3D Echo Cancellation in a Home Environment by
Gina F. Yip
Submitted to the Department of Electrical Engineering and Computer Science in Partial Fulfillment of the Requirements for the Degree of
Master of Engineering in Electrical Engineering and Computer Science at the Massachusetts Institute of Technology
February 6, 2001
Copyright 2001 Gina F. Yip. All rights reserved.
The author hereby grants to M.I.T. permission to reproduce and distribute publicly paper and electronic copies of this thesis
and to grant others the right to do so.
Author__________________________________________________________________ Department of Electrical Engineering and Computer Science
February 6, 2001 Certified by______________________________________________________________
David L. Waring VIA Company Supervisor Telcordia Technologies Certified by______________________________________________________________
David H. Staelin Thesis Supervisor Accepted by_____________________________________________________________
3D Echo Cancellation in a Home Environment
by Gina F. Yip Submitted to the
Department of Electrical Engineering and Computer Science February 6, 2001
In Partial Fulfillment of the Requirements for the Degree of Master of Engineering in Electrical Engineering and Computer Science
ABSTRACT
This thesis describes the work done to research, implement, and compare various algorithms for the cancellation of echoes in a home environment, where the room impulse response is unknown and variable. The general problem, where the speaker’s movements are completely unrestricted, is a very hard one, and research in this area has only begun in the last several years. Therefore, this thesis addresses a simplified version of the
problem, where the impulse response of the multipath environment is assumed to be stationary within the duration of a verbal command. Given this assumption, which is reasonable for most situations, algorithms based on the complex cepstrum,
autocorrelation, and delay and sum methods of echo cancellation were chosen and developed for the study.
Many simulation tests were done to determine the behavior of the algorithms under different echo environments. The test signals were based on the simple delay and attenuation echo model with one microphone, and on a more realistic echo model, generated by the Cool Edit Pro software, with one or three microphones. The
performance metrics were the number of errors and the percent of improvement in speech recognition by Dragon Systems’ Naturally Speaking software. The results showed vast improvement for the cepstral domain methods on the simple echo signals, but the
numbers were mixed for the complex model, one microphone cases. However, with three microphones, the delay and sum algorithm showed consistent improvement. Given that research in this specific area of 3D echo cancellation in a home environment, where 3D refers to the moving speech source, is still in its early stage, the results are encouraging. VIA Company Supervisor: David L. Waring
Title: Director of Broadband Access & Premises Internetworking Group, Telcordia Technologies
Thesis Supervisor: David H. Staelin
Title: Professor of Electrical Engineering & Computer Science, Assistant Director of Lincoln Lab
Acknowledgements
Resounding thanks to my supervisor at Telcordia, Dave Waring, for being extremely supportive in providing me everything I needed to complete the project.
Loud thanks to my thesis advisor, Professor David H. Staelin, for his technical advice and guidance.
Thanks to my mentor, Craig Valenti, at Telcordia for helping me get the project off the ground and for reading my thesis, and thanks to Murray Spiegel for his sound advice. Also, thanks to Stefano Galli, Kevin Lu, Joanne Spino, Brenda Fields, and everyone else at Telcordia who helped me along the way.
Thanks to Jason, my officemate and fellow 6A intern, for being my sounding board and lunch buddy.
A shout of thanks to my friends, who kept me sane during these long, quiet months in Morristown, NJ: Anne, Jenny, Linda, Lucy, Nkechi, Teresa, Xixi, and Yu.
Finally, deep gratitude to my parents for their love, support, and sacrifices through the years!
Table of Contents
ABSTRACT... 2 ACKNOWLEDGEMENTS ... 3 TABLE OF CONTENTS ... 4 LIST OF FIGURES ... 6 CHAPTER 1... 8 1.1 HOME NETWORKING... 81.1.1 Ideal Home Networking: Smart Houses... 8
1.1.2 Problems ... 8
1.2 RELATED WORK... 9
1.2.1 Visual Tracking by MIT Media Lab ... 10
1.2.2 Array Processing... 10
1.2.3 Blind Source Separation and Deconvolution (BSSD) ... 10
1.2.4 Adaptive Processing... 11 1.2.5 Simpler Techniques... 11 1.3 SCOPE OF THESIS... 11 1.4 STRUCTURE OF THESIS... 12 CHAPTER 2... 13 2.1 MAIN ALGORITHMS... 13 2.1.1 MPD... 13 2.1.2 C2I ... 17 2.1.3 DSA ... 22
2.2 ACTUAL METHODS IMPLEMENTED... 22
CHAPTER 3... 24
3.1 BASIC ECHO MODEL... 24
3.2 COMPLEX ECHO ENVIRONMENT SIMULATION... 26
CHAPTER 4... 28
4.1 GOALS... 28
4.2 SPEECH DATA USED... 28
4.3 METHODS... 30
4.4 RESULTS... 32
4.4.1 Simple Echo Environments ... 32
4.4.2 Complex Echoes, One Microphone... 37
4.4.3 Complex Echoes, Three Microphones... 41
4.4.4 Different Training Environments ... 45
CHAPTER 5... 50
5.1 CONCLUSIONS... 50
5.2 FUTURE WORK... 51
5.2.1 Testing in Real Echo Environments ... 51
5.2.3 Microphone Placement ... 52
5.2.4 Real Time ... 52
5.2.5 Continual or Rapid Speaker Movement ... 52
5.2.6 Multiple Speakers... 53 5.3 FINAL THOUGHTS... 53 APPENDIX A... 54 APPENDIX B ... 58 B.1 TEST FUNCTIONS... 58 B.2 SUPPORT FUNCTIONS... 59 B.3 SOURCE CODE... 62 B.3.1 Main Algorithms ... 62 B.3.2 Test Functions... 68 B.3.3 Support Functions... 79 APPENDIX C... 85
C.1 RESULTS FOR SIMPLE MODEL... 85
C.2 TABLES FOR COMPLEX MODEL SIGNALS WITH ONE MICROPHONE... 87
C.3 TABLES FOR COMPLEX SIGNALS WITH THREE MICROPHONES... 88
C.4 DIFFERENT TRAINING ENVIRONMENTS... 90
List of Figures
Figure 2-1: Complex cepstrum of the min-phase component of a signal with an echo at
delay = 0.5s, attenuation = 0.5 ... 14
Figure 2-2: Zoomed in version of Figure 2-1... 14
Figure 2-3: Block diagram of the MPD algorithm... 15
Figure 2-4: Complex cepstrum from Figure 2-1, after the spikes were taken out, using MPD ... 16
Figure 2-5: The spikes that were detected and taken out by MPD ... 16
Figure 2-6: Block diagram for C2I algorithm ... 18
Figure 2-7: Autocorrelation of the original clean signal ... 19
Figure 2-8: Autocorrelation of the signal with an echo at delay = 0.5s, attenuation = 0.5 ... 19
Figure 2-9: Autocorrelation of the resultant signal after processing the reverberant signal with C2I... 20
Figure 2-10: Impulse response of an echo at delay = 0.5s, attenuation = 0.5 ... 21
Figure 2-11: Impulse response estimated by C2I... 21
Figure 3-1: Simple model of an echo as a reflection that is a delayed copy of the original signal ... 24
Figure 3-2: Screen shot of the 3-D Echo Chamber menu in Cool Edit Pro 1.2 ... 26
Figure 4-1: Female subject’s breakdown of errors for varying delays, with attenuation held constant at 0.5... 32
Figure 4-2: Male subject’s breakdown of errors for varying delays, with attenuation held constant at 0.5... 33
Figure 4-3: Female subject’s breakdown of errors for varying attenuation factors, with delay held constant at 11025 samples (0.5 seconds)... 34
Figure 4-4: Male subject’s breakdown of errors for varying attenuation factors, with delay held constant at 11025 samples (0.5 seconds)... 35
Figure 4-5: Percent improvement as a function of delay and of attenuation for male and female subjects ... 36
Figure 4-6: Female subject’s breakdown of errors for complex, one microphone signals ... 37
Figure 4-7: Male subject’s breakdown of errors for complex, one microphone signals.. 38
Figure 4-8: Percent improvement vs. signal environment, female subject ... 39
Figure 4-9: Percent improvement vs. signal environment, male subject ... 40
Figure 4-10: Female subject’s breakdown of errors for complex, multiple microphone signals... 41
Figure 4-11: Male subject’s breakdown of errors for complex, multiple microphone signals... 42
Figure 4-12: Percent improvement vs. echo environment, female subject ... 43 Figure 4-13: Percent improvement vs. echo environment, male subject ... 44 Figure 4-14: How C2I and MPD2 perform on simple echo signals under different
training environments... 46 Figure 4-15: How C2I and MPD2 perform on complex reverberation, one microphone
signals under different training environments... 47 Figure 4-16: How C2Is, DSA, MPDs, MPDs2, MPDs3, SCP perform on complex
reverberation, multi-microphone signals under different training environments ... 49 Figure A-1: Block diagram of the complex cepstrum... 54
Chapter 1
Introduction
1.1 Home Networking
Home networking can refer to anything from simply having a few interconnected computers in a house, to having appliances that are wired to the Internet, to having fully connected "smart houses.” The last definition is the one used in this thesis.
