Exploring New Search Algorithms and Hardware for Phylogenetics: RAxML Meets the IBM Cell
16
0
0
Texte intégral
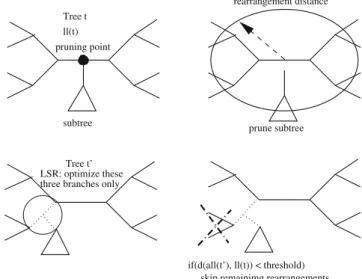
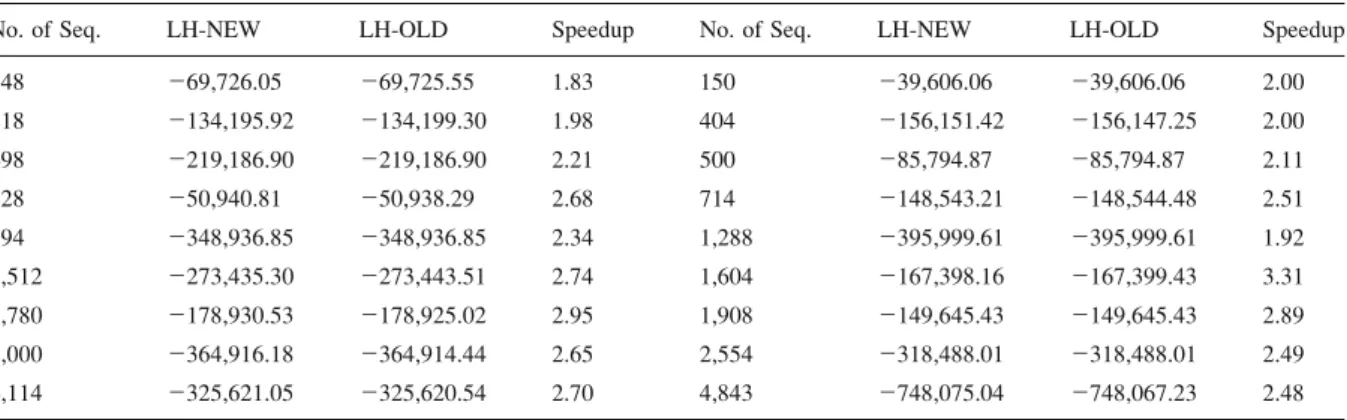
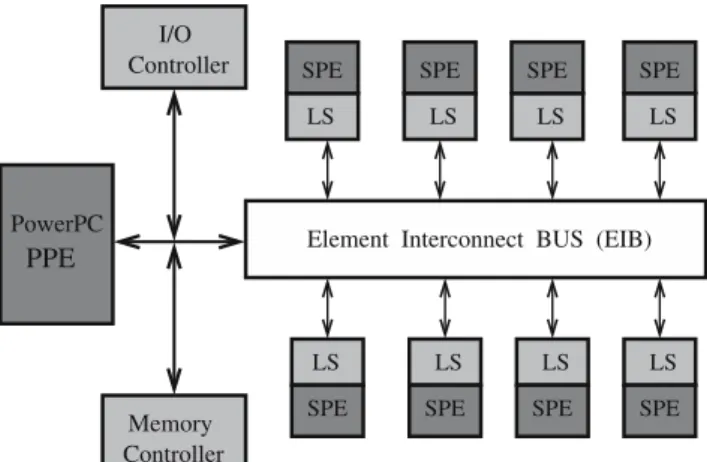
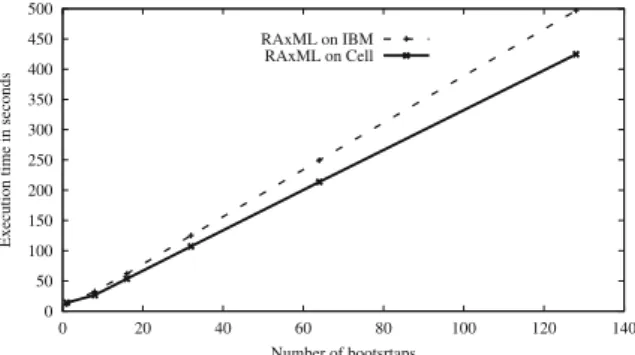
Figure

+7





Documents relatifs