Dewey
HD28
.M414
HO,
WORKING
PAPER
ALFRED
P.SLOAN
SCHOOL
OF
MANAGEMENT
Context
Interchange:
Overcoming
the
Challenges
of Large-Scale
Interoperable
Database Systems
in
a
Dynamic
Environment
February1994
WP#
3658-94CISL
WP#
94-01Cheng
Hian
Goh
StuartE.Madnick*
MichaelSieeel**MASSACHUSETTS
INSTITUTE
OF
TECHNOLOGY
50
MEMORIAL
DRIVE
CAMBRIDGE,
MASSACHUSETTS
02139
Context
Interchange:
Overcoming
the
Challenges
of Large-Scale
Interoperable
Database Systems
in
a
Dynamic
Environment
February1994
WP#
3658-94CISL
WP#
94-01Cheng
Hian
Goh
StuartE.Madnick*
MichaelSiegel**
StuartMadnick,E53-321 SloanSchoolof
Management
MassachusettsIristitute ofTechnology
Cambridge,
MA
02139 MichaelSiegel,E53-323 Sloan SchoolofManagement
MassachusettsInstituteofTechnology
M.I.T.
LIBRARIES
MAR
2
41994
Context
Interchange:
Overcoming
the
Challenges
of
Large-Scale Interoperable
Database
Systems
in
a
Dynamic
Environment*
Cheng
Hian
Goh
Stuart
E.Madnick
Michael
D. SiegelSloan School
ofManagement
Massachusetts
Institute ofTechnology
Abstract
Research in database interoperability has primarily focused on circumventing schematic
and semantic incompatibility arising from
autonomy
ofthe underlying databases.We
ar-gue that, while existing integration strategies might providesatisfactory support for small
or static systems, their inadequacies rapidly
become
evident in large-scale interoperabledatabase systems operating in a dynamic environment.
The
frequent entry and exit ofheterogeneous interoperating agents renders "frozen" interfaces (e.g., shared schemes)
im-practical and places an ever increasing burden on the system to accord
more
flexibility toheterogeneoususers. User heterogeneity mandatesthat disparate users' conceptual models and preferences must be accommodated, and the emergence of large-scale networks sug-gests that the integration strategy must be scalable and capable ofdealing with evolving
semantics.
As analternative tothe integration approaches presented in theliterature,
we
propose astrategy basedon the notion ofcontext interchange. Inthe context interchange framework,
assumptions underlying the interpretations attributed to data are explicitly represented
in the form of data contexts with respect to a shared ontology.
Data
exchange in thisframework is accompanied by context mediation whereby data originating from multiple source contexts isautomatically transformed tocomplywiththe receiver context.
The
focus on data contexts givingrise to data heterogeneity (as opposedto focusing ondataconflictsexclusively) has a
number
of advantages over classical integration approaches, providinginteroperating agents with greater flexibility as well as a framework for graceful evolution and efficient implementation of large-scale interoperabledatabase systems.
Keywords:
contextinterchange,heterogeneous databases, semanticinteroperability,sharedontology.
'This research issupported in part by
NSF
grant IRI-90-2189,ARPA
grant F30602-93-C-0160, the Productivity From Information Technology(PROFIT)
project, and the International Financial Services1
Introduction
The
lastdecade
or so have witnessed theemergence
ofnew
organizational forms (e.g., adhocra-ciesand
virtualcorporations)which
arecriticallydependent
on
theability to share informationacross functional
and
organizational boundaries [21].Networking
technologyhowever
providesmerely physical connectivity:
meaningful
data
exchange
(or logical connectivity) can onlybe
realized
when
agents are able to attribute thesame
interpretation todata
being exchanged.The
quest for logical connectivity hasbeen
amajor
challenge for thedatabase researchcommunity:
there has been, in the short
span
of a few years, a proliferation of proposals forhow
logicalconnectivity
among
autonomous and
heterogeneous databasescan be
accomplished.The
body
ofresearch describing these endeavors have
appeared under
various headings in different places: for instance, "heterogeneous database systems" [28], "federated database systems" [33],and
"multidatabase systems" [5]. In this paper,
we
use the generic phrase "interoperable databasesystems" to
encompass
all of these usage inreferring to acollection ofdatabasesystems
(calledcomponent
database systems)which
are cooperating to achieve various degrees of integrationwhile preserving the
autonomy
ofeachcomponent
system.The
autonomous
design,implementation
and
administrationofcomponent
databasesbringsabout
theproblem
of heterogeneity: system heterogeneity refers to non-uniformity indata
models,
data manipulation
language, concurrency controlmechanisms, hardware and
softwareplatforms,
communication
protocolsand
such; data heterogeneity refers tono
n-uniformity inwhich data
is structured {schematic discrepancies)and
thedisparate interpretations associatedwith
them
[semantic discrepancies) [28]. Conflicts arisingfrom system
heterogeneity are oftenseenas
surmountable through
theprovision of "wrappers"which
provides forthe translation ofone
protocol into another;on
the other hand, theproblem
ofdata
heterogeneity ismuch
more
intractable
and
hasbeen
amajor
concernamong
the database researchcommunity
[5,28.33]. This in turn has led to a variety ofresearch prototypesdemonstrating
how
issues arisingfrom
schematic
and
semantic heterogeneitycan
be
resolved [1,3,4,6,8,14,18,23].^This
paper stems from
our concern for the inadequacies of existing integration strategieswhen
applied to the construction of large-scalesystems
in adynamic
environment,an example
of
which
is the IntegratedWeapons
System
Data
Base
(IWSDB)^
[41]. For thepurpose
of our discussion,
we
characterize adynamic
environment
tobe one
inwhich
heterogeneousmteroperatmg
agents,which
include data sources (i.e., databasesand
data
feeds)and
data receivers (usersand
applications accessing data),may
join or quit thesystem
over time. This has anumber
of implications. First, because the requirements ofdata
receivers are diverse(a fact
which
we
refer to as receiver (or user) heterogeneity)and can change
rapidly, it isimpractical for
data
requirements tobe
capturedand
"frozen" (e.g., in shared schemes): i.e.,'Surveys ona wideselection ofprototype implementations can befound in [5,7,33].
^The
IWSDB
is a project aimed at providing integrated access tothe databases supporting the design andengineering of the F-22 Advanced Tactical Fighter. The
IWSDB
spans databases containing informationontechnical specifications, design, manufacturing, and operational logistics.