1.1.1 Ideal Home Networking: Smart Houses
As the digital revolution rages on, the notion of smart houses is no longer just a science fiction writer’s creation. These houses are computerized and networked to receive and execute verbal commands, such as to open the door, turn on the lights, and turn on appliances. Ideally, microphones are placed throughout the house, and the
homeowner is free to move about and speak naturally, without having to focus his speech in any particular direction or being encumbered by handheld or otherwise attached microphones. However, many problems must be solved first, before science fiction becomes reality.
1.1.2 Problems
Specifically, speech recognition is crucial to the success of home networking, since home security, personal safety, and the overall system’s effectiveness are all
affected by this component’s ability to decode the speech input, recognize commands, and distinguish between different people’s voices. However, the performance of current speech recognition technology is drastically degraded by distance from the
microphone(s), background noise, and room reverberation.
Therefore, to increase the speed and accuracy of the speech recognition process, a pre-filtering operation should be used to adjust gain, eliminate noise, and cancel echoes. Of these desired functions, echo cancellation will be one of the hardest to design. Hence, the topic of this master’s thesis research is providing “clean” speech to the voice
recognition engine by canceling the 3D echoes that are produced, when a person is speaking and moving about in a home environment.
1.2 Related Work
It is true that much work has been done on echo cancellation. One especially famous project is Stockham et al.’s restoration of Caruso’s singing voice from old phonographic recordings [1]. However, there are additional factors in the home
environment that complicate matters. For instance, different objects and materials in the house absorb and reflect sound waves differently, and many of these objects are not permanent, or at least, they are not always placed in the same location. Additionally, the processing must be done in real time (or pseudo real time), so speed and efficiency, which were less crucial in the Caruso project, need to be considered. For example, in the Caruso project, the researchers used a modern recording of the same song to estimate the impulse response of the original recording environment, but this is impractical for the task at hand. Finally, when the source of the signal is moving around, there is a Doppler Effect, and the system must either track the source’s location to accurately estimate the multipath echoes, adapt to the changing location of the source, or work independently of the source’s location.
free telephony and smart cars have been published [2], [3], but in all of these cases, the speaker does not move very much, and the general direction of the speaker remains relatively constant.
1.2.1 Visual Tracking by MIT Media Lab
One method, proposed by the MIT Media Lab, addresses the tracking problem visually [4]. This solution uses cameras and a software program called Pfinder [5] to track human forms and steers the microphone beam accordingly. However, the use of video cameras and image processing may be expensive—both computationally and monetarily. Also, while people may be willing to have microphones in their houses, they may still be uncomfortable with the possible violations of privacy due to having cameras in their homes.
1.2.2 Array Processing
In addition, there has been a lot of research on using large microphone arrays to do beamforming [6]. However, these approaches require anywhere from tens to hundreds of microphones, which can be very expensive, especially for private homes with multiple rooms. Also, the math becomes very complicated, so processing speed and processing power may become issues.
1.2.3 Blind Source Separation and Deconvolution (BSSD)
Another MIT student, Alex Westner, examined in his master’s thesis ways to separate audio mixtures using BSSD algorithms. These algorithms were adaptive and based on higher order statistics. Although his project focused on ways to separate multiple speech sources, it had the potential of shedding some light into the echo cancellation problem at hand. After all, one way to view echo cancellation is the deconvolution of an unknown room impulse response from a reverberant signal (also known as blind deconvolution). Also, the original speaker and the echoes could be viewed as multiple sources. However, further reading revealed that the BSSD algorithms
assumed that the sources were statistically independent, which is not the case for echoes, since echoes are generally attenuated and delayed copies of the original source. Also, Westner found that even a small amount of reverberation severely impairs the
performance of these algorithms [7].
1.2.4 Adaptive Processing
Adaptive processing algorithms are very popular for noise cancellation, though they are used sometimes for echo cancellation as well. However, since this project focuses specifically on the context of home networking, it is reasonable to assume that utterances will tend to be limited to a few seconds. (e.g. “Close the refrigerator door.” or “Turn off the air conditioner.”) Therefore, the algorithms (normally iterative or
recursive) are not likely to converge within the duration of the signals [8].
1.2.5 Simpler Techniques
Therefore, this thesis will focus on simpler, classical approaches, such as cancellation in the cepstral domain, estimating the multipath impulse response through the reverberant signal’s autocorrelation, and for the multiple microphone case, delaying and summing the signals (also known as cross spectra processing or delay and sum beamforming). In addition, the first two methods are combined with the third when there are multiple microphones, and the multi-microphone cepstral domain processing case is based on work done by Liu, Champagne, and Kabal in [9].
1.3 Scope of Thesis
Based on the background research described above, it seems that even with large arrays or highly complex algorithms, developing a system that effectively removes
As suggested previously, the echo environment is not stationary (i.e. objects and speakers are not in fixed locations), so the algorithms cannot assume any fixed impulse responses. This rules out predetermining the room impulse response by sending out a known signal and recording the signal that reaches the microphone.
However, a key assumption, as mentioned in Section 1.2.4, is that utterances will tend to be short, so that the multipath environment can be considered stationary within the duration of an utterance. In other words, the person is not moving very fast while speaking. Note, though, that “movement” refers to any change in position, including turning one’s head. Change in the direction that the speaker faces will alter the multipath more drastically that other forms of movement. Therefore, in order for the stationary assumption to hold, the speaker must keep his head motionless while uttering a command.
Another assumption is that the detection of silence is possible, which is valid, since most speech recognition software programs already have this feature. As a result, pauses can be used to separate utterances.
Therefore, the purpose of this thesis is to develop, simulate, and compare echo cancellation algorithms in the context of smart houses. There are many other issues, such as dealing with multiple simultaneous speakers or external speech sources, (e.g.
televisions and radios). However, these problems are beyond the scope of this thesis.
1.4 Structure of Thesis
• Chapter 1 gives background information, motivation, and an overview of the problem, as well as defining the scope of the thesis.
• Chapter 2 describes the algorithms that were chosen and implemented. • Chapter 3 describes the echo environments and how they were simulated.
• Chapter 4 explains the experiments that were set up and run, and the various metrics used to compare the different algorithms and methods.
Chapter 2
Methods
2.1 Main Algorithms
The actual methods implemented are combinations of three basic ideas: MPD (Min-phase Peak Detection), C2I (Correlation to Impulse), and DSA (Delay, Sum, Average).
