Publisher’s version / Version de l'éditeur:
Vous avez des questions? Nous pouvons vous aider. Pour communiquer directement avec un auteur, consultez la première page de la revue dans laquelle son article a été publié afin de trouver ses coordonnées. Si vous n’arrivez pas à les repérer, communiquez avec nous à [email protected].
Questions? Contact the NRC Publications Archive team at
[email protected]. If you wish to email the authors directly, please see the first page of the publication for their contact information.
https://publications-cnrc.canada.ca/fra/droits
L’accès à ce site Web et l’utilisation de son contenu sont assujettis aux conditions présentées dans le site LISEZ CES CONDITIONS ATTENTIVEMENT AVANT D’UTILISER CE SITE WEB.
5th Conference on Machine Translation (WMT), pp. 970-976, 2020-11-19
READ THESE TERMS AND CONDITIONS CAREFULLY BEFORE USING THIS WEBSITE. https://nrc-publications.canada.ca/eng/copyright
NRC Publications Archive Record / Notice des Archives des publications du CNRC : https://nrc-publications.canada.ca/eng/view/object/?id=520de843-ed04-446c-83cc-d121adf6aa90 https://publications-cnrc.canada.ca/fra/voir/objet/?id=520de843-ed04-446c-83cc-d121adf6aa90
NRC Publications Archive
Archives des publications du CNRC
This publication could be one of several versions: author’s original, accepted manuscript or the publisher’s version. / La version de cette publication peut être l’une des suivantes : la version prépublication de l’auteur, la version acceptée du manuscrit ou la version de l’éditeur.
Access and use of this website and the material on it are subject to the Terms and Conditions set forth at
Improving parallel data identification using iteratively refined sentence
alignments and bilingual mappings of pre-trained language models
Improving Parallel Data Identification using Iteratively Refined Sentence
Alignments and Bilingual Mappings of Pre-trained Language Models
Chi-kiu Lo and Eric Joanis Multilingual Text Processing Digital Technologies Research Centre National Research Council Canada (NRC-CNRC) 1200 Montreal Road, Ottawa, ON K1A 0R6, Canada {chikiu.lo|eric.joanis}@nrc-cnrc.gc.ca
Abstract
The National Research Council of Canada’s team submissions to the parallel corpus fil-tering task at the Fifth Conference on Ma-chine Translation are based on two key com-ponents: (1) iteratively refined statistical sen-tence alignments for extracting sensen-tence pairs from document pairs and (2) a crosslingual semantic textual similarity metric based on a pretrained multilingual language model, XLM-RoBERTa, with bilingual mappings learnt from a minimal amount of clean parallel data for scoring the parallelism of the extracted sen-tence pairs. The translation quality of the neu-ral machine translation systems trained and fine-tuned on the parallel data extracted by our submissions improved significantly when compared to the organizers’ LASER-based baseline, a sentence-embedding method that worked well last year. For re-aligning the sen-tences in the document pairs (component 1), our statistical approach has outperformed the current state-of-the-art neural approach in this low-resource context.
1 Introduction
The aim of the Fifth Conference on Machine Trans-lation (WMT20) shared task on parallel corpus filtering is essentially the same as the two previ-ous editions (Koehn et al., 2018b, 2019): identi-fying high-quality sentence pairs in a noisy cor-pus crawled from the web using ParaCrawl (Koehn et al.,2018a), in order to train machine translation (MT) systems on the clean data.
This year, the low-resource language pairs being tested are Khmer–English (km–en) and Pashto– English (ps–en). Specifically, participating sys-tems must produce a score for each sentence pair in the test corpora indicating the quality of that pair. Then samples containing the top-scoring 5M words are used to train MT systems. While using the filtered parallel data to train a FAIRseq (Ott
et al.,2019) neural machine translation (NMT) sys-tem remains the same as last year, the organisers are no longer building statistical machine transla-tion (SMT) systems as part of the task evaluatransla-tion. Instead, as an alternative evaluation, the filtered parallel corpus is used to fine-tune an MBART (Liu et al.,2020) pretrained NMT system. Partic-ipants were ranked based on the performance of these MT systems on a test set of Wikipedia transla-tions (Guzmán et al.,2019), as measured by BLEU (Papineni et al., 2002). A few small sources of parallel data, covering different domains, were pro-vided for each of the two low-resource languages. Much larger monolingual corpora were also pro-vided for each language (en, km and ps). In ad-dition to the task of computing quality scores for the purpose of filtering, there is also a sub-task of re-aligning the sentence pairs from the original crawled document pairs.