Work
on the F-22 began in 1992, andthe
IWSDB
isexpected to operate to the year 2040. ,\sof March 1993, morethan 50 databases have alreadybeenidentified, and thisnumber isexpected togrow greatly as moresub-contractorsarebeing brought into the process.
data
receiversmust
be
given the flexibility of definingwhat
theirdata
needs are dynamicallv. Second,large-scaledynamic
systems introduceconsiderablecomplexityand
accentuate the need for betterperformance
inmanaging
system
development, availabiUtyand query
processingsincemediocre
solutions are likely tobe
felt with greater impact.The
goal of thispaper
is to highlight theabove
concernsand
to illustratehow
they can beovercome
in the context interchangeframework.
The
notion of context interchange in a source-receiver systemwas
firstproposed
in [34,35]. In particular, it hasbeen
suggested thatthe context ofdata sources
and
receiverscan be encoded
using meta-attributes. In thesame
spirit as Wiederhold'smediator
architecture [40], Siegeland
Madnick
[35] suggested that acontext mediator can
be
used tocompare
thesource (export)and
receiver (import) contexts tosee if there are
any
conflicts. Sciore, Siegeland
Rosenthal [29] haveproposed
an
extension toSQL,
calledContext-SQL
(C-SQL)
which
allowsthereceivers'import
context tobe
dynamicallyinstantiated in
an
SQL-like query. Hence, theimport
context canbe
conveniently modified to suit the needs ofthe user in difl["erent circumstances.A
theory ofsemantic values as a basis fordata exchange
has alsobeen proposed
in [30]. Thiswork
defines a formal basis for reasoningabout
conversionofdata
from one
context toanotherbasedon
contextknowledge
encoded
using meta-attributesand
a rule-based language.Our
contribution in thispaper
isan
integration of these resultsand
the generalization to the scenariowhere
there are multipledata
sourcesand
receivers.
The
rest of thispaper
is organized as follows. Section 2 lays the foundation for subsequentdiscussion
by examining both
the classical concerns (i.e., over schematicand
semantic hetero-geneities)and
the strategies for addressing them. Section 3 presents the issues pertinent tolarge-scale
and dynamic
interoperablesystems which
to-datehave received little attentionfrom
this research
community.
Section 4 describes the context interchangeframework,
discusses the rationale underlying its design,and
contrasts it with othercompeting
integration strategies.Section 5
summarizes
our contributionand
describeswork
in the pipeline.2
Interoperable
Database
Systems: Current
Issues
and
Strate-gies
Research in interoperable database
systems
hastraditionally focusedon
resolvingconflictsaris-ing
from
schematicand
semantic heterogeneities. This section ofthepaper
serves to elaborateon
these concernsand
gives a briefoverview ofthe different strategiesproposed
forovercoming
them.2.1
Schematic
and
Semantic
Heterogeneities
Site
autonomy
—
the situationwhereby
eachcomponent
DBMS
retainscomplete
control overdata
and
processing—
constitutes theprimary
reason forheterogeneousschema
and
semanticsof
data
situated in different databases. In the rest of this subsection,we
willenumerate
some
ofthe
most
commonly
occurring conflicts belonging to thetwo
genre.Database la
is
needed
todetermine
how much money
the investor (Database 2b)made
as ofJanuary
13,1994, using theinformation
from
thetwo
databasesshown.
A
few oftheproblems
are discussed below.Naming
conflicts similax tothose corresponding to schematic heterogeneitycan
occur at thesemantic level: in this case,
we
can havehomonymns
and
synonyms
of values associated withattributes. For example, different databases in Figure 2
might
associate adifferent stockcode
with the
same
stock (e.g.,SAPG.F
versusSAP
AG).
(Where
the conflict concerns the key oridentifier for a particular relation, this leads to the
problem sometimes
referred to as the mter-database instance identificationproblem
[38].)Measurement
conflicts arisefrom data
being represented in different units or scales: for example, stock pricesmay
be
reported in differentcurrencies (e.g.,
USD
ormarks) depending on
the stockexchange on which
a stock trade occurs.Representation conflicts arise
from
differentways
in representing values, such as the disparate representations of fractional dollar values inDatabase
2a (e.g.,5\05 on
theNew
York
StockExchange
actuallymean
5^
or 5.3125).Computational
conflicts arisefrom
alternativeways
tocompute
data. For example, although "Price-to-Earnings Ratio"(PE)
shouldjustmean
"Price"divided
by
"Earning", it is not always clearwhat
interpretation of "Price"and
"Earning" are used. Also, in the Reuters interpretation,PE
is not definedwhen
"Earnings" are negative.Confounding
conflictsmay
resultfrom
having different shades ofmeanings
assigned to asingleconcept. For example, the price of a stock
may
be
the "latest closing price" or "latest trade price"depending
on
theexchange
or the time of day. Finally, granularity conflicts occurwhen
data
are reported at different levels of abstraction or granularity. For example, the valuescorresponding to a location (say, of the stock exchange)
may
be
reported tobe
a country or acity.
2.2
Classical
Strategies
forDatabase
Integration
In the last couple of years, there has
been
a proliferation of architectural proposalsand
re-search prototypes
aimed
at achieving interoperabilityamongst autonomous
and
heterogeneousdatabases.
One
approach
for distinguishing the various integration strategies isby
observingthe strength of
data
coupling at theschema
level. This hasbeen
the basis for thetaxonomy
presented in [33],
which
we
will describe briefly below.•
An
interoperable databasesystem
is said tobe
tightly-coupled ifconflicts inherent in thecomponent
databases are resolved, a priori, inone
ormore
federated schemas.Where
there is exactly
one
federatedschema,
this issometimes
referred to as a globalschema
multidatabase system; otherwise, it is called a federated database system.
With
this approach, users of thesystem
interact exclusively withone
ormore
federatedschemas
which mediate
access to the underlyingcomponent
databases.The
notions underlying this strategy has its rootsfrom
the seminalwork
ofMotro
and
Buneman
[22]and
Dayaland
Hwang
[9]who
independentlydemonstrated
how
disparate databaseschemas
canbe
merged
toform
a unified schema, forwhich
queries canbe
reformulated to acton
the constituent schemas.
