Verifying Programs with Dynamic 1-Selector-Linked Structures in Regular Model Checking
Texte intégral
Figure


Documents relatifs
The main results are a polynomial-time decidability for the equivalence problem in the considered case, and an explicit description of an equivalence-checking algorithm which
The primary underlying aortic pathology for TEVAR was thoracic aortic aneurysm in 53% of patients, and the median time to the development of AOF was 90 days (IQR 30–150).. Definition
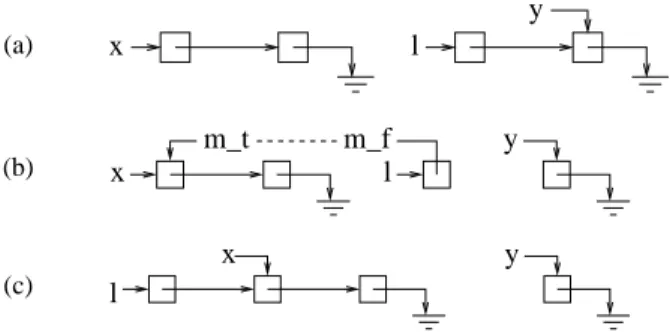
Numerical domains can only abstract directly environments over cells of real type, not pointer type. We abstract each component independently: one cell of integer type is allocated
L’objectif de cette thèse est de développer un modèle multi-agents pour simuler les opérations de manutention et de transfert de conteneurs entre le terminal multimodal
There are several defined abstractions to prove specifications on structured unbounded data and the main focus has been on arrays. In Section 3.2 we transformed arrays to functions
Unit´e de recherche INRIA Rennes, Irisa, Campus universitaire de Beaulieu, 35042 RENNES Cedex Unit´e de recherche INRIA Rhˆone-Alpes, 655, avenue de l’Europe, 38330 MONTBONNOT ST
In this paper, we have presented a new method for generating automatically goal-oriented test data for programs with multi-level pointer variables. The method is based 1) on the
There are two notable examples of prior work which use an explicit-state model checker as a back end, and also directly operate on C/C++ programs, and for which process memory
