A Multi-Agent System to Support Exploiting an XML-based Corporate Memory
Texte intégral
Figure
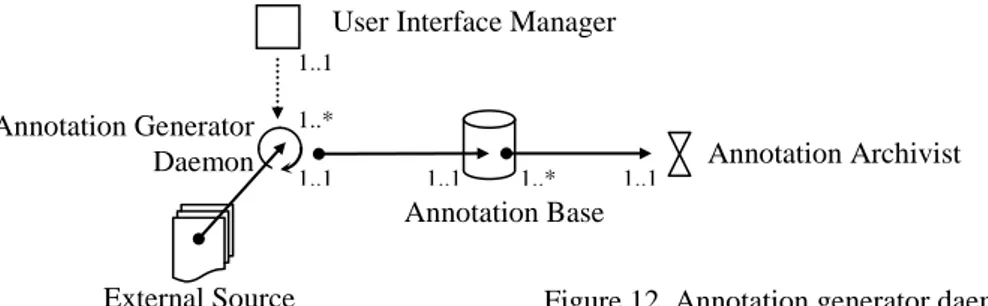
Documents relatifs
Moreover, the symmetric ”gauge” (or the Landau ”gauge”) is not, in fact, a gauge condition but a solution describing a uniform magnetic field under the Coulomb constraint (∇.A 1
maintenance, of the Crown as a brand it was anticipated that such insights would result in a conceptualization of the key elements underpinning its management:
/ La version de cette publication peut être l’une des suivantes : la version prépublication de l’auteur, la version acceptée du manuscrit ou la version de l’éditeur. Access
• Diffuse and share: CSN technology can be a supporting tool for strategic scanning “information diffusion” phase since it allows instantaneous access to
Professor Rosenberg made significant contributions in many other areas of multiple-valued logic, like for example to the theory of partial clones.. We will focus here on one of his
Thanks to the additional information collected also through the travel survey, we want to also understand if the existence of the car-sharing is providing some positive effect on
Forty three percent of farms that used some profit for rent increases knew that some of their landowners had been offered a higher rent outside the corporate
A1. Growth from solutions A1. Inorganic compounds B1. The e ffect of the presence of orthophosphate ions in the super- saturated solution on the kinetics of crystallization of