Examples
of tightly-coupledsystems
includemost
of the early research prototypes, such as Multibase [14],and Mermaid
[36].•
Advocates
of loosely-coupledsystems
on
the otherhand
suggested that amore
generalapproach
to thisproblem
consists ofproviding users with a multi-database manipulation language, richenough
so that usersmay
easily deviseways
of circumventing conflictsinherent in multiple databases. For example, users of the
system
may
define integrationrules (e.g., a table
which
decideshow
tomap
letter grades to points) as part of the query.No
attempt
ismade
at reconciling thedata
conflicts ina
sharedschema
a priori.The
MRDSM
system
[18] (which is part of theFrench
Teletel project atINRIA)
is probablythe
best-known
example
of a loosely-coupled system.In
most
instances, the tightly-coupledsystems
surveyed in [33] focus almost exclusivelyon
the issue ofschematic heterogeneity
and
therewas
littlesupport
(ifany) for circumventingcon-flicts arising
from
semantic heterogeneity. Loosely-coupled systems, such asMRDSM,
attempt
to
remedy
this deficiencyby
providing language features for renaming,data
conversions,and
dealing with inconsistent
data
[17]. Unfortunately, the efficacy of thisapproach depends on
users having
knowledge
of the semantic conflicts: support for conflict detectionand
resolutionwas
either lacking oraccomplished
insome
ad hoc
manner.
These
observationswere
largely responsiblefor theemergence
ofa
number
ofexperimental prototypesaimed
at achievinginter-operability at the semantic level.
We
observedthrough
our survey of the literaturetwo
genreof systems: the first adopting
an
object-orienteddata
model
as a basis for integration,and
the second, a
knowledge
representation language.These
newcomers
share acommon
feature: the ability to interoperate at the semantic level is derivedfrom
the adoption ofamuch
richer language(compared
to the earlier generation)which
provides for semantic reconciliation.We
will briefly describe eachapproach
below.Object-oriented multidatabase systems advocate the adoption of
an
object-orienteddata
model
as the canonicalmodel which
serves asan
inter lingua for reconciling semantic dis-crepanciesamongst
component
database systems.Examples
of thesesystems
includePega-sus [1],
Comandos
IntegrationSystem
(CIS) [4], DistributedObject
Management
(DOM)
[6],FBASE
[23]and
others.**With
this approach, semantic interoperability isaccomplished
viathe definitionofsupertypes, the notionof
upward
inheritance,and
theadoption ofuser-definedmethods.
Consider, for instance, the following granularity conflict: in the first database, a student's grade is represented as a letter grade; in the second, the corresponding information isrepresented aspoints in therange to 100. In the
Pegasus
system
[1], integration is achievedby
introducing a supertype of the
two
types, allowing all attributes ofthe subtypes tobe
upward
inherited
by
the supertype,and
attachinga
method
to the supertype to provide the necessaryconversion:
create
supertype
Studentof
Studentl, Student2:create function
Score(Student x)->
real r asifStudentl(x)
then
Mapl(Grade(x))
else ifStudent2(x)
then
Map2(Points(x))else error;
In the
above
example,Mapl
and
Map2
implement
the conversionswhich must
taJce place to transformdata
from
different representations into acommon
one.We
contend
that as powerful as object-orienteddata
models
may
be, thisapproach
has anumber
of inherent weaJcnesses. First, procedural encapsulation of the underlyingdata
se-mantics (as
demonstrated
in theabove example)
means
that underlying data semantics willno
longerbe
available for interrogation. For example, once the canonical representation for a student's score is chosen, the user hasno
way
offindingwhat
the original representations inthe
component
databases are. Second, this integration strategy presupposes that there isone
canonical interpretation
which
everyone subscribes to. For example, a particular usermight
prefer to receive the information as letter grades instead of
raw
scores.There
aretwo
ways
of circumventing this: define a
method
which
translates the canonical representation (score)to letter grade, or create a
new
supertype altogether by-passing the old one. Eitherimple-mentation
is clearly inefficientand
entailsmore
work than
necessary. Third, the collection of conflicting representationsfrom
disparate databases intoone
supertypemay
pose aproblem
forthe graceful evolution of the system. For example, the score function
above
would need
tobe
modified each time a
new
database containing student information isadded
to the network.The
approach
taken in database integration using aKnowledge
Representation(KR)
lan-guage
constitutes a novel departurefrom
the traditional approachesand
in fact is largelypi-oneered
by
reseeirchersfrom
the Artificial InteUigence (AI)community.
Two
suchattempts
are the
Carnot
project [8]which employs
theCyc
knowledge
base as the underlyingknowl-edge substrate,
and
theSIMS
project [2,3]which
usesLoom
[20] as the underlyingknowledge
representation language. Integration inthese
KR
multidatabase systems isachieved viathe con-struction of a global semanticmodel
unifying the disparate representationsand
interpretationsin the underlying databases. In this regard, it is analogous to the global
schema
multidatabase systems, except thatwe
now
have a richmodel
capturing not just the schematic details butthe underlying semantics as well. For instance, users of
SIMS
will interact exclusively with thesemantic
model
and
thesystem
takeson
the responsibility of translating querieson
"concepts"(in the semantic
model)
to actual database queries against the underlying databases.Data
resource transparency (i.e., theabilityto pose aquery
withoutknowing
what
databasesneed
tobe
searched) hasbeen
an
explicit design goal ofKR
multidatabase systems.While
thismight be
useful inmany
circumstances, there cire clear disadvantages in not providing userswith thealternative ofselectively defining thedatabases they
want
to access. Inmany
instances(e.g., the financial industry), it is important for users to
know
where
answers to theirquery arederived
from
sincedata
originatingfrom
different sourcesmay
differ in their qualityand
this hasan important impact
in decisionmaking
[39]. In addition,some
ofthe objectionswe
haveforobject-oriented multidatabase
systems
are also true for theKR
multidatabase systems. Forinstance, semantic heterogeneity in these
systems
are typicallyovercome by
having disparatedatabases
map
to astandard
representation in the global semantic model. Thismeans
that,like the case of object-oriented multidatabase systems,
data
semanticsremain
obscure to the userswho
might
havean
interest inthem,
and changing
the canonical representation to suit adifferent
group
of usersmay
be
inefficient.3
Beyond
Schematic
and Semantic
Heterogeneities
Attaining interoperability in a large-scale,
dynamically
evolvingenvironment
presents a host of different issues not addressedby
existing integration strategies. In this section,we
examine
some
of the issueswhich
arisefrom
receiver heterogeneity, the nature of large-scale systems,and
their collectiveimpact
on
the ability ofthesystem
to evolve gracefully.3.1
Receiver Heterogeneity
Previous research in interoperable database
systems
is largely motivatedby
the constraint thatdata
sources in such asystem
areautonomous