2.1.1 MPD
This algorithm is based on the observation by Kabal et al. in [9] that in the cepstral domain, the minimum-phase∗ component of a reverberant speech signal shows distinct decaying spikes at times that are multiples of each echo’s delay. For instance, if there is an echo that begins at t = 0.5s, then there will be noticeable impulses at t = 0.5n, where n = 1,2,3… The height of these impulses depends on the echo intensity. Please see Appendix A for a detailed explanation of the complex cepstrum, why the echoes show up as spikes, and how zeroing them out results in canceling out the echoes.
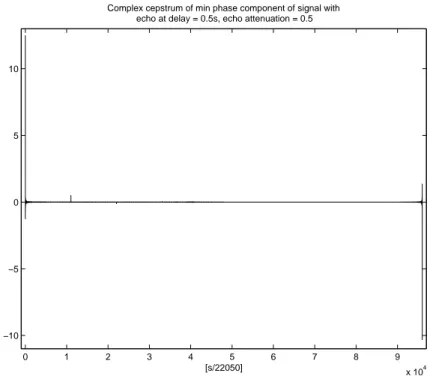
The following figures show the complex cepstrum of the minimum phase component of a signal with an echo at a delay of 0.5s and attenuated by 0.5:
0 1 2 3 4 5 6 7 8 9 x 104 −10 −5 0 5 10 [s/22050]
Complex cepstrum of min phase component of signal with echo at delay = 0.5s, echo attenuation = 0.5
Figure 2-1: Complex cepstrum of the min-phase component of a signal with an echo at delay = 0.5s, attenuation = 0.5 1 1.5 2 2.5 3 3.5 4 x 104 −0.5 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 0.5
Zoomed in version of complex cepstrum
[s/22050]
Given the above characterizations, the MPD algorithm works as follows:
1) decompose signal into its all-pass (ap) and minimum-phase (mp) components [10]
2) take the complex cepstrum of the mp component (cm)
3) put cm through a comb filter (done by a method called rfindpeaks2, which detects impulsive values and zeros them out)
4) take the inverse complex cepstrum of the altered cm 5) recombine with the all-pass component
Here’s the algorithm in block diagram form:
x[n]
Figure 2-3: Block diagram of the MPD algorithm
The following figures show the result of applying the algorithm on a signal with a simple echo at t = 0.5s, attenuation = 0.5:
All pass and minimum phase decomposition ap[n] mp[n] Complex Cepstrum cm[n] Comb Filter cm’[n] InverseComplex Cepstrum mp’[n] Recombine
All pass and Min Phase Components
0 1 2 3 4 5 6 7 8 9 x 104 −10 −5 0 5 10 [s/22050]
Complex cepstrum with echo spikes zeroed out
Figure 2-4: Complex cepstrum from Figure 2-1, after the spikes were taken out, using MPD 0 1 2 3 4 5 6 7 8 9 x 104 −0.2 −0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 [s/22050]
Difference between complex cepstrum with echoes and complex cepstrum after echoes were taken out
From Figures 2-4 and 2-5, it is clear that this method should work very well for simple echoes. However, when signals from complex and highly reverberant
environments are used, the ambience effect will not be removed. This is because rather than having discrete echoes only, there are also echoes that are so closely spaced that they are perceived as a single decaying sound. These closely spaced echoes cannot be
distinguished from the original signal content in the cepstral domain.
2.1.2 C2I
This algorithm takes advantage of the observation that the autocorrelation function of the reverberant signal will have peaks at the echo delay(s). Therefore, the autocorrelation can be used to estimate the multipath impulse response. The following algorithm was used:
Let: x[n] = reverberant signal of length N
Rx[n] = autocorrelation of x (xcorr(x(n)) in Matlab) 1) Find Rx[n].
2) Since Rx[n] is symmetric, with length 2N+1, where N = length of x[n], and the maximum of Rx is Rx[N] (normally, this occurs at Rx[0], but Matlab scales it differently), it is only necessary to look at Rx[N:2N+1]. Therefore, let Rx2[n] = Rx[N:2N+1].
3) Use the findpeaks2 method (similar to rfindpeaks from MPD) to find the spikes in Rx2[n], which make up a scaled version of the estimated impulse response, h’[n].
5) The estimated original signal, s’(n), is found by IFFT(X[k])/H[k]), where X[k] = FFT(x[n]) and H[k] = FFT(h[n])*.
In Figure 2-6, the algorithm is translated into block diagram form.
Figure 2-6: Block diagram for C2I algorithm
It is important to note that it is possible for H’[k] to include samples with the value zero. In this case, the algorithm would not work, due to the inversion step. Instead, direct deconvolution in the time domain is done using the deconv(x, h’) command in Matlab. However, this takes considerably longer (minutes, as compared to seconds when using the frequency domain method).
Figures 2-7 to 2-11 show how this algorithm works in a simple case, where the echo attenuation (alpha) is 0.5, and the echo delay is 0.5 seconds (or 11025 samples).
* The FFT (Fast Fourier Transform) is an algorithm for computing the DFT (Discrete Fourier Transform).
The DFT is made up of samples of the DTFT (Discrete Time Fourier Transform), which is a continuous function. For a discrete time domain signal x[n], its “Fourier Transform” generally refers to its DTFT, which is expressed as either X(w) or X(ejw), while its DFT is generally expressed as X[k].
s’[n] xcorr( ) Rx[n] EstimateImpulse
Response h’[n] FFT H’[k] Inverse FFT X[k] Multiply S’[k] IFFT ] k [ ' H 1 x[n]
0 2 4 6 8 10 12 14 16 18 x 104 −400 −300 −200 −100 0 100 200 300 400 500 600 700
Auto correlation of the original signal
time [s/22050]
Figure 2-7: Autocorrelation of the original clean signal
0 2 4 6 8 10 12 14 16 18 −1200 −800 −400 0 400 800 1200 1600 2000
0 2 4 6 8 10 12 14 16 18 x 104 −1000 −600 −200 200 600 1000 1400 1800 time [s/22050]
Auto correlation of the estimated original signal
Figure 2-9: Autocorrelation of the resultant signal after processing the reverberant signal with C2I
The following figures show the actual impulse response and the one estimated by C2I, respectively:
0 1 2 3 4 5 6 7 8 9 x 104 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 time [s/22050] h
Impulse response for simple case of delay = 0.5s, echo attenuation = 0.5
(0.5)
(11025=0.5s)
Figure 2-10: Impulse response of an echo at delay = 0.5s, attenuation = 0.5
0 1 2 3 4 5 6 7 8 9 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
C2I estimated impulse response for simple case of delay = 0.5s, echo attenuation = 0.5
h
This algorithm is not likely to be as good as MPD is at eliminating simple echoes, because the estimated impulse response is not exact, even for the most basic case, as illustrated by Figure 2-11. Meanwhile, as illustrated by Figures 2-3 to 2-5, the MPD algorithm can very effectively detect all of the spikes for a simple case. However, it is harder to predict how C2I will perform in a complex environment, so it is still worthwhile to consider this algorithm.
2.1.3 DSA
When there are multiple microphones, speech will generally reach the different microphones at different times. Therefore, to combine these signals, it is important to line the signals up first. This can be accomplished through finding the cross correlation between two signals and finding the maximum of the cross correlation function.
Knowing the location of the maximum will then allow the relative delay to be calculated, and the signals can be lined up and added. For more than two microphones, the first two signals are lined up and summed, and that sum is used to line up with and add to the third signal, and so on. The sum is then divided by the number of input signals, thereby yielding the average.
By lining the signals up and taking the average, the original speech signal adds constructively, while the echoes are generally attenuated.