Cleanliness or quality of parallel corpora for MT systems is affected by a wide range of factors, e.g., the parallelism of the sentence pairs, the fluency of the sentences in the output language, etc. Pre-vious work (Goutte et al., 2012; Simard, 2014) showed that different types of errors in the parallel training data degrade MT quality in different ways. Cross-lingual semantic textual similarity is one of the most important properties of high-quality sen-tence pairs. Lo et al. (2016) scored cross-lingual semantic textual similarity in two ways, either us-ing a semantic MT quality estimation metric, or by first translating one of the sentences using MT, and then comparing the result to the other sentence, using a semantic MT evaluation metric. At the WMT18 parallel corpus filtering task, Lo et al. (2018)’s supervised submissions were developed for the same MT evaluation pipeline using a new semantic MT metric, YiSi-1 (Lo, 2019) (see also section 2.3). At the WMT19 parallel corpus fil-tering task, Bernier-Colborne and Lo (2019)
ex-ploited the quality estimation metric YiSi-2 using bilingual word embeddings learnt in a supervised manner (Luong et al., 2015) or a weakly super-vised manner (Artetxe et al.,2016).Lo and Simard (2019) further showed that using YiSi-2 with mul-tilingual BERT (Devlin et al.,2019) on fully unsu-pervised parallel corpus filtering achieved similar results to those inBernier-Colborne and Lo(2019). This year, the National Research Council of Canada (NRC) team submitted one system to the parallel corpus filtering task and one to the align-ment task. The two systems share the same com-ponents in scoring the parallelism of the noisy sentence pairs, i.e., the pre-filtering rules and the quality estimation metric YiSi-2. For the parallel corpus aligning task, we use an iterative statisti-cal alignment method to align sentences from the given document pairs before passing the aligned sentences to the scoring pipeline.
Our internal results show that MT systems trained on pre-aligned sentences filtered by our scoring pipeline outperform those trained on the organizers’ LASER-based baseline (Chaudhary et al.,2019) by 0.2–1.4 BLEU. Training MT sys-tems on re-aligned sentences using our iterative sta-tistical alignment method achieve further gains of 0.3–1.8 BLEU.
2 System architecture
There are a wide range of factors that determine whether a sentence pair is good for training MT systems. Some of the more important properties of a good training corpus include:
• High parallelism in the sentence pairs, which affects translation adequacy.
• High fluency and grammaticality, especially for sentences in the output language, which affect translation fluency.
• High vocabulary coverage, especially in the input language, which helps make the transla-tion system more robust.
• High variety of sentence lengths, which should also improve robustness.
In previous years, we explicitly tried to maxi-mize all four of these properties, but this year we focused only on the first two in the scoring pre-sented in section2.3below.
2.1 Iterative statistical sentence alignment
Our iterative statistical sentence alignment method as detailed in Joanis et al. (2020) uses ssal, a reimplementation and extension ofMoore(2002) which is part of the Portage statistical machine translation toolkit (Larkin et al.,2010).
First, we train an IBM-HMM model (Och and Ney,2003) on the clean parallel training data and the subsampled noisy corpora (see Table 1 for statistics) and use it to align paragraphs in the given document pairs, asMoore(2002) does. The sub-sampled noisy corpora are those obtained by apply-ing our filterapply-ing baseline as described in sections 2.2and2.3(and denoted as “nrc.baseline” in table 2). Then, we segment the paragraphs in both lan-guages into sentences using the Portage sentence splitter. Finally, we align sentences within aligned paragraphs using the IBM model again. In this pro-cess, both the data used in training the IBM-HMM model and the noisy document pairs for alignment are punctuation tokenized using the Portage tok-enizer.
In past work on sentence alignment (Joanis et al. (2020) and other unpublished experiments), we have found that first aligning paragraphs and then aligning sentences within aligned paragraphs out-performs approaches that align sentences without paying attention to paragraph boundaries.
