'on est capable de connaître et de décrire tous les types d'information recherchée.
Lin et Pantel [LIN 01] se sont centrés sur l’étude de paraphrases verbales afin de trouver la similarité entre la formulation sous forme affirmative de la question et des paraphrases possibles dans des textes. Par exemple, il est important de reconnaître que «X wrote Y » est proche de «X is the author of Y». A cette fin, leur système extrait des chemins des arbres de dépendances construits par un analyseur syntaxique, Minipar [BER 91], où seule l'analyse la plus probable est gardée, et évalue leur similarité. Un chemin est constitué d'une suite de relations syntaxiques entre deux catégories de mot, et de slots à chaque extrémité remplis par des mots. Par exemple «X wrote Y» est représenté par «N:subj:V – write – V:obj:N». Deux chemins seront similaires si ils partagent les mêmes contextes dans un corpus, c'est-à-dire si on retrouve en général les mêmes paires de mots (X, Y) dans l'utilisation des expressions représentées par les chemins. Ce type d'approche contribue à l'apprentissage de patrons d'extractions.
La méthode d'extraction de QALC est aussi fondée sur l'utilisation de patrons, mais QALC y a recours seulement lorsque le type attendu n'est pas une entité nommée. Ces patrons sont issus de l'étude de questions et leurs réponses, classées par catégories de questions : le but était d'associer à des types de questions, définies sur des critères syntaxiques, des types de formulations des réponses reposant sur la formulation de la question. En d'autres termes, le but est de produire la réécriture
partielle d'une question sous forme affirmative, considérant que c'est un moyen direct de formuler une réponse. Même s’il existe une forme plus fréquente que les autres, on ne peut présumer de son emploi, surtout si la base de documents reste limitées, et il est aussi nécessaire de prévoir les variations possibles de cette formulation. L'exemple le plus immédiat concerne les modes d'expression des définitions, qui se trouvent modélisés de manière analogue dans pratiquement tous les systèmes.
Cette technique est aussi appliquée lorsque l'on recherche d'autres types d'informations que des définitions, qui ne reçoivent pas une étiquette sémantique dans QALC, mais qui sont caractérisés par leur expression en langue. Comme la syntaxe d'une question est fonction du type d'information cherchée, les patrons d'extraction sont exprimés en partie en fonction d'éléments de la question et reprennent au minimum le focus de celle-ci. Ce dernier constitue un point d'ancrage lors de l'application du patron. Quand plusieurs formes syntaxiques permettent de demander le même type d'information, les mêmes patrons leur seront associés.
Ainsi, une caractéristique, comme dans «What are Brazil's national colors? «, peut être exprimée par une apposition, «yellow and green, the Brazil's colors» ou «in a yellow and green (Brazil's colors) ...» ou «the National Colors of Brazil (green and yellow)» ou une forme affirmative directe, «the national colors of Brazil are yellow and green», ou un complément du nom avec «the yellow and green Brazil's national colors». Si la question porte sur l'un des arguments du verbe, comme dans «What does Peugeot manufacture?», la réponse pourra être exprimée par «Peugeot manufactures cars», ou l'une de ses variations, comme «cars, produced by Peugeot «. L'analyse de la question et des termes utilisés montre toute son importance ici, dans la mesure ou une fausse détection du focus entraîne l'inapplicabilité des patrons. Par exemple, dans «What nationality is Sean Connery?», le focus reconnu dans QALC est Sean Connery et non nationality, terme trop abstrait qui de fait ne figure pas dans les réponses; en revanche, nationality permet de typer la réponse. Les patrons vont décrire ces variantes syntaxiques, alors que la variation terminologique autour de l'expression du focus sera gérée lors de la recherche du groupe nominal correspondant au focus, dans la phrase candidate. L'étude de ces variations se rapproche des études réalisées sur la variation terminologique [BOU 01].
Voici quelques exemples de réponses extraites de phrases, encadrées par la balise <REP>, et de variations sur le groupe nominal focus, souligné dans les exemples:
What is Ronald Reagan's favorite candy? Focus: candy
In 1980, presidential candidate Ronald Reagan gave the company better marketing than money could buy by naming the <REP> Jelly Belly </REP> his favorite confection .
What is the name of Scarlett O'Hara's house? Focus: house
Zinn may sound a bit like Scarlett O'Hara surveying <REP> Tara </REP> though in the current housing market
Ici, il faut relier surveying à house.