(i.e., sovereign)and any
strategy for achievinginteroperability
must
be non-mtrusive
[28]: i.e., interoperabilitymust
be
achieved inways
otherthan modifying
the structure orsemanticsof existing databases tocomply
with
some
standard. Ironically,comparative
little attention hasbeen
given to thesymmetrical
problem
of receiver heterogeneityand
theirsovereignty. Inactual fact, receivers (i.e., usersand
applicationsretriev-ing
data
from one
ormore
source databases) differ widely in their conceptual interpretation ofand
preference fordata
and
are equally unlikely tochange
their interpretations or preferences.Heterogeneity
m
conceptual models. Different usersand
applicationsinan
interoperabledatabase system, being themselves situated in different real world contexts, have different "conceptualmodels"
of the world.^.These
different views of the world lead users to apply differentas-sumptions
in interpretingdata
presented tothem
by
the system. For example, a study of amajor
insurancecompany
revealed that the notion of "net writtenpremium"
(which is theirprimary
measure
ofsales)can have
adozen
ormore
definitionsdepending on
the userdepart-ment
(e.g., underwriters, reinsurers, etc).These
differencescan
be
"operational" in additionto being "definitional": e.g.,
when
convertingfrom
a foreign currency,two
usersmay
have acommon
definition for that currency butmay
differ in their choice of the conversionmethod
(say, using the latest
exchange
rate, or using a policy-dictatedexchange
rate).Heterogeneity
m
judgment and
preferences. In addition to having differentmental
models
of the world, users also frequently differ in theirjudgment
and
preferences. For example, usersmight
differ in their choice ofwhat
databasesto search to satisfy theirquery: thismight be due
to the fact that
one
database provides better (e.g.,more
up-to-date)data than
another, but ismore
costly (in real dollars) to search.The
choice ofwhich
database toquery
is not apparent^This observation is neither novel nortrivial: the adoption of external views in the
ANSI/SPARC
DBMS
architecture is evidenceofitssignificance.and depends on
auser'sneedsand
budget. Usersmight
also differ in theirjudgment
as towhich
databases are
more
crediblecompared
to the others. Instead ofsearching all databases havingoverlapping information content, users
might
prefer to query one ormore
databaseswhich
aredeemed
tobe most
promising beforeattempting
other less promising ones.The
preceding discussion suggests that receiver heterogeneity should notbe
taken lightlyin the
implementation
ofan
interoperable database system. Integration strategies (e.g., the globalschema
database systems)do
so at the peril ofexperiencing strong resistance becauseusers deeply entrenched in their
mental models
will resist being coerced into changing their views of the world. Moreover,some
of these receivers couldbe
pre-existing applicationsand
semantic incompatibility
between
what
thesystem
deliversand
what
the application expects will be disastrous.There
is at leastone attempt
in mitigating this problem.Sheth
and
Larson
[33] haveproposed
thatdata
receiversshouldbe
given the optionoftailoring theirown
externalschemas
much
like external views intheANSI/SPARC
architecture. Thisscheme however
hasa
number
ofshortcomings in a diverse
and
dynamic
environment. Inmany
instances, themechanism
for view definition is limited to structural transformationsand
straight forwarddata
conversionswhich might
notbe adequate
formodeling complex and
diverse data semantics. Moreover, theview
mechanism
presupposes that theassumptions
underlying the receivers' interpretation ofdata
canbe
"frozen" intheschema. Usershowever
rarelycommit
to asinglemodel
ofthe worldand
oftenchange
their behavior orassumptions
asnew
data are being obtained. For example, after receiving answersfrom
a "cheap" but out-dated database, a usermight
decide that the additional cost of gettingmore
up-to-datedata
is justifiable. Encapsulating this behavior ina predefined
view
is probably impractical.Once
again, thisproblem
willbe
accentuated ina
dynamic
environment where
new and
diverse users (with different views of the world) are frequentlyadded
to the system.In brief,
we
take the position that agood
integration strategymust
accord data receivers(i.e., users
and
applications requesting data) with thesame
sovereignty as thecomponent
databases. In other words, users should
be
given the prerogative in defininghow
data shouldbe
retrieved as well ashow
they axe tobe
interpreted.3.2
Scale
A
large-scale interoperable databaseenvironment
(e.g.,one
with threehundred
component
databases as
opposed
to three) presents anumber
ofproblems which
can have serious implica-tions for the viabihty ofan
integration strategy.We
suggest that theimpact
ofscalecan be
felt in at least three areas:
system
development, query processing,and system
evolution.The
first
two
issues are described inthis subsectionand
the last ispostponed
to the next.System
development.From
the cognitive standpoint,human
bounded
rationality dictates thatwe
simply cannotcope
withthe complexityassociated withhundreds
of disparate systems each having theirown
representationand
interpretation of data. Integration strategieswhich
relyschema
approach
to database integration advocates that alldata
conflicts shouldbe
reconciledin a single shared
schema.
Designing a sharedschema
involvingn
differentsystems
thereforeentails reconciling
an
order of n~ possibly conflicting representations. Clearly, the viability ofthis
approach
is questionablewhere
thenumber
ofdatabases tobe
integratedbecomes
large.Multidatabase
languagesystems
represent theotherextreme
since there areno attempts
atresolving
any
of thedata
conflictsapriori.However,
itappears
that theproblem
did notsimply goaway
but is instead being passeddown
to the users of the system. Instead ofattempting
to reconcile all conflicts a priori in a shared
schema,
the multidatabase languageapproach
delegates completely the task of conflict detection
and
resolution to the user.The
problem
then
becomes
much
more
pronounced
since usersdo
not necessarily have access to underlyingdata
semantics nordo
they necessarily have the timeand
resources to identifyand
resolve conflictingdata
semantics.Query-processing.
A
key concern for databases has alwaysbeen
that ofefficientquery
process-ing. Large-scale interoperable database
systems
have the potential ofamplifyingpoor query
responses in a
number
of ways. In a smalland
controlled environment, it is often possible for "canned" queries tobe
carefully handcraftedand
optimized.Such an approach
againwould be
impractical in large (and especially,
dynamic)
environments. In addition, large-scalesystems
tend also to
be
more
diverseand
this is certain to lead to greaterdata
heterogeneity.This
implies that conversions
from one data
representation to another willhave
to be frequentlyper-formed. In those instances
where
integration is achievedby
having eachcomponent
databasesystem
mapped
to a canonical representationwhich
may
thenbe
converted to the representa-tionexpectedby
the receiver, this entailsagreat deal ofredundant work which can
significantlydegrade system
performance. In addition, the encapsulation ofdata
semantics in these con-version functionsmeans
that they willremain
inaccessible for taskssuch
as semanticquery
optimization.