2.2 Initial filtering
The pre-filtering steps of our submissions are mostly the same as those inBernier-Colborne and Lo(2019). We remove:
1. duplicates after masking email, web ad-dresses and numbers,
2. sentence pairs with a majority of number mis-matches,
3. sentence pairs with either side in the wrong language according to the pyCLD2 language detector1,
4. sentence pairs where over half of the source sentence is non-alphabetical or target lan-guage characters, and
5. sentence pairs where over half of the target sentence is non-alphabetical characters. An additional pre-filtering rule included in this year’s submissions is the removal of pairs where over 50% of the target English sentence is directly
Lang(s) Training data sources #sentence pairs #source tokens #target tokens clean parallel
km–en JW300, Bible,
GNOME/KDE/Ubuntu, Tatoeba, Global Voices
290k 6M 4M
ps–en Bible, GNOME/KDE/Ubuntu, Wikimedia, TED Talks, Tatoeba
123k 792k 662k
filtered noisy
km–en ParaCrawl 288k 2M 5M
ps–en ParaCrawl 393k 6M 5M
Table 1: Data used to train the IBM-HMM model used in the iterative statistical sentence alignment.
copying from the source Khmer or Pashto sen-tence.
2.3 Sentence pair scoring
The core of our sentence pair scoring component is the semantic MT quality estimation metric, YiSi-2. YiSi (Lo, 2019) is a unified semantic MT quality evaluation and estimation metric for lan-guages with different levels of available resources. YiSi-1 measures the similarity between a machine translation and human references by aggregating weighted distributional (lexical) semantic similari-ties, and optionally incorporating shallow seman-tic structures. YiSi-2 is the bilingual, reference-less version, which uses bilingual word embed-dings to evaluate cross-lingual lexical semantic similarity between the input and MT output or, in this task, between the source and target sentences. YiSi-2 relies on a crosslingal language represen-tation to evaluate the crosslingual lexical semantic similarity. Previously, it used pre-trained multilin-gual BERT (Devlin et al.,2019) for this purpose. In this work, we instead experiment with XLM-RoBERTa (Conneau et al., 2020) because (1) at the time this work was done, it was the only pre-trained multilingual language encoder that covers both Khmer, Pashto and English; and (2) it shows better performance with lower-resource languages than BERT.
As suggested by Devlin et al. (2019); Peters et al.(2018);Zhang et al.(2020), we experiment with using contextual embeddings extracted from different layers of the multilingual language en-coder to find out the layer that best represents the semantic space of the language.
YiSi is semantic oriented. In the past, we no-ticed that YiSi-based scoring functions failed to filter out sentence pairs with disfluent target text.
FollowingZhao et al.(2020), we experiment with improving the sentence pair scoring function by linearly combining YiSi score with the language model (LM) scores of the target text obtained from the multilingual language model used in YiSi. However, instead of using an additional pretrained language model—GPT-2 (Radford et al.,2019)— as in Zhao et al. (2020), we use the left-to-right LM scores obtained from XLM-RoBERTa while computing the crosslingual lexical semantic simi-larity. The advantages of using the same pretrained model for computing the crosslingual lexical se-mantic similarity and the language model scores are 1) it costs less in both memory and computa-tion; 2) it is more portable to languages other than English. We combined the LM scores in the prob-ability domain linearly with the semantic similar-ity scores with a weight of 0.1 assigned to the LM scores.
In the WMT19 metrics shared task (Ma et al., 2019), we saw a very significant performance degradation between YiSi-1 and YiSi-2. This sug-gests that current multilingual language models construct a shared multilingual space in an unsu-pervised manner without any direct bilingual sig-nal, in which representations of context in the same language are likely to cluster together in part of the subspace and there is a language segregation in the shared multilingual space. Inspired byArtetxe et al.(2016) andZhao et al.(2020), we sample 5k clean sentence pairs and use the token pairs aligned by maximum alignment of their semantic similar-ity to train a cross-lingual linear projection that would transform the source embeddings into the target embeddings subspace.