What is the chemical formula for sulphur dioxide? Focus: dioxyde
The concentration of sulphur dioxide (<REP> SO2 </REP>) and carbon dioxide ( CO2 ) measured
What is the currency used in China? Focus: currency
and China's currency <REP> RMB </REP> is playing a more
L'apposition n'est pas toujours aisément reconnaissable, et est souvent considérée comme partie intégrante du groupe nominal qui la précède. What roller coaster is the fastest in the world? Focus: world
Cedar Point will introduce still another coaster ,<REP> Millennium Force </REP>, which this year will become the tallest and fastest roller coaster in the world .
Exemple d'erreur dans QALC. Se tromper sur le point d'ancrage empêchera l'application du patron et l'extraction de la réponse.
Les patrons dans QALC sont composés de deux groupes nominaux, l'un désignant le groupe nominal qui réfère au focus et l'autre la réponse, et sont liés par des éléments qui sont constitués soit de séparateurs répertoriés au cours de l'étude du corpus (des parenthèses, des locutions du type «such as», des mots spécifiques comme «or»), soit de mots de la question comme le verbe principal. Ces éléments représentent les divers moyens d'exprimer en langue la relation existante entre le focus et la réponse.
Exemples de patrons: GNfocus VB GNréponse, GNRéponse, such as GNFocus GNFocus (GNReponse)
Les formes syntaxiques codées dans les patrons correspondent à la formulation d'incises, d'appositions, de relatives, de complément de noms et de formes déclaratives. On rend compte aussi, selon le patron et l'ordre des deux groupes, de formes affirmatives ou passives quand le verbe fait partie du patron. Des termes introducteurs permettent de spécifier la présence de ces formes dans une phrase. QALC répertorie 74 patrons différents, dont les différences proviennent beaucoup de l'ensemble des introducteurs admis pour les différents types de question, ceux-ci étant de l'ordre d'une vingtaine.
L'application des patrons dans QALC requiert donc la présence dans la phrase candidate d'un groupe nominal similaire au focus. Cette similarité vise à rendre compte des variations du groupe nominal focus. Le critère permettant de sélectionner un groupe nominal est la présence du mot tête du groupe nominal focus de la question (désignant le focus lui-même) ou d'un synonyme. Ensuite la présence de modifieurs analogues à ceux de la question viennent renforcer le repérage du focus dans la phrase, et plus un groupe nominal sera proche du groupe nominal de la question, mieux la phrase sera considérée. Le fait de travailler sur les constituants des phrases permet d'être plus précis lors de l'appariement, et de favoriser les rapprochements question-phrase lors de la présence de constituants proches.
Ci-dessous des exemples de repérage du groupe nominal le plus similaire au groupe nominal focus de la question, les éléments qui s'apparient sont soulignés dans les phrases.
What was the first satellite in space?
The Soviet Union launched the first space satellite ,<REP> Sputnik </REP>I , on Oct. 4 , 1957 .
Where is Hill Air Force Base?
… a group of F 16s from Hill Air Force Base in <REP> Utah </REP> … What is the name of the US military base in Cuba?
… called on the U.S. government to return the <REP> Guantanamo </REP> military base to Cuba …
Les patrons associés à la catégorie de la question traitée sont appliqués dans un ordre de fiabilité déterminé a priori, et permettent de pondérer la réponse extraite. Comme cela est indiqué dans Soubbotin [SOU 01], plus un patron est spécifique, plus il est fiable.
Les résultats obtenus par QALC lors de l’évaluation TREC10 [FER 02b] montrent l’intérêt de l’approche. Le système a extrait 61% de réponses grâce à l’utilisation des patterns, lorsqu’il disposait de la phrase contenant la réponse dans les 10 premières positions, ce qui correspond à 24% des réponses trouvées ainsi contre 11,5% dans la version précédente qui utilisait seulement des critères de proximité. L'amélioration entre les deux versions est aussi due à un meilleur étiquetage des types attendus en terme d'entités nommées.
Tableau 1. Résultats obtenus par QALC
Pour TREC11, où il s'agissait de ne produire qu'une réponse par question, et seulement la réponse, contre cinq courts passages auparavant, le nombre de questions résolues reste stable.
Il est à noter que ces patrons ne sont pas suffisamment contraints pour permettre seuls l'extraction de la bonne réponse. Outre les contraintes sur la sélection des phrases, des vérifications sémantiques sont à effectuer quand on connaît le type de la réponse. Par exemple, lorsque l'on cherche une couleur, cette caractéristique constitue le type de réponse attendue, et une fois la réponse extraite, il y a validation possible via l'utilisation d'une base de connaissances, WordNet en général. Par ailleurs, cette technique s'applique mieux au Web, où les variations d'expressions plus nombreuses entraînent plus souvent une application réussie des patrons.