2.2 Actual Methods Implemented
The algorithms mentioned above can be combined in various ways, especially when there are multiple microphones, because the averaging can be done at different stages. The following is a list of the main methods that have been coded and tested: • mpd2(v) – takes in the sound vector v and performs the basic MPD algorithm • c2i(v) – takes in the sound vector v and performs the C2I algorithm
• mpds(m) – takes in the matrix m (whose columns are sound vectors), averages the all-pass components using the DSA algorithm, takes a normal average (without lining up) of the min-phase components, and does MPD (steps 2-5)
• mpds2(m) – takes in the matrix m, averages the all-pass components using the DSA algorithm, take the complex cepstrum and eliminate the impulses of the individual min-phase components, take the average of the cepstra, and then take the inverse cepstrum and recombine
• mpds3(m) – similar to the previous two, except that the averaging of the min-phase component takes place after the inverse cepstrum has been taken for each processed signal
• scp(m) – Spatial Cepstral Processing – takes in the matrix m, does DSA on the all-pass components, averages the min-phase components in the cepstral domain (no peak detection), and recombines
• dsa2(m) – takes in the matrix m and does plain DSA (i.e., without separating the all-pass and min-phase components)
• c2is(m) – takes in matrix m and applies the C2I algorithm to each column vector, and then does DSA averaging on the resultant vectors
Of course, other functions have also been coded in Matlab in order to support these methods. A comprehensive list of all the methods and their respective descriptions will be included as Appendix B.
Chapter 3
Simulation of Multipath Environments
This chapter will explain the echo models and simulations. A detailed description of the actual speech corpora generated will be discussed in the Experiments section of the next chapter.
3.1 Basic Echo Model
The most basic echo model is that of a copy of the original signal reflected off a surface, and therefore, is delayed and attenuated relative to the “direct path” copy. Figure 3.1 illustrates this model.
Figure 3-1: Simple model of an echo as a reflection that is a delayed copy of the original signal
Source
Microphone Direct Path
The two main parameters for each echo are the delay and the attenuation. To generate sound files based on this echo model, a Matlab function, addecho2wav(A, alpha,
delay), was implemented. A is the original signal, represented as a vector with values
between -1 and 1, inclusive. Alpha is a row vector whose elements indicate the attenuation of each echo, and delay is a row vector of the corresponding delays. Therefore, this function can add multiple echoes.
In general, a reverberant signal is represented as a convolution (denoted by *) between the original signal and the room impulse response:
x[n] = s[n] * h[n] (3.1)
For the simple model, the form of the impulse response can be generalized as
h[n] = δ[n] + α1•δ[n-delay1] + α2•δ[n-delay2] + … + αN•δ[n-delayN], (3.2)
where N is the number of echoes, δ[n] is the unit impulse function, and “•” denotes
multiplication. Given 3.2, the reverberant signal can also be expressed as follows:
x[n] = s[n] + α1• s[n-delay1] + α2• s[n-delay2] + … + αN• s[n-delayN] (3.3)
This is considered a simple model, because it does not take a lot of other factors into consideration, such as room size, damping ratios of different surfaces, and
positioning of microphones and sound sources. The next section will discuss how to simulate more realistic reverberant signals.
3.2 Complex Echo Environment Simulation
A well-known mathematical model for simulating room reverberation is the Image Method [11]. Instead of actually implementing this method to simulate
reverberant data, a popular audio editing software program, Cool Edit Pro 1.2, was used. This powerful (and fast) tool includes functions such as filtering, noise reduction, and 3D echo simulation, as well as multi-track mixing.
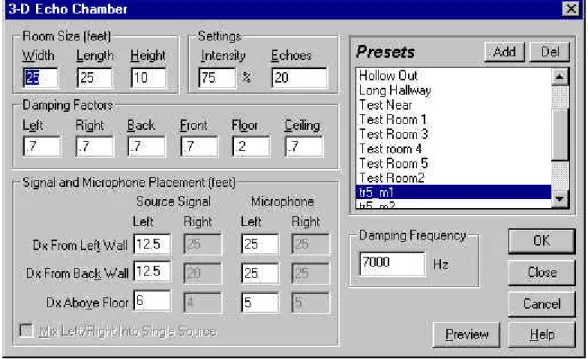
The following figure is a screen shot of the 3D Echo Chamber menu:
Figure 3-2: Screen shot of the 3-D Echo Chamber menu in Cool Edit Pro 1.2
As Figure 3-2 shows, this feature allows the specification of the room dimensions, speaker and microphone locations, damping factors of the room’s surfaces, number of echoes, etc.
However, while Cool Edit Pro generates a fairly realistic reverberant signal, the software does have some limitations. For instance, it assumes that the speech source is a point source (i.e. speech radiates equally in all directions), which is not true, because the
direction a person is facing affects the signal that will be received by the microphone. Also, the software does not allow the user to specify which type of microphone is being used. An omni-directional microphone is assumed, which, as the name suggests, picks up sound from all directions with equal gain. Other types of microphones with different beam patterns are available, and they may be more practical for the room environment.
Nevertheless, it is still possible to evaluate and compare the effectiveness of various echo cancellation algorithms, despite the points mentioned above. For instance, while the use of different microphones may improve the signal to noise ratios, it should not affect how well one algorithm performs relative to another algorithm. The same is true for having a directional source, which means that the signal content will be lower at some microphones. Therefore, these factors may affect the overall performance of the speech recognition system, but not the relative performance of the algorithms.
Chapter 4
Experiments and Results
4.1 Goals
The experiments described in this chapter were designed to answer the following questions:
1) Under the simple echo model and using one microphone, how are C2I and MPD2 affected by echo attenuation (intensity) and by echo delay?
2) Under the complex echo model and using one microphone, how do C2I and MPD2 perform in low, medium, and high echo environments?
3) Under the complex echo model and using multiple (three) microphones, how do C2Is, DSA, MPDs, MPDs2, MPDs3, and SCP perform in low, medium, and high echo environments?
4) How does the training environment affect the algorithms’ performance in the above cases?
4.2 Speech Data Used
The clean speech corpora were recorded using a low noise, directional
microphone (AKG D3900) connected to a pre-amp (Symetrix SX202), which feeds the signals into the embedded ESS sound card of a Compaq desktop PC, thereby creating
digital sound files in the .wav format. The software used for the recordings is Cool Edit Pro. The sampling rate is 22 KHz, and each clip has 96000 samples, which translates to about 4.3 seconds in length.
Each wave file contains one sentence that ranges from five to nine words long. There are sixteen such sentences used for testing, and there were two speakers: one male and one female.
These clean signals were then digitally processed to add different levels of echoes. For the simple echo model described in Section 3.2, echoes of varying
attenuation factors and delays were added. Specifically, the (attenuation, delay) pairs are (0.25, 11025), (0.50, 11025), (0.75, 11025), (0.5, 5513), and (0.5, 22050), where
attenuation is a scalar, and delay is in number of samples. For the complex model, there are many variables and an infinite number of combinations of the different parameters. Therefore, in the interest of time, the test environments are simplified as low, medium, and high echo cases. The following chart specifies the parameters of the different environments:
Table 4-1: Parameters for the different echo environments
Low Echo Medium Echo High Echo
Room Size (ft) 25 x 25 x 10 50 x 50 x 10 50 x 50 x 10 Source Coordinates (ft) (12.5, 12.5, 6) (25, 25, 5) (25, 25, 5) Mic1 Coordinates (ft) (25, 25, 5) (15, 35, 5) (15, 35, 5) Mic2 Coordinates (ft) (0.01, 25, 5) (25, 35, 5) (25, 35, 5) Mic3 Coordinates (ft) (12.5, .01, 5) (40, 35, 5) (25, 40, 5) Number of Echoes 20 350 1200 Surface Reflectivities (Floor, Ceiling, Walls)
4.3 Methods
The metrics for measuring the effectiveness of the algorithms are the number of errors in speech recognition by Dragon Systems’ Naturally Speaking software and the percent of improvement in recognition.