(a) km–en FAIRseq (b) km–en MBART
(c) ps–en FAIRseq (d) ps–en MBART
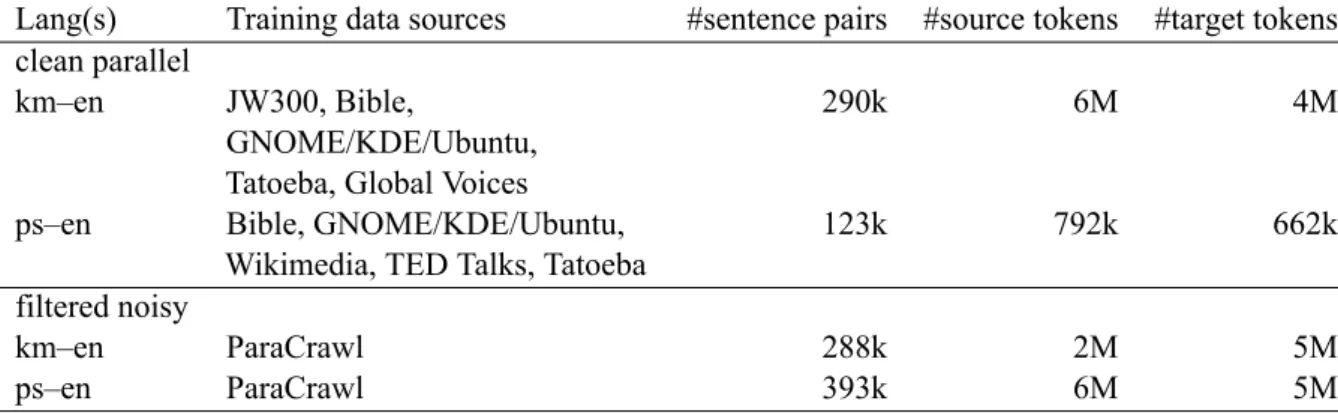
Figure 1: BLEU scores on the Khmer–English dev set for (a) FAIRseq and (b) MBART and the Pashto–English dev set for (c) FAIRseq and (d) MBART trained on 5M-word parallel subsample extracted according to the scoring functions as shown: on the x-axis, layer =−n means YiSi-2 based on the embeddings of the nthlayer, counting
from the last, of XLM-RoBERTabase(blue circles) or XLM-RoBERTalarge(red triangles).
3 Experiments and results
We used the software provided by the task orga-nizers to extract the 5M-word samples from the original test corpora according to the scores gener-ated by each alignment and/or filtering system. We then trained a FAIRseq MT system or fine-tuned an MBART pretrained NMT using the extracted sub-samples. The MT systems were then evaluated on the official dev set (“dev-test”).
We exhaustively experimented with the last few layers of both XLM-RoBERTabaseand
XLM-RoBERTalarge in order to find out the model and
layer best representing crosslingual semantic simi-larity. Figure1 shows the plots of the change in BLEU scores of each MT system using the
em-beddings extracted from the nth layer, counting from the last, of the multilingual LM for evalu-ating crosslingual lexical semantic similarity. In general, we see a trend of rising performance as we roll back from the last layer. The perfor-mance peaks at some point and starts to fall when we roll back too far from the end. For XLM-RoBERTabase, the peak performance of the MT
systems is achieved by the 3rdor 4thlast layer (out of 12 layers). For XLM-RoBERTalarge, the peak
performance of the MT systems is achieved by the 8th last layer (out of 24 layers). The peak perfor-mance of MT systems trained on sentences filtered by XLM-RoBERTalargebased YiSi-2 is better than
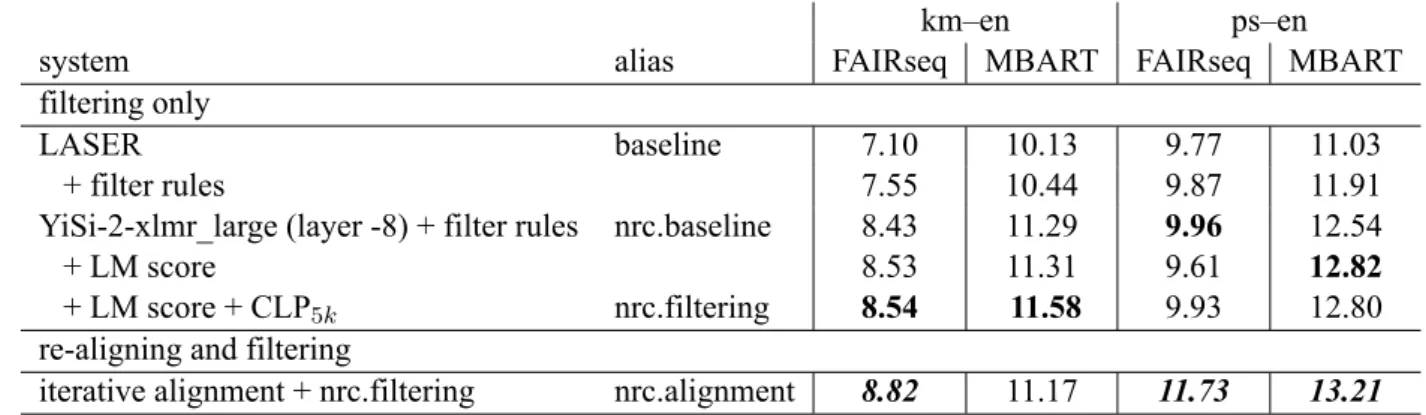
km–en ps–en
system alias FAIRseq MBART FAIRseq MBART
filtering only
LASER baseline 7.10 10.13 9.77 11.03
+ filter rules 7.55 10.44 9.87 11.91
YiSi-2-xlmr_large (layer -8) + filter rules nrc.baseline 8.43 11.29 9.96 12.54
+ LM score 8.53 11.31 9.61 12.82
+ LM score + CLP5k nrc.filtering 8.54 11.58 9.93 12.80
re-aligning and filtering
iterative alignment + nrc.filtering nrc.alignment 8.82 11.17 11.73 13.21
Table 2: BLEU scores of selected systems. The two final submitted systems are labelled nrc.filtering and nrc.alignment.
Table 2 shows the results of the experiments described in section 2.3. First, we show an im-proved version of the organizers’ baseline by sim-ply adding our initial filtering rules. This shows that our initial filtering rules are able to catch bad parallel sentences which are hard to filter by an embedding-based filtering system.