Une autre manière de valider une réponse, qui est largement utilisée car elle ne nécessite pas de processus ou de connaissances élaborées, consiste à rechercher la réponse sur le Web, et à se fonder sur le fait que la réponse existe dans deux bases de documents différentes ou bien sur son taux de redondance. En utilisant la première technique, QALC a validé de nombreuses réponses ce qui l'a conduit à une bonne estimation de la fiabilité de ses résultats [CHA 03].
7.2. Appariement de représentations syntaxiques ou sémantiques
Les solutions présentées précédemment peuvent être vues comme des appariements question-phrase, avec une relaxation forte de certaines contraintes. Si l'on considère la question complète, avec les relations syntaxiques ou sémantiques existant entre ses concepts, les stratégies précédentes cherchent à vérifier certaines de ces relations, généralement de manière implicite et en travaillant à partir de la suite de mots, lemmatisés ou non, ou à partir d’un découpage en groupes, sinon elles sont approchées par une notion de distance. Quelques travaux portent néanmoins sur des appariements plus stricts entre les deux entités, question et phrase réponse, et sont fondés sur une analyse syntaxique des phrases.
Nombre de questions Nombre de réponses correctes
(50 caractères) TREC 9 682 183 (27%) TREC 10 492 144 (29,3 %) TREC 11 500 133 (26,6%) TREC 9 – nonEN 297 34 (11,5%) TREC 10 – nonEN 263 62 (24 %)
Les travaux les plus poussés et les plus aboutis sont ceux de Moldovan et Harabagiu [MOL 02], [MOL 02b]. La dernière version de leur système construit des représentations sous forme logique pour chaque phrase des paragraphes sélectionnés ainsi que pour la question. Ce processus est fondé sur une analyse syntaxique, dans laquelle les ambiguïtés syntaxiques et structurelles sont levées. Toutes les règles de grammaires de l’anglais ne sont pas implémentées, seules les plus fréquentes qui couvrent 90% des cas le sont. L’appariement entre une question et une phrase consiste à prouver une formule logique constituée des axiomes provenant de la phrase candidate, de la question niée pour effectuer une preuve par l’absurde, d’axiomes permettant de relier des informations entre elles (les entités nommées et les types de réponse, les possessifs, etc.). Par ailleurs, le démonstrateur utilise si nécessaire des chaînes d’inférences reliant des synsets de WordNet construites à partir des relations standard de WordNet et des définitions en anglais liées aux synsets qui ont été traduites aussi sous formes logiques. Une réponse proposée à l’issue de ce mécanisme se trouve aussi être justifiée. Le système PowerAnswer a trouvé 415 réponses sur 500 à l’évaluation TREC11, et l’utilisation du prouveur repose sur l’utilisation des différentes relations entre mots, mais aussi conduit à la réalisation d’inférences pour démontrer un résultat.
D'autres travaux se sont situés à un niveau syntaxique uniquement. Buchholz [BUC 01] procède à une décomposition en syntagme, puis recherche les relations syntaxiques reliant les syntagmes au verbe. Dès qu’une phrase ne possède pas une relation requise par la question, elle est éliminée. Les relations de la question doivent être retrouvées dans la phrase candidate, et agissent à la fois pour sélectionner des phrases et pour extraire la réponse qui est le syntagme possédant la relation identifiée dans la question par rapport au verbe. Leurs évaluations montrent qu’ils retrouvent plus de réponses en utilisant seulement le niveau des syntagmes par rapport à l’utilisation de relations, mais dans ce dernier cas la précision est meilleure. La difficulté consiste donc à produire des analyses fiables, car il est intéressant d’utiliser un appariement tenant compte des relations.
8. Evaluation
Bien que chercher à répondre à des questions ait toujours existé, c'est l'introduction d'une tâche d'évaluation dans la campagne TREC en 1999, évaluation organisée par le NIST, qui a relancé le thème, en le recentrant sur des questions tout domaine et de nature factuelle dont la réponse peut être extraite de documents [VOO 01]. Le succès que cette tâche connaît et sa complexité toujours croissante est une preuve de la vitalité des recherches effectuées. Le principe de l'évaluation consiste à poser un jeu de question aux participants, et de faire évaluer leurs soumissions par des juges humains, avec plusieurs jugements pour une même soumission. Les réponses doivent être accompagnées d'un numéro du document qui justifie la
réponse. Ainsi une réponse, exacte sur la valeur, mais qui n'est pas justifiée dans le document proposé ne sera pas comptabilisée dans les réponses correctes.