The number of errors is broken down into the number of misrecognized (wrong) words, added words, and missing words. For example:
Original: the little blankets lay around on the floor Recognized: the little like racing lay around onward or “Like,” “onward,” and “or” are counted as wrong for “blankets,” “on,” and “the.” “Racing” is counted as an added word, and there is also a missing word at the end, since the original sentence had three words after “around,” but the recognized result only had two. These errors were counted manually and tallied for each test case.
The percent improvement was also calculated for each algorithm in each test case. Percent improvement is defined as follows:
(4.1)
While Unprocessed is signal environment specific, Clean is training environment specific. For instance, to determine the % Improvement of C2I on one microphone, complex, low echo signals, the number of errors for the unprocessed, one microphone, complex, low echo signals is used. On the other hand, Clean remains the same for all test cases within the same training environment.
The comprehensive tables of these results are included as Appendix C.
Meanwhile, the figures in the following section summarize the findings from the trials. Other metrics, such as the mean square error (MSE) relative to the clean signal, and the signal to noise ratio (SNR), were also considered. However, due to delays in the reverberant signal, the MSE will not provide a good measure of how much of the echoes
Clean for Errors of # -essed for Unproc Errors of # Processed for Errors of # -essed for Unproc Errors of # 100 t Improvemen % ≡ ×
have been cancelled by the algorithms. The SNR is also inappropriate, because the algorithms adjust the gains of the signals to prevent clipping.*
SNR is normally defined as 10 log (signal power/noise power), which could be calculated with the following formula:
(4.2)
Where so[n] and xo[n] are the non DC biased versions of the original clean signal s[n] and
the reverberant signal x[n], respectively. Mathematically, they are defined as
so[i] = s[i] – mean(s[n]), for i = 1…N (4.3)
xo[i] = x[i] – mean(x[n]), for i = 1…N (4.4)
The problem arises when x[n] is normalized to the maximum volume that does not result in clipping, because the denominator is not really the noise power, since the signal in x[n] has been either amplified or attenuated. However, even without the normalization, there would be a problem with the SNR calculation, because the direct path signal is attenuated in the complex model, so signal power is lost. Therefore, the denominator could be negative, which would cause the log expression to equal negative infinity. ) ] n [ s ] n [ x ] n [ s log( 10 N 1 n 2 o N 1 n 2 o N 1 n 2 o
å
å
å
= = = −4.4 Results
Each of the following sections addresses one of the four questions posed in Section 4.1. The results are presented as numbers of errors, as well as percent improvement.
4.4.1 Simple Echo Environments
The following results show the effects of varying delays and varying attenuations on speech recognition performance.
Constant Attenuation, Varying Delay, Female Subject
0 10 20 30 40 50 60 70 80 none 5513 0.5 MPD2 5513 0.5 C2I 5513 0.5 none 11025 0.5 MPD2 11025 0.5 C2I 11025 0.5 none 22050 0.5 MPD2 22050 0.5 C2I 22050 0.5 Signal Environment N u m b er o f E rro rs
# Wrong # Added # Missing Total Errors
Figure 4-1: Female subject’s breakdown of errors for varying delays (5513, 11025, and 22050 samples), with attenuation held constant at 0.5
Constant Attenuation, Varying Delay, Male Subject 0 10 20 30 40 50 60 70 80 none 5513 0.5 MPD2 5513 0.5 C2I 5513 0.5 none 11025 0.5 MPD2 11025 0.5 C2I 11025 0.5 none 22050 0.5 MPD2 22050 0.5 C2I 22050 0.5 Signal Environment N u m b er o f E rro rs
# Wrong # Added # Missing Total Errors
Figure 4-2: Male subject’s breakdown of errors for varying delays (5513, 11025, and 22050 samples), with attenuation held constant at 0.5
Looking only at the unprocessed cases, one notices that the breakdown of errors is similar for both the male and female subjects. Even though the total number of errors decreases from d = 11025 to d = 22050 for the male subject, the following trends prevail:
- The number of words added increases with the delay interval.
These trends make sense, because the echo overlaps with the original signal, so the longer the delay, the more “clean” speech appears at the beginning of the signal. This accounts for the decrease in misrecognized words, when the delay becomes large.
However, the number of words added increases, because the signal duration becomes longer. As for the missing words, they tend to be short words, such as “a,” “to,” and so on, so there is no clear reason why delay should affect the number of missing words.
Constant Delay, Varying Attenuation, Female Subject
0 10 20 30 40 50 60 70 80 none 11025 0.25 MPD2 11025 0.25 C2I 11025 0.25 none 11025 0.5 MPD2 11025 0.5 C2I 11025 0.5 none 11025 0.75 MPD2 11025 0.75 C2I 11025 0.75 Signal Environment N u m b er o f E rro rs
# Wrong # Added # Missing Total Errors
Figure 4-3: Female subject’s breakdown of errors for varying attenuation factors (0.25, 0.5, and 0.75), with delay held constant at 11025 samples
Constant Delay, Varying Attenuation, Male Subject 0 10 20 30 40 50 60 70 80 none 11025 0.25 MPD2 11025 0.25 C2I 11025 0.25 none 11025 0.5 MPD2 11025 0.5 C2I 11025 0.5 none 11025 0.75 MPD2 11025 0.75 C2I 11025 0.75 Signal Environment N u m b er o f E rro rs
# Wrong # Added # Missing Total Errors
Figure 4-4: Male subject’s breakdown of errors for varying attenuation factors (0.25, 0.5, and 0.75), with delay held constant at 11025 samples
For constant delay and varying attenuation factors, the number of misrecognized word tend to increase with the increasing attenuation factor (which actually means less attenuation, or higher echo intensity), while the other types of errors are not affected as much. This is consistent with the argument in the previous case. With attenuation being the only variable, the number of misrecognized words increases as the echo intensity gets stronger, because the words are more distorted. This can, but does not necessarily, cause more added words, as one can see from the differences in the female and male cases.
0.5 1 1.5 2 2.5 x 104 −20 0 20 40 60 80 100 120
Constant Atten., Var. Delay, Male
Percent Improvement 0.2 0.4 0.6 0.8 1 −20 0 20 40 60 80 100 120
Constant Delay, Var. Atten., Male
0.5 1 1.5 2 2.5 x 104 −20 0 20 40 60 80 100 120
Constant Atten., Var. Delay, Female
Percent Improvement Delayed Samples [s/22050] 0.2 0.4 0.6 0.8 1 −20 0 20 40 60 80 100 120
Constant Delay, Var. Atten., Female
Attenuation of Echo MPD2 C2I
Figure 4-5: Percent improvement as a function of delay and of attenuation for male and female subjects
The graphs in Figure 4-5 show the following trends:
- MPD2 increases first and then decreases with delay and attenuation. - C2I’s performance deteriorates more quickly than MPD2’s.
- C2I is more sensitive to attenuation than it is to delay.
The first observation can be explained by the nature of the MPD2 algorithm. Specifically, it has to do with how the echo’s spikes are detected. (Refer to Section 2.1.1.) When the echo intensity is low, the echo’s spikes are small, so they become harder to detect. For small delays, the early spikes are also harder to detect, because the
original signal’s cepstral content has not decreased enough for the spikes to stand out. These properties also explain why MPD2’s performance does not decrease as drastically as C2I’s when the intensity or delay increases.
To explain the third observation that C2I is more sensitive to echo intensity, recall that in Section 2.1.2, it was pointed out that there are errors in estimating the echo’s intensity. Therefore, as the echo intensity increases, these errors become more noticeable.