3.3
System
Evolution
Changes
inan
interoperabledatabase system can
come
intwo
forms: changes insemantics (of acomponent
database
or receiver)and
changes in thenetwork
organization (i.e.,when
anew
component
database isadded
oran
oldone removed from
the system).Structural changes. For integration strategies relying
on
shared schemas, frequent structuralchanges
can have
an
adverse effecton
thesystem
since changes entail modifications to theshared
schema.
As
we
have
pointed out earlier, thedesign ofa sharedschema
is a difficult task especiallywhen
there is a largenumber
ofcomponent
systems. Modifications to the sharedschema
suffersfrom
thesame
difl[iculties as insystem
development,and
insome
cases,more
sobecause
thesystem
may
have toremain
onlineand
accessible to geographically dispersed usersthroughout
the day.Domain
evolution.Changes
indata
semanticshave
a
more
subtleeffecton
the system.Ventrone
and
Heiler [37] referred to thisasdomain
evolutionand
havedocumented
anumber
ofexamples
why
thismay
occur. Sincewe
expect these changes tobe
infrequent (at least with respect toa single database), the
impact
ofdomain
evolutionon
small or stable interoperable database systems is likely tobe
insignificant. Thishowever
isno
longer truefor large-scale systems,sincelarge
numbers
of infrequent changes in individual databasesadds
up
to formidable recurring events at thesystem
level. For example,assuming an
average ofone change
in three years forany
given database,an
interoperable databasesystem
with threehundred
databases will have tocontend
with 100 changes every year,which
translates totwo
changes every week!Domain
evolution has significant
impact
for integration strategieswhich
relyon
prior resolution ofsemantic conflicts (e.g., object-oriented multidatabase systems) since semantic changes entail
modifying
definitions of types (and corresponding conversion functionsembedded
in them). Consider forinstance,when
databases reportingmonetary
values in French francs are requiredto switch to
European
Currency
Units(ECUs).
Thischange
will requiremodifying
all typedefinitions
which
havean
attributewhose
domain
(insome component
databases) isa monetary
value reported in French francs. Since there
might
be
severalhundreds
of attributes havingmonetary
value as itsdomain,
it is nothard
to imaginewhy
achange
like thiswould
have direconsequences
on
the availabilityand
integrity ofthe system.4
The
Context
Interchange
Framework
The
key to the context interchangeapproach
to achieving interoperability is the notion of context.We
use theword
"context" to refer to the (implicit)assumptions
underlying theway
in
which
an
interoperating agent routinely represents or interprets data.Data
contexts, likeevent scripts [31], are abstraction
mechanisms
which
allow us tocope
with the complexities oflife. For example,
when
visiting alocal grocery store in theUS,
we
assume
that the priceon
ashelve
with
boxes ofCheerios is reported inUS
dollars, that this price refers to unit price of abox
(ratherthan
say unit price per pound), that "3.40" refers to $3.40and
not 3.4 cents,and
so forth.
Given
sufficient time, groups of individuals will tend to develop sharedassumptions
with respect to
how
one
should interpret thedata
generatedand
owned
by
the group.These
shared
assumptions
are desirablebecause it reducesthe cost ofcommunication
among
members
ofthegroup. In the
same
way, applicationsand
individuals issuing queries to adata repositoryall have their
own
assumptions
as tohow
data
shouldbe
routinely represented or interpreted.All is well
when
theseassumptions
do
not conflict withone
another, as is usually the case ifdatabases, applications,
and
individuals are situated inthesame
social context.When
multiple databases, applications,and
individuals transcending organizational or functional boundariesare brought together in
an
interoperable system, the disparatedata
contexts each brings to thesystem
result inboth
schematicand
semantic conflicts.4.1
Context
Interchange
inSource- Receiver
Systems
We
will first exemplify thekey notions underlying the context interchange strategy as depicted in Figure 3 with a simple scenariowhere
there is onlyone
data source (i.e., a database orsome
otherdatarepository)
and
one data
receiver (an application or userrequesting for data) [34,35].To
allowdata exchange between
the data sourceand
data receiver to be meaningful,data
semanticconflicts. For example, ausermiglithave reasonto believe that
exchange
ratesbetween
two
currencies shouldbe
something
otherthan
what
is currently available to thesystem
and
might
therefore choose to define hisown
conversion routines as part of hisimport
context.4.2
Context
Interchange with Multiple Sources
and
Receivers
The
strategy for achieving interoperability in a source- receiversystem can
be generalized to the scenariowhere
there are multipledata
sourcesand
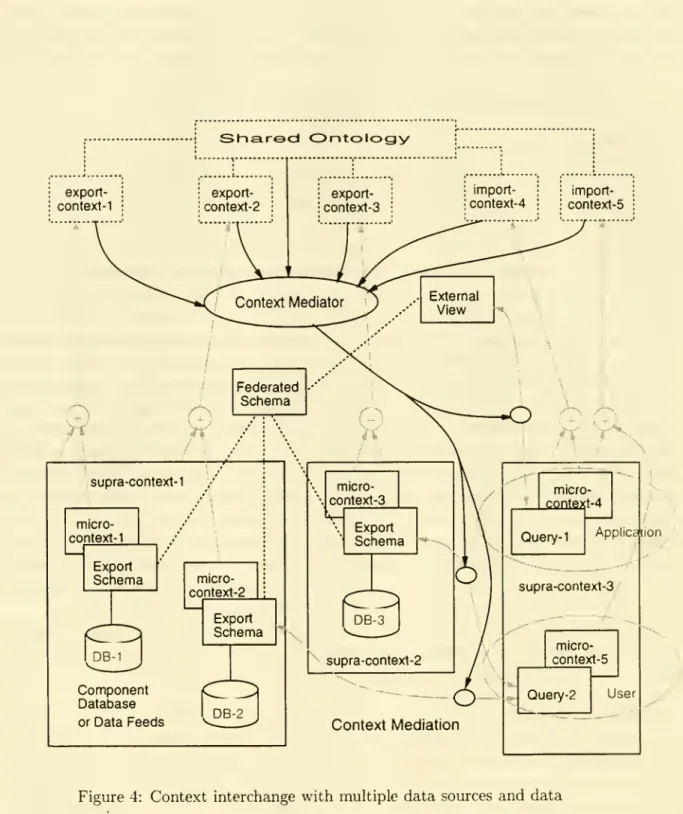
receivers. Figure 4 illustrateswhat
the architecture ofsuch asystem might
look like. This architecture differsfrom
the source-receiverframework
presented in Figure 3 intwo
significant ways. First, becausewe
now
have multipledata
sourcesand
receivers, it is conceivablethat groupsof interoperatingagentsmay
be
situatedin similar social contexts
embodying
largenumber
ofcommon
assumptions.We
exploit this factby
allowingcommonly-held assumptions
tobe
sharedamong
distinct interoperating agents in a supra- context, while allowing the representation of idiosyncraticassumptions
(i.e., thosepeculiar to a particular
data
source or receiver) in individual micro-contexts.The
export orimport context ofeach agent is therefore obtained
by
thesummation
ofassumptions
assertedin the supra-
and