TREC8 (1999) proposait deux cents questions, construites de manière assez artificielle puisqu'une partie venait de propositions des vingt-six participants. Il s'agissait alors de retourner cinq extraits ordonnés de 250 caractères contenant la réponse, extrait recherché sur un corpus de 1,9 gigabytes, soit 528 000 documents. Les documents provenaient de journaux américains, avec le Los Angeles Times, le Financial Times, le FBIS et le Federal Register. Dès cette première campagne, plus de 50% des réponses ont été trouvées par les meilleurs systèmes, avec une vingtaine de participants. Dès cette première campagne la nécessité d'utiliser des programmes de traitement automatique de la langue (TAL) ainsi que des connaissances sémantiques est apparue.
La campagne TREC9, l'année suivante, proposait deux pistes aux participants, au nombre de 25 environ, l'une toujours centrée sur l'extraction de passages, l'autre demandant des réponses courtes (50 caractères). Les questions, au nombre de 700, dont 200 reformulations, étaient issues de logs fournis par des moteurs de recherche et sélectionnées par l'organisateur sur des critères de portée de la question (suffisamment générale) et conduisant à des réponses évaluables. La taille de la collection a presque doublé, puisqu'elle comportait 980 000 documents de 3 gigabytes.
TREC10 (2001) revenait à 500 questions mais complexifiait la tâche puisque seules les réponses courtes étaient autorisées, sachant que certaines questions n'avaient pas de réponses dans les documents. Beaucoup de questions portaient sur des définitions. Celles-ci ont d'ailleurs entraîné des problèmes lors de l'évaluation. En effet, les réponses peuvent être très disparates, allant de la proposition d'un concept générique à une partie seulement de la définition. En effet, à la question, «What is an atom?», ou «Who is Collin Powell?», les niveaux de réponse et leur complétude seront très différents. C'est pourquoi de telles questions ont été supprimées de TREC11 quand elles n'étaient pas suffisamment précises. Le nombre de participants s'est stabilisé autour de 35.
La difficulté de TREC11 (2002) portait sur deux points, ne donner que la chaîne de caractères constituant la réponse et non un court passage, ne donner qu'une seule réponse par question et classer les réponses selon un degré de confiance. La collection de référence a été remplacée par le corpus AQUAINT. La plupart des systèmes ont recherché des réponses sur le Web, que ce soit exclusivement ou non. Même si certains travaux utilisent des analyses fines de phrase, la majorité des systèmes arrivant en tête reposent encore beaucoup sur des critères de recherche et d'extraction visant à approcher ces analyses. Hormis le système de LCC qui obtient plus de quatre cents réponses sur cinq cents, les autres systèmes, qui diffèrent certes
dans certains de leurs modules, mais qui globalement essaient tous de marier des processus de TAL de surface, l'utilisation de connaissances sémantiques et des techniques de recherche d'information, obtiennent des résultats pouvant encore être nettement améliorés.
En parallèle à la tâche principale, une autre piste consistant à traiter des questions possédant plusieurs réponses existe depuis 2000. Un essai de questions enchaînées a eu lieu, le but étant d'aller vers une évaluation de plusieurs questions-réponses liées entre elles (une simulation de dialogue), mais a été abandonné pour l'instant.
La campagne TREC12 (2003) à réintroduit des questions de définition, en supposant un contexte défini a priori et le même pour toutes les questions, afin de limiter le nombre de réponses pertinentes, un pilote ayant été mis en place préalablement afin de mettre au point une mesure d'évaluation de réponses multiples à des questions de définition.
Les campagnes TREC ne sont pas les seuls cadres d'évaluation. Un programme américain a été lancé, le programme AQUAINT7, afin d'étudier des problèmes plus
complexes. On y retrouve des points figurant dans le «roadmap» rédigé par un ensemble de chercheurs8. Ainsi les futurs systèmes de question réponse devront
pouvoir réaliser des interprétations en contexte, de la recherche multidocuments afin de proposer une réponse complète, être multilingues et concevoir une présentation appropriée des réponses. Outre ces aspects, l'accent devra aussi être mis sur la fiabilité des réponses données et leur justification. Ce programme permet aussi d'étudier la mise en place d'évaluations pour tous ces aspects.
En Europe, la campagne CLEF9 a intégré en 2003 une piste question-réponse
multilingue, dont l'évaluation est faite de manière analogue à TREC. La différence vient des sources de documents, en langues différentes, et des questions qui sont posées dans une langue, et donner lieu à des réponses en anglais, en sus de leur langue.
9. Conclusion
L'évolution des processus mis en œuvre dans des systèmes de question-réponse est significative de l'évolution du domaine du TAL. Des premiers systèmes, opérant sur des représentations conceptuelles de haut niveau et capables de déduire des informations de leur base de connaissances mais d'un champ d'application réduit, on
7 http://www.ic-arda.org/InfoExploit/aquaint/
8 http://www-nlpir.nist.gov/projects/duc/papers/qa.Roadmap-paper_v2.doc 9 http://www.clef-campaign.org