4.4.2 Complex Echoes, One Microphone
Breakdown of Errors for Complex, 1 Mic Environments, Female Subject
0 20 40 60 80 100 120 none Low E cho, m 1 MPD2 Low E cho, m 1 C2 I Low E cho, m 1 none M edi um E cho,m 1 MPD2 M edi um E cho,m 1 C2 I M edi um E cho,m 1 none H igh E cho,m 1 MPD2 H igh E cho,m 1 C2 I H igh E cho,m 1 Signal Environment N u m b er o f E rro rs
Breakdown of Errors for Complex, 1 Mic Environments, Male Subject 0 20 40 60 80 100 120 none Low E cho,m 1 MPD2 Low E cho,m 1 C2 I Low E cho,m 1 none M edi um E cho,m 1 MPD2 M edi um E cho,m 1 C2 I M edi um E cho,m 1 none H igh E cho,m 1 MPD2 H igh E cho,m 1 C2 I H igh E cho,m 1 Signal Environment N u m b er o f E rro rs
# Wrong # Added # Missing Total Errors
Figure 4-7: Male subject’s breakdown of errors for complex, one microphone signals
For the complex model, the breakdown of errors is fairly consistent between the two subjects. However, there are two obvious differences from the simple model’s errors. First, there are very few words added, and second, there are more words missing. These observations show that the two models are indeed very different, which can account for the poor performance of C2I and MPD2 in these cases.
Percent Improvement for Complex, 1 Mic Environments, Female Subject -10.00 0.00 10.00 20.00 30.00 40.00 50.00 60.00 70.00
Low Echo, m1 Medium Echo,m1 High Echo,m1
Signal Environment P e rcen t Im rp o vem en t C2I MPD2
Percent Improvement for Complex, 1 Mic, Male Subject -25.00 -20.00 -15.00 -10.00 -5.00 0.00 5.00
Low Echo,m1 Medium Echo,m1 High Echo,m1
Signal Environment P e rcen t Im p ro vem en t C2I MPD2
Figure 4-9: Percent improvement vs. signal environment, male subject
Next, using the results for the complex model, percent improvement is plotted against the different echo environments. The results for the male and female subjects are very consistent for the medium and high echo environments. For both, the percent improvement was slightly greater for the high echo case than the medium echo case. This can be explained by the observation that the signals in the high echo environment are so distorted that it is even hard for humans to understand them. Therefore, they have less room for “negative improvement,” which occurs when the processed signal has more recognition errors that the unprocessed signal. One possible source of the extra errors is the rounding off that takes place when transforming a signal to another domain and back.
In the low echo environment, the results are drastically different between the two subjects, with a large positive percent improvement for the female, and a large negative improvement for the male. Unfortunately, there is no obvious explanation for this.
4.4.3 Complex Echoes, Three Microphones
Breakdown of Errors for Complex, Multi. Mic Environments, Female Subject
0 20 40 60 80 100 120 140 none Low Echo DSA Low Ec ho SCP Low Ec ho MPDS Low E cho MPDS 2 Low Ech o MPDS 3 Low Echo C2Is Low Echo none Medium Echo DSA Mediu m E cho SCP Mediu m E cho MPDS Mediu m Ec ho MPDS 2 Me dium Echo MPDS 3 Me dium Echo C2Is Mediu m E cho none High Echo DSA High Echo SCP H igh Ec ho MPDS High Ech o MPDS 2 High Echo MPDS 3 High Echo C2Is H igh E cho Signal Environment N u m b er o f E rro rs
# Wrong # Added # Missing Total Errors
Figure 4-10: Female subject’s breakdown of errors for complex, multiple microphone signals
Breakdown of Errors for Complex, Multi. Mic Environments, Male Subject 0 20 40 60 80 100 120 140 none Low Echo DSA L ow Ech o SCP Low Echo MPDS Low Echo MPDS 2 Low Echo MPDS 3 Low Ech o C2Is L ow Ec ho none Medi um E cho DSA Med ium E cho SCP Mediu m Ec ho MPDS Mediu m Ec ho MPDS 2 Me dium E cho MPDS 3 Medi um E cho C2Is M edium Echo none High Echo DSA High E cho SCP High E cho MPDS High Echo MPDS 2 Hi gh E cho MPDS 3 Hi gh Ec ho C2Is Hi gh E cho Signal Environments Numbe r of Er ro rs
# Wrong # Added # Missing Total Errors
Figure 4-11: Male subject’s breakdown of errors for complex, multiple microphone signals
Figures 4-10 and 4-11 show that the breakdown of errors is fairly consistent with the one microphone case’s data in the previous section. However, the number of errors is higher for the unprocessed signals in the low and medium echo environments with three microphones. This makes sense, because there are extra distortions that arise from simply adding the signals from three microphones, without accounting for their relative delays. Such a difference does not show up in the high echo environment, because as mentioned in the previous section, the signals are already very distorted. Therefore, the number of errors is already at a maximum.
Percent Improvement for Complex, Multi. Mic Environments, Female Subject -5.00 0.00 5.00 10.00 15.00 20.00 25.00 30.00 35.00 40.00 45.00
Low Echo Medium Echo High Echo
Signal Environment P e rcen t Im p ro vem en t C2Is DSA MPDs MPDs2 MPDs3 SCP
Percent Improvement for Complex, Multi. Mic Environments, Male Subject -10.00 -5.00 0.00 5.00 10.00 15.00 20.00 25.00 30.00 35.00
Low Echo Medium Echo High Echo
Signal Environment P e rcen t Im p ro vem en t C2Is DSA MPDs MPDs2 MPDs3 SCP
Figure 4-13: Percent improvement vs. echo environment, male subject
In Figures 4-12 and 4-13, the percent improvement is plotted for the three microphone, complex signals. The trends are more consistent between the two subjects, compared to the one microphone, complex environments. In almost all of the cases, except for female subject, medium echo, DSA has the highest percent improvement. This is somewhat surprising, since DSA is simply the delay and sum method, which means that the extra work done in the other algorithms actually made the signals worse.
4.4.4 Different Training Environments
Most commercial speech recognition software programs, such as Dragon
Systems’ Naturally Speaking, are user specific and require an initial training session for each user. This process allows the software to “learn” the characteristics of a user’s speech, and it is generally accomplished by having the person read sentences, as prompted by the program.
A different user had to be created for each of the 14 training environments. However, the typical type of training described above could only be done for the “clean” environment, unless an actual effects box, with the capabilities of adding different types of echoes and performing the different algorithms, was built and put between the
microphone and the computer’s sound card. Of course, building such a device was not feasible, given the nature and the timeframe of this project.
Hence, for all of the other training environments, the mobile training feature of the software had to be used. Mobile training is intended for people who want to record their dictations onto tape or digital recorders and later transfer their speech to the computer for transcription by the software. Since the impulse response of a recorder is likely to be different from that of a microphone, it is necessary to have a different training process for mobile users, rather than to have them use the regular live training process with a microphone and then try to transcribe speech from a recorder.
Mobile training generally involves recording about 20 minutes of speech, using a script provided by the software, and then instructing the software to read the sound file. In the following experiments, the training data was recorded and saved as a .wav file, using the microphone setup that was described in Section 4.2. This file, without any processing, was used for the “clean, mobile” training environment. The files was also processed accordingly to create all of the other training environments.
of improvement. Some of the other environments may have been so adverse, that no discernible differences will appear under the different training environments.