micro-contexts. This nesting ofone
data context in another forms a context hierarchy which, in theory,may
be
of arbitrary depth. Second,we
need
to considerhow
auser
might
formulate aquery spanning
multiple data sources.As
noted earlier,two
distinctmodes
havebeen
identified in the literature: data sourcesmay
be
pre-integrated toform
a federatedschema,
on which one
ormore
external viewsmay
be
definedand
made
available to users, or, usersmay
query
thecomponent
databases directly using their export schemas.We
are convinced that neitherapproach
is appropriate all the timeand
havecommitted
to supportingboth
types of interactions in theproposed
architecture. In each case, however, thecontext
mediator
continues to facilitate interoperabilityby performing
the necessary context mediation. In the rest of this section,we
shall present the rationale underlying the design of theproposed framework,
and
where
appropriate, themore
intricate details of the integrationstrategy.
Om-
concern for user heterogeneity, scalabilityand
the capacity for graceful evolution (seeSection 3) has led us to a
number
of considerationswhich
prompted
the incorporation of the following features in the context interchange architecture.1. Explicit representation of
and
access to underlying data semantics.Instead of reconciling conflicting semantics directly in shared schemas,
we
advocate thatsemantics of
data
underlying disparate data sourcesbe
captured in export contextsinde-pendent
ofthemethod
for reconciling semantic conflicts. This is achievedby
associatingevery
data
element in thedata
source with a semanticdomain
which
has a meaningfulin-terpretation in the shared ontology. For example, instead of defining "Yen"
by
supplying a function for converting a stock pricefrom
Yen
toUSD,
we
suggest that underlyingdata semantics shouldbe
explicitly representedby
first defining in the shared ontology, theconcept
"Yen"
tobe
a kindof currencyand
thatmonetary
amounts
inone
currency canbe
converted into another givenan exchange
rate,and
associating attributestockPrice
with
the semanticdomain
"amonetary
amount
<currency: Yen, unit:thousands>".
Component
Database
orData Feeds Context Mediation
Figure 4:
Context
interchangewith
multipledata
sourcesand
data
receivers.
Representationof
data
semanticsinsemanticdomains
independentofthedatabaseschema
and
theconversion functions used forachieving reconciliation has anumber
ofadvantages. •By
allowing data semantics tobe
defined without the use ofshared schemas,we
areable to support semantic interoperability
even
when
no
integratedschema
exists. •Because
data semantics are represented explicitly (asopposed
to being implicitlv inconversion functions), intensional queries (e.g.,
"What
currency is this data reportedin?") can
now
be
answered.•
More
intelligentquery
processing behaviorcan
now
be
expected ofthesystem
sincewe
no
longercommit
ourselves to a single conflict resolution strategy. Consider for example, thequery
issuedby
aUS
broker (forwhom
all prices are inUSD):
select
stkCode
from
Tokyo-stock-exchange.trade-relwrhere
stkPrice>
10;If
we
have defined the semantics of "Yen" with respect to"USD"
via only a unidi-rectional conversion function (fromYen
toUSD),
this querywould
have lead toan
unacceptable
query
plan (converting all stocks traded inTokyo
stockexchange
toUSD
beforemaking
the selection required).A
more
sensible query plan consists ofconverting 10
USD
to the equivalent inYen and
allowing theDBMS
atTokyo
stockexchange
todo
the selection. This secondquery
plancan be
triviallyproduced by
the context mediator.
The
point here is that convertingfrom one data
representa-tion to another isan
expensive operationand
it payshandsomely
ifwe
can applyknowledge
ofdata
semantics in optimizing these queries.•
Another advantage
ofabstainingfrom
apre-established resolution strategy (i.e., con-version function) is that it allows data receivers todefine (at amuch
later time) theconversion
which
theywish
to use.An
example
we
gave earlier in Section 3 involves users having differentexchange
rates for currency conversion. In this instance, thereis
no one
"right" conversion rate:by
defining theexchange
rate they wish to use in theirimport
context, data receiverscan
customize the behavior of conversionfunctions.
• Finally, the independentspecification ofdata semantics in semantic
domains
provide alevel ofabstractionwhich
ismore
amenable
to sharingand
reuse. Sharing cantakeplax;e at
two
levels. First, semanticdomains can be
sharedby
different attributesin a singledata
source. For example, afinancialdatabasemay
containdataon
tradeprice,issueprice, exercise price, etc, allof
which
refer tosome
monetary amount.
Insteadof reconciling data elements individually with their counterparts (e.g., stock price ofastockin
Tokyo
stockexchange
and
that inNew
York
stockexchange), these attributescan be
associated with a single semanticdomain
("monetary
amount
<currency: Yen, unit:thousands>")
in the export context. Second, context definitionsmay
alsobe
sharedbetween
differentdata
sourceswhich
are situated in thesame
socialcontext. For example,
both
thecommodity
exchange
and
stockexchange
atTokyo
axe likely to
have
similar semantics for all things "Japanese" (e.g., currency, date format, reporting convention). Instead of redefining a conflict resolution strategyfor each database, their
commonality can be
capturedby
allowingthem
to share overlapping portions of their export context.As
mentioned
earlier,we
refer to theportion ofthe context definition peculiar to the individual
data
source as themicro-context,
and
the sharable part of the context definition, the supra- context.2. Explicit source selection subjected to users' preferences.
