Learning functional brain atlases modeling inter-subject variability
Texte intégral
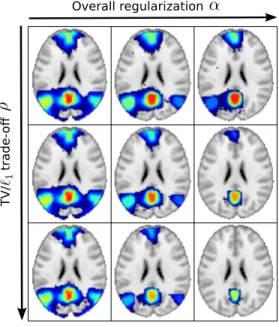
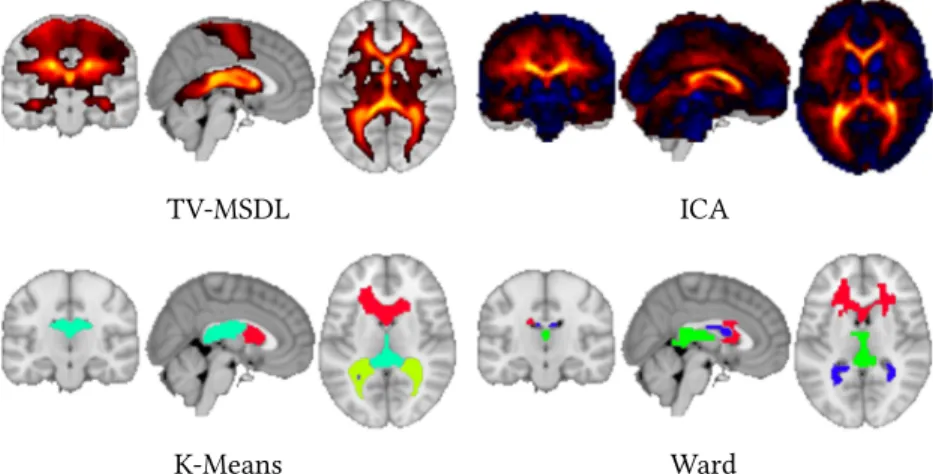
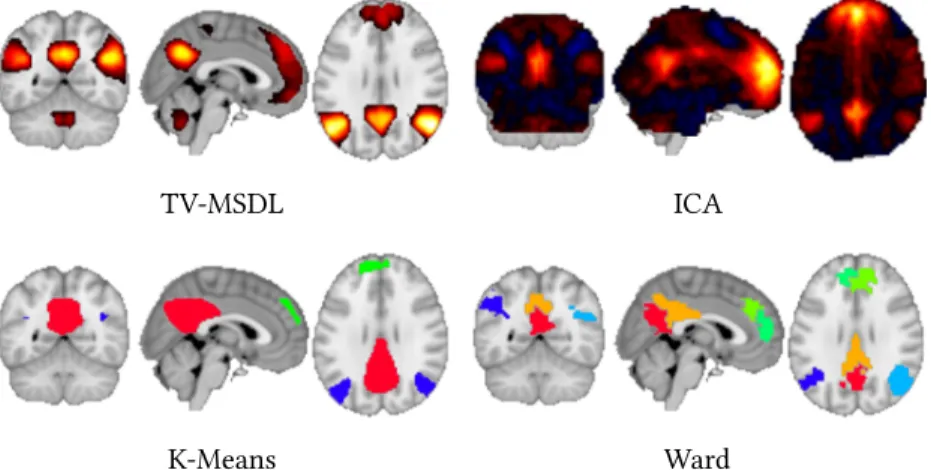
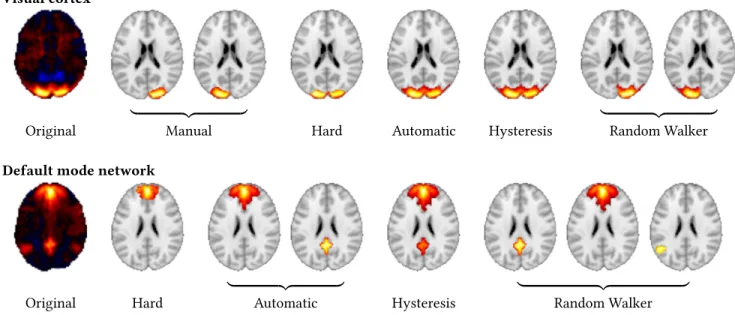
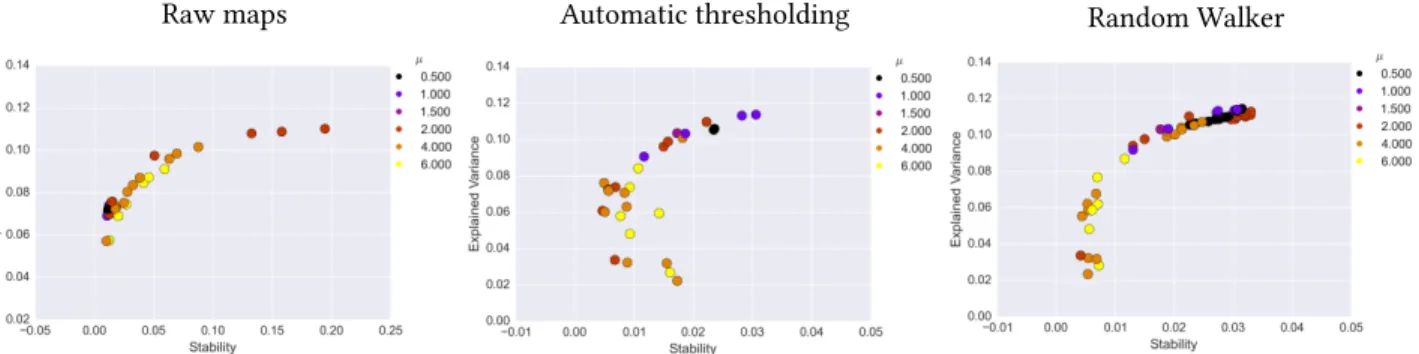
Figure





Documents relatifs
Pierrick Thoraval, Anne-Marie Chaussé, Marielle Afanassieff, Rima Zoorob, Daniel Bouret, Gaelle Luneau, Jean-Marie Alletru, Evelyne Esnault, Denis. Soubieux,
Full Load Weight/Total Enclosed Volume Structural Density Propulsion Plant Specific Weight Specific Machinery Volume Payload Density Electrical System Specific Weight Specific
Cite this article as: Minary et al.: Efficacy of a smoking cessation program in a population of adolescent smokers in vocational schools: a public health evaluative controlled
Parmi les romanciers d'Afrique noire, celui qui a poussé le plus loin cette intrusion des formes idiomatiques d'une langue locale dans son texte français est sans conteste
Once the gathering node has been unambiguously identified by a robot during its Compute operation, if the robot resides on the half grid where the south pole is, then it moves
La partie septentrionale des Rivières du Sud (fig. 1) entre le delta du Saloum et le Rio Mansôa dans le nord de la Guinée-Bissau, en passant par la Gambie et la Casamance,
In order to include all properties described in the scientific literature about gene tree species tree reconciliation, we should first be able to annotate gene tree nodes with
Nous avançons l’hypothèse selon laquelle, l’utilisation d’un PowerPoint en cours magistral assuré en français soutiendrait le discours oral de l’enseignant, c’est