Effect of Training Environment on Performance of Algorithms for Simple, 1 Mic, Female Subject 0 20 40 60 80 100 120 cl ean cl ean, m obi le m u lt. echo, 1 m ic m u lt. echo, 1 m ic, c2i m u lt. echo, 1 m ic, m pd2 m u lt. echo, 3 m ic m u lt. echo, 3 m ic, c2is m u lt. echo, 3 m ic, dsa m u lt. echo, 3 m ic, m pds m u lt. echo, 3 m ic, m pds2 m u lt. echo, 3 m ic, scp si m p le echo, 1 m ic si m p le echo, 1 m ic, c2i si m p le echo, 1 m ic, m pd2 Training Environment P e rcen t Im p ro vem en t C2i MPD2
Figure 4-14: How C2I and MPD2 perform on simple echo signals under different training environments
Effect of Training Environment on Performance of Algorithms for Complex, 1 Mic, Female Subject -400 -300 -200 -100 0 100 200 300 cl ean cl ean, m obi le m u lt. echo, 1 m ic m u lt. echo, 1 m ic, c2i m u lt. echo, 1 m ic, m pd2 m u lt. echo, 3 m ic m u lt. echo, 3 m ic, c2is m u lt. echo, 3 m ic, dsa m u lt. echo, 3 m ic, m pds m u lt. echo, 3 m ic, m pds2 m u lt. echo, 3 m ic, scp si m p le echo, 1 m ic si m p le echo, 1 m ic, c2i si m p le echo, 1 m ic, m pd2 Training Environment P e rcen t Im p ro vem en t C2i MPD2
Figure 4-15: How C2I and MPD2 perform on complex reverberation, one microphone signals under different training environments
The original theory and purpose behind trying different training environments was that an algorithm might perform better when the training data was from the same
environment, since the speech recognition software uses pattern matching to some extent to identify sounds and words. However, this turns out not to be the case, as shown by Figures 4-14 and 4-15.
The likely explanation for the results lies in the nature of the mobile training process, because it does not allow the user to correct recognition errors. Therefore, when
However, this still does not allow for the training of processed environments, which was the main goal of this experiment. Another possible way would have been to use “pseudo-live” training, where a tape player plays the desired training signals to a microphone, thereby fooling the software into “thinking” that there is a real person speaking.
However, this too, may not work, because if the reverberant signal is too distorted, such that if the software is not satisfied with how a word sounds, it will keep asking that the word be repeated. Alternatively, the word can be skipped. This process would also be extremely tedious with so many training environments.
Incidentally, for one-microphone tests, “clean, mobile” seems to yield the highest percentage of improvement for both of the algorithms. The fact that it does better than the “clean” environment suggests that similarity between training environment and signal environment does help. Namely, the similarity arises from the test files being transcribed as .wav files, which is how “clean, mobile” was trained, versus using a microphone, which was how “clean” was trained.
Effect of Traning Environment on Performance of Algorithms for Complex, Multi. Mic, Female Subject -60 -40 -20 0 20 40 60 80 100 cl ean cl ean, mobi le mul t. ec ho, 1 mi c mul t. ec ho, 1 mi c, c2 i mul t. ec ho, 1 mi c, mpd2 mul t. ec ho, 3 mi c mul t. ec ho, 3 mi c, c2 is mul t. ec ho, 3 mi c, ds a mul t. ec ho, 3 mi c, mpds mul t. ec ho, 3 mi c, mpds 2 mul t. ec ho, 3 mi c, scp si mpl e ec ho, 1 mi c si mpl e ec ho, 1 mi c, c2 i si mpl e ec ho, 1 mi c, mpd2 Training Environment P e rcen t Im p ro vem en t C2Is DSA MPDs MPDs2 MPDs3 SCP
Figure 4-16: How C2Is, DSA, MPDs, MPDs2, MPDs3, SCP perform on complex reverberation, multi-microphone signals under different training environments
As with the one microphone cases, there is no correlation here between an algorithm and an environment trained under the same algorithm. The DSA environment yielded the most consistently high improvement percentages. While others had higher improvement for certain algorithms, they also had lower minimums. Interestingly, DSA also had the best performance in most of the training environments, though SCP had the highest improvement percentage in the DSA training environment. However, the reason behind this relationship is not obvious at this point.
Chapter 5
Conclusions and Future Directions
5.1 Conclusions
The goal of this project was to research, develop, and compare algorithms for echo cancellation in the home environment. During the course of this project, it became obvious that the problem of echo cancellation with unknown and variable room impulse responses is a very general and hard one. However, with some practical assumptions that simplified the problem, it was possible to identify some promising algorithms to
implement and test.
After performing many tests and examining the results, the following observations can be made:
- The complex, realistic reverberation model is very different from the simple echo model, and the algorithms that work well in the simple case do not carry over very well to the complex model.
- Having multiple microphones is an effective way to improve speech, but if the echo environment is very high, nothing is effective. However, for most rooms, the surface reflectivities will not be as great as those used in the high—or even medium—echo environments.
- Different algorithms work better under different environments. Therefore, it may be feasible to implement a system that can choose among a number of
algorithms, as well as arguments to their functions, based on user input on the room parameters.
It is important to realize that while echo cancellation is a very general area, and much work has been done in this field in the last several decades, the efforts on room dereverberation in the context of smart houses are still relatively new. The idea of using very few microphones, as opposed to large arrays, is an even more novel approach. Therefore, the research presented in this thesis is still at a very early stage. Although some of the results are mixed, some of them—especially in the three microphone cases— are also very encouraging.
Putting issues of cost aside, the results may seem to suggest that using many microphones would solve the problem. However, the results presented in [6] show that even with 46 microphones, the word recognition error rate was slightly over 50%. Note that the test environments and methods were different from those of this thesis, so there is no way to compare the relative performances. The point here is that using many
microphones alone would not solve the problem at hand. A lot more needs to be done, and the next section addresses some of these open areas.
5.2 Future Work
This section raises and reiterates some issues that are related to echo cancellation applied to the problem of speech recognition in home networking. However, it is by no means a complete analysis of the requirements for making smart houses a reality.
5.2.1 Testing in Real Echo Environments
Although Cool Edit Pro does a good job of simulating room echo environments, it does have certain limitations, as mentioned in Section 3.2. Also, it is hard to specify
5.2.2 Types of Microphones
Also mentioned in Section 3.2 is the fact that Cool Edit Pro’s simulation is based on omni-directional microphones. Other choices may be more suitable in the overall performance of speech recognition in the home environment. A good guide to microphones can be found at http://www.audio-technica.com/guide/type/index.html.
5.2.3 Microphone Placement
Optimal sensor placement is another large area of study, and it takes into consideration the acoustic characteristics of a room. Also, for smart houses, the
placement of the microphone(s) depends on the layout of the room and the objects in it, as well as the likelihood of people facing certain directions.
5.2.4 Real Time
For smart houses to be practical, the echo cancellation system has to work in real time. The work in this thesis was done using Matlab v5 on a Windows NT, Pentium III 450 MHz, 128 MB RAM system, with mainly the echo cancellation capabilities of the algorithms, rather than speed and efficiency, in mind. The next step may be to improve and optimize the algorithms, translate them to DSP assembly code, and run them on a DSP processor.
On a related note, other classes of algorithms that are not practical under the current development platform, such as adaptive processing, may also be considered, if a real time development platform is used.
5.2.5 Continual or Rapid Speaker Movement
Although it is not likely that a person will move very much while giving a
command to the house, in the ideal vision of smart houses it is desirable that there will be no restrictions on the person’s movements. In a more immediate sense, it is also true that even if the person moves a little, the multipath echoes change, so that the current
assumptions, though valid, are not perfect. Therefore, it will be worthwhile to explore methods of quickly tracking the speaker’s movements.
5.2.6 Multiple Speakers
As mentioned in Section 1.2.3, this is yet another area of study (specifically, BSSD) that is relevant to home networking. Although it is not directly dealing with echo cancellation, it is necessary in order to make speech control of home networks realistic, since undoubtedly, there will be more than one person speaking at some point.
5.3 Final Thoughts
After all is said and done, the fundamental question that remains is, “Will this really work in practice?” The answer is, “It depends.” As mentioned before, the performance of echo cancellation algorithms is very sensitive to the echo environment. Therefore, while voice control of the home network may work very well in the living room, it may not work nearly as well in the basement.