Instead of constraining
data
receivers to interacting with sharedschemas
(and hencepredetermined
setsofdata
sources),we
consider it imperative that usersand
applicationsshould (if desired) retain the prerogative in determining the databases
which
are to beinterrogated to find the information they need.
Data
receivers in a context interchangesystem
thereforehave
the flexibihty ofqueryinga^federatedschema
(providing transparentaccess to
some
predefined set of databases) or querying the data sources directly.The
two
different scenarios are described below.As
in the case ofSheth
and
Larson's federateddatabase systems
[33], a federatedschema
may
be
sharedby
multipledata
receivers.The
federatedschema
can
alsobe
tailored tothe needs of individual
groups
ofusersthrough
the definition of external views.We
make
no
commitment
to representing or reconciling semantic heterogeneity in these schemas:schemas
existsmerely
as descriptors for database structureand
we
do not definehow
semantic conflicts are tobe
resolved.The
sharedschema
exists as syntactic gluewhich
allow
data
elements in disparate databases tobe
compared
(e.g., stock price inNYSE
database
versus stock price inTokyo
stockexchange
database) butno attempt
shouldbe
made
at defininghow
semantic disparities shouldbe
reconciled. Instead, semanticreconciliation is
performed by
the context mediator at the time aquery
is formulatedagainst the shared
schema.
A
detailed discussion ofhow
this isaccomplished can be
found
later in this section.Direct access to
data
sources in the context interchangesystem
is facilitatedby
making
available the export
schema
of eachdata
source for browsing.Once
again, this exportschema
correspondsdirectly to that in thefive-levelschema
architecture [33],and
depictsonly
data
structurewithout
any attempt
at defining thedata
semantics. In ordertoquery
data
sources directly, trivial extensions to thequery
languageContext-SQL
[29] allowingdirect
naming
of databaseswould
alsobe
necessary.Once
again, the contextmediator
provides for semantic reconciliation
by
identifying the conflictand
initiating the neces-sarydata
conversion. Thisapproach
therefore provides the flexibility of multidatabase languagesystems
without requiring users tohave
intimateknowledge
of underlyingse-mantics ofdisparate databases.
3. Explicit receiver heterogeneity: representation of
and
access to user semantics.Data
receivers in the context interchangeframework
areaccorded with thesame
degreeofautonomy and
sovereignty asdata
sources. In other words, receivers are allowed to definetheir interpretation of
data
inan import
context.As
is the case with export contexts,commonahty
among
groups of users canbe
captured ina supra-context (see Figure 4).Compared
with export contexts, theimport
contextofausermay
be
more
"dynamic":
i.e.,the needs ofa single user can
change
rapidly over time or for a particular occasion; thus,different
assumptions
for interpreting datamay
be
warranted. This canbe
accomplished withContext-SQL
[29]which
allows existing context definitions tobe
augmented
oroverwritten in a query. For example, a stock broker in
US
may
choose to view stock prices inTokyo
as reported in Yen.The
default context definition (which states that prices are tobe
reported inUSD)
canbe
overwritten in thequery
with theincontext
clause:
select
stkCode
from
Tokyo-stock-exchange.trade-relwhere
stkPrice>
1000incontext
stkPrice.currency=
"Yen";This
query
therefore requests for stock codes ofthose stocks pricedabove
1000 Yen.Automatic
recognitionand
resolution (e.g., conversion) ofsemantic conflicts.One
of the goals of the context interchange architecture is topromote
context trans-parency: i.e.,data
receivers shouldbe
able to retrievedata from
multiple sources situated in different contexts without having toworry
about
how
conflictscan be
resolved. Unlike classical integrationapproaches, semantic heterogeneity arenot resolved apriori. Instead, detectionand
resolution ofsemanticconflicts take placeonlyon demand:
i.e., in responseto aquery. This
form
oflazy evaluation providesdata
receivers with greater flexibility indefining their
import
context (i.e., themeaning
ofdata
they expect,and
even conversionfunctions
which
are tobe
applied to resolve conflicts)and
facilitatesmore
efficientquery
evaluation.
Conflicts
between two
attributes canbe
easilydetectedby
virtue ofthefact that semanticdomains
corresponding toboth
attributescan
be
traced tosome
common
concept in theshared ontology. Consider the
query
issuedby
theUS
stock broker to theTokyo
stockexchange
database.The
attributestkPrice
in thedatabase is associated with a semanticdomain
"monetary
amount
<
Currency
=
Yen,Unit=thousands>"
which can be
traced toa concept in the shared ontology called
"monetary amount".
The
import
context of the brokerwould
have definedsome
assumptions
pertaining tomonetary amounts,
e.g.,"monetary
amount
<Currency=USD>".
By
comparing
semanticdomains
rooted in acommon
concept in the shared ontology, discrepancies canbe
readily identified.The
conversion functions for effecting context conversions
can
similarlybe
defined as part of the shared ontology. In ourexample
above, the concept"monetary
amount"
will have afunction which, given
an exchange
rate, convertsan
amount
from one
currency toanother,and
a different conversion function for achieving translationbetween
units.A
more
in-depth
discussion of conversion functions in a context interchangeenvironment
canbe
found
in [30].5.
Conversion
considerationsm
query optimization.As
mentioned
earlier,data
contexts allow disparatedata
semantics tobe
representedin-dependently
ofthe conflict resolutionmechanism,
thus facilitatingmore
intelligentquery
processing.
(An
example
ofwhich
is presented earlier in this section.) Hence, apartfrom
conflict detection
and
reconciliation, the contextmediator can
also playan important
role as a
query
optimizerwhich
takes into account the vastly different processing costsdepending
on
the sequenceofcontext conversions chosen.The
problem
here issufficiently differentfrom query
optimization in distributed databasesand
warrants further research(see [19] for
an
overview of the pertinent issues).As we
have
explained in Section 3, theperformance
gainsfrom
optimization is likely tobe
more
pronounced
in large-scale sys-tems.By
making
data
semantics explicitly available, the context interchange architecture establishes agood
framework
withinwhich
the optimizercan
function.6. Extensive scalability.