It is also important to realize that while echo cancellation, noise cancellation, and other forms of speech enhancement are essential to successful speech recognition, recognition errors can occur even on clean speech. Furthermore, developing a truly “smart” speech interface that can understand humans beyond a limited vocabulary is another great challenge in the field of artificial intelligence research. Therefore, while it is reasonable to expect some basic functional form of smart houses to emerge in the near future, the truly smart house (a la The Jetsons) is still a long way from becoming reality.
Appendix A
The Complex Cepstrum
Using the complex cepstrum to cancel out echoes is also known as homomorphic deconvolution. In general, homomorphic systems are nonlinear in the classical sense, but through the combination of different operations, they satisfy a generalization of the principle of superposition [10]. The complex cepstrum, in particular, “changes” convolution into addition, with the aid of the Fourier Transform and logarithms. The following block diagram illustrates how the complex cepstrum of a signal is derived:
Figure A-1: Block diagram of the complex cepstrum
The complex cepstrum ŝ[n] is therefore defined as IDTFT(log(DTFT(s[n]))).
To see why this changes convolution into addition, lets look at a signal x[n], such that
x[n] = s[n]*h[n] (A.1)
where * denotes convolution. Now, lets follow through with the calculation of the complex cepstrum:
s[n] DTFT S(w) log Ŝ(w) Inverse
X(w) = S(w) • H(w) (A.2)
log(X(w)) = log(S(w)) + log(H(w)) (A.3)
) w ( Xˆ = Ŝ(w) + Ĥ(w) (A.4) [n] hˆ [n] sˆ [n] xˆ = + (A.5)
The next step is to show that the spikes in xˆ[n] do indeed belong to ĥ[n]. Let’s look at the impulse response of a simple echo with delay δ and attenuation factor α (which may be positive or negative) :
h[n] = δ[n] + α •δ[n-d] (A.6)
Taking the Fourier Transform yields
H(w) = 1 + α • e-jwd (A.7)
Taking the logarithm gives
Ĥ(w)= log(1 + α • e-jwd ) (A.8)
Generally, the direct path signal will be greater than the echoes in amplitude, so it is valid to assume that |α| < 1. However, if this is not true, because of some strange room
the unit circle. Given |α| < 1, the right side of Equation A.8 can be approximated as follows by using the power series expansion:
Ĥ(w) = - jwdn 1 n n e n ) ( − ∞ =
å
−α (A.9)Since the DTFT is defined as
X(w) = jwn n e ] n [ x − ∞ −∞ =
å
, (A.10) and change of variables m = dn yieldsjwm d m d m e d m ) ( ) w ( Hˆ ∞ − =
å
− − = α , (A.11)it then follows that
ï ï î ï ï í ì < ≥ − − = d m 0, d m , d m ) ( ] m [ hˆ d m α (A.12)
Finally, substituting back for m gives the following result:
ĥ[dn] = ïî ï í ì < ≥ − − 1 n 0, 1 n , n ) ( α n (A.13)
Therefore, ĥ[n] contains exponentially decaying impulses at every integer
multiple of d. By zeroing out these spikes and then taking the inverse complex cepstrum, the result of applying the MPD algorithm is an estimated version of s[n]. For multiple echoes, the math generally becomes much more complicated, but the presence of
impulses at multiples of each echo’s delay is still observed. For further discussions of the complex cepstrum, refer to [10] and [12].
Appendix B
Matlab Functions
The functions coded can be broken down into three subcategories: test, algorithm, and support. The algorithm functions were already listed and described in Section 2.2. Note that through the course of the thesis work, many functions were coded and later changed or discarded. This accounts for the numbers that appear at the end of some of the function names. The first two subsections of this appendix will a high level explanation of the test and support functions, and the third section will include the source code for all of the functions.
B.1 Test Functions
Test functions, as their name suggests, are used to automate testing. While they test different functions, they all do basically the same things:
- open the appropriate clean original files
- open the unprocessed files (or create them in the simple model tests)
- create the appropriate output directories for the new files created/to be created - process the unprocessed speech
- find the SNR of the processed files* - write the results to a text file
- write the processed speech to new files (also write the new unprocessed speech created in test_simple)
Here’s the list of the test functions:
• test_c2i(path, template)
path = output directory path, excluding the “test_c2i” part template = filename template
ex: if input files are *tr5_m1.wav, then the template is “tr5_m1” and output files are *tr5_m1_c2i.wav
• test_c2is(room)
room = name of test room, for instance, “tr5” refers to the low echo room configuration
• test_mpd2(path, template) • test_multi(room)
Tests DSA, MPDs, MPDs2, MPDs3, SCP • test_simple(alpha, delay)
alpha = vector of attenuation(s) of the echo(s) to be added delay = vetcor of delay(s) of the echo(s) to be added
B.2 Support Functions
• addecho2wav(A, alpha, delay) f = addecho2wav(A, alpha, delay) A = wave vector
Check to make sure that alpha and delay are the same size, iterate through the alpha and delay vectors to create the echoes and add them to A, return the sum f.
• allpass(A)
ap = allpass(A) returns only the all pass component of the vector A
[ap, mp] = allpass(A) returns both the all pass and the minimum phase components of A
• deconvolve(x, h) s = deconvolve(x, h) x = unprocessed signal
h = impulse response (actual or estimated)
Assume x = s*h, deconvolve h from x using FFT’s. If FFT(h) contains a sample with the value 0, the built in Matlab function deconv(x, h) is called.
• delay(A, d) f = delay(A, d) A = a column vector d = delay factor
Returns a version of A, delayed by d samples, through zero padding the first d samples.
• findpeaks2(A, b, e, N, alpha) f = findpeaks2(A, b, e, N, alpha) A = cepstral domain vector b = begin
e = end
N = frame size
alpha = threshold factor
Finds large positive and negative spikes in A(b:e) and zeros them out, returns the altered cepstrum. A(b:e) is cut up into consecutive frames of size N. At any given time, the maxima of three consecutive frames are compared. To get rid of positive peaks, if max(frame i) > alpha*mean(max(frame i-1), max(frame i+1)), then the value at max(frame 2) is set to 0. A similar rule is used to get rid of the negative peaks. The process is iterative for i = 2 : (# of frames – 1). Used by C2I.
• mixdown(room)
room = name of test room, for instance, “tr5” refers to the low echo room configuration
Adds the inputs from the three microphones (generated by Cool Edit Pro), divide by three, and write the new sound vector into a .wav file.
• mse(s, x) m = mse(s, x) s = original signal
x = processed or unprocessed signal
Takes the difference between s and x, square the components of the difference vector, take the sum of the vector, and return the result as the mean squared error.
• rfindpeaks(A, b, e, N, alpha)
Recursive version of findpeaks2, continues to call itself until no peaks are detected. Used by MPD2.
• snr(s, x) f = snr(s, x) s = original signal
x = processed or unprocessed signal
Returns the signal to noise ratio of x, given that s is the clean version of it. The method is easily explained with the source code:
s = s-mean(s); %subtract DC components x = x - mean(x);
S = sum(s.^2); %energy of s X = sum(x.^2); %energy of x
r = (S.^2)/(S.^2-X.^2); % signal to noise ratio, denominator is the noise % energy
• wavplay2(v)
v = sound vector with sampling rate of 22050 samples/second
![Figure 2-4: Complex cepstrum from Figure 2-1, after the spikes were taken out, using MPD 0 1 2 3 4 5 6 7 8 9 x 10 4−0.2−0.100.10.20.30.40.50.6[s/22050]](https://thumb-eu.123doks.com/thumbv2/123doknet/13801180.441113/16.918.242.682.107.486/figure-complex-cepstrum-figure-spikes-taken-using-mpd.webp)