The
efficacy withwhich
thecontext interchangearchitecture canbe
scaled-up is aprimary
concern
and
forms
an important
motivation for our work.Our
claim that the context interchangeapproach
provides amore
scalable alternative (tomost
oftheother strategies) isperhaps
bestsupported
by
contrasting itwith
the others.In integration
approaches
relyingon
sharedschemas
(e.g., federateddatabase
systems), designing a sharedschema
involvingn
systems
requires the resolution ofan
order of at least n^ conflicts(assuming
that eachdata
sourcebrings onlyone
conflict to the federated schema). Inmany
instances, thegrowth
iseven
exponential since eachdata
source hasthe potential of
adding
many
more
conflictsthan
n.This problem
is also evident in themore
recent intelligent mediationapproaches proposed
in [26]and
[27] eventhough
these
do
not relyon
shared schemas.We
contend
that these integrationapproaches
areimpractical
when
applied to large-scalesystems
simply because the complexity ofthe taskis
way beyond what
is reasonablymanageable.
The
context interchangeapproach
takeson
greater similarity withKR
multidatabases in this aspect ofsystem
scalability. Hence, instead ofcomparing
and merging
individualdatabases
one
with another,we
advocate
that individual databasesneed
only to definesemantic
domains
corresponding to eachdata
element,and
relating thesedomains
to concepts in theshared ontology (and ifnecessary,augmenting
the latter).This
process isalso facilitated
by
the easewith which
context definitions canbe
shared (e.g., sharing ofsemantic
domains
between
disparatedata
elements in a database,and
sharing of supra-contexts acrosssystem
boundaries).This
ability to share semantic specificationsmeans
thatadding
anew
system
ordata
elementcan
become
incrementally easierby
reusing specificationswhich
are defined earlier.7. Incremental system, evolution in response to
domain
evolution.The
context interchange architecture is predicatedon
the declarative representation ofdata
semantics. Hence,when
data
semantics changes, it ismerely
necessary tochange
thecorrespondingdeclaration.
Sweeping
changes indata
semantics (e.g., allFrenchcompanies
change from
reporting in FYench francs toECUs)
may
require changes toone
ormore
micro-contexts.
However,
insome
instances, a singlechange
in the semanticdomain
orsupra-context
may
be
sufficient.Whereas
inother approaches such changeswould
requireexplicit changes to code, here all changes are declarative. Moreover, thecontext
mediator
automatically selects the conversion as appropriate (see point #4).
8. Sharable
and
reusable semantic knowledge.Given
thattremendous
amount
ofwork
insystem
integration goes into understandingand documenting
the underlyingdomain
(i.e., defining the shared ontology), semanticknowledge
gainedfrom
these endeavors shouldbe
sharableand
reusable. This notion ofconstructing a libraryof reusable ontologies has
been
amajor
endeavor oftheKnowledge
Shairing Effort [24,25] as well as the
Cyc
Project [15,16]''.The
context interchangeapproach
is well poised toboth
takeadvantage
ofthis endeavorand
to contribute to itby
being aparticipant in theconstructionof ontologies for reuse.
Given
sufficient time, theseendeavors can result in sufficient critical
mass which
allow interoperable systems tobe
constructed with
minimal
effortby
reusingand
combining
libraries ofshared ontologies.4.3
Comparison
with
Existing Integration Strategies
We
providea
compcu-isonofthe context interchangeapproach
with otherdominant
integrationapproaches
by
way
of Table 1.We
should point out that the assessment of each strategyis
based on
adherence to the spirit of the integrationapproach
and
thus are notsweeping
statements
about
particular implementations.This
is inevitable since there is awide
spectrum
of implementations in each category of systems, not of all
which
are well described in theliterature.
®The Cyc Project takesona slightly different flavor by advocating theconstruction ofasingle global
ontology representing the "consensus reality" ofa well-informed adult.
E S
d V
-« V
c d
aO
V u bO^-' "0 «ii
JI
5
Conclusion
We
have presented anew
approach
to interoperable databasesystems based
on
the notion ofcontext interchange. Unlike existing integration strategies
which
focuson
resolving schematicand
semantic conflicts,we
have suggested that conflict resolution shouldbe
secondary to theexplicit representationofdisparate
data
semantics. This is achieved in ourframework by
repre-senting theassumptions
underlying the interpretations (attributed to data) inboth
exportand
import
contexts described with reference to a shared ontology.By
decoupling the resolution ofheterogeneity
from
itsrepresentation,we
now
have
amore
flexibleframework
forefficientsystem
implementations
and
graceful evolution especially critical in large-scaledynamic
environments.The
richness ofthis integrationmodel
hasopened
up
awide
rangeofresearch opportunities.We
highlightbelow
some
ofourcurrentendeavors. First,we
recognize that thedesignofashared ontology is acomplex
taskand
there is aneed
for awell-definedmethodology
foraccomplishing this [10]. Thisproblem
manifests itself in otherways
even afterwe
have a stock of ontologiesfor different
domains.
For example,we
would need
to considerhow
different ontologiescan
be
additively
combined and
how
conflicts shouldbe
resolved. Second, thedeferment
of conflictresolution to the time
when
aquery
issubmitted
(asopposed
to resolving thisa
priori insome
sharedschema)
presents great opportunities forquery
optimization. Since transformation ofdata from one
context to anothercan
conceivablybe
a very expensive process, the gainsfrom
a
carefully craftedquery
optimizercan be immense.
This, coupled with other issues pertainingto multidatabase
query
optimization, constitute a difficultproblem
[19].Another
challenge lieswith
the design of a suitable language for queryingboth
the intensionaland
extensionalcomponents
of the system.Context-SQL
providesan
excellent vehicle for userswho
might
be
interested inmodifying
theirimport
contexts dynamically as queries are formulated.More
sophisticated languages
and
interactions areneeded
tosupport
users in querying the ontologyand
in identifying the information resources needed.References
[1]
Ahmed,
R.,Smedt,
P. D.,Du, W.,
Kent,W.,
Ketabchi,M.
A., Litwin,W.
A., Raffi, A.,and
Shan,M.-C.
The
Pegasus
heterogeneous multidatabase system.IEEE
Computer
24,12 (1991), pp. 19-27.
[2] Arens, Y., Chee, C. Y., Hsu, C.-N.,
and
Knoblock,
C. A. Retrievingand
integratingdata from
multiple information sources. Tech. Rep. ISI-RR-93-308,USC/Information
Sci-ences Institute,March
1993.To
appear
in the International Journalon
Intelligentand
Cooperative Information Systems.
[3] Arens, Y.,
and Knoblock,
C. A.Planning
and
reformulating queries forsemantically-modeled
multidatabase systems. In Proceedings of the 1st International Conferenceon
Information