Next, we see that using YiSi-2 with XLM-RoBERTalarge’s 8th last layer as parallelism
scor-ing function outperforms the LASER baseline by 0.1–0.9 BLEU in different translation directions and MT architectures. This is our “nrc.baseline” system, and the baseline used for filtering the noisy corpus in training the IBM-HMM alignment model for the “nrc.alignment” system. Adding the LM score to the scoring function shows small improve-ments. Learning the cross-lingual linear projec-tion matrix to transform the source embeddings in the target language subspace shows more improve-ments overall. This is our “nrc.filtering” submis-sion to the parallel corpus filtering task.
At last, we show that using our iterative statisti-cal alignment method to redo the alignment of sen-tences from the given document pairs improves the translation quality of the resulting MT systems sig-nificantly. This is our “nrc.alignment” submission to the parallel corpus filtering task.
4 Conclusion and Future Work
In this paper, we presented the NRC’s two sub-missions to the WMT20 Parallel Corpus Filtering and Alignment for Low-Resource Conditions task. Our experiments show that YiSi-2 is a scoring func-tion of parallelism that is very competitive, and that a statistical sentence alignment method is still able to provide better alignment results than neural ones in low resource situations. Further analysis
is required to understand the characteristics of the sentence pairs aligned by the baseline vecalign and our iterative statistical sentence alignment and how the latter achieves better translation quality for the trained MT systems.
It is worth highlighting that in this task, as well as in our Inuktitut–English corpus alignment work (Joanis et al.,2020), a well-tuned statistical sentence-alignment system outperformed a state-of-the-art neural one. We hypothesise that this is a low-resource effect, but further work is still needed to explore the best low-resource corpus alignment methods. In particular, we intend to integrate YiSi-2 into our sentence aligner to test whether it’s our iterative alignment methodology that makes the difference or the fact that the underlying scoring function is statistical (we use IBM-HMM models for sentence pair scoring in our aligner). It’s pos-sible that the statistical approach might continue to win here, because in the low-resource context there might not be enough training data to tune the orders of magnitude more parameters of the neu-ral models; a counter-argument is that YiSi-2 did better on the scoring task than statistical scoring functions. Our future work will explore the trade-offs between these two approaches, and consider hybrid methods.
References
Mikel Artetxe, Gorka Labaka, and Eneko Agirre. 2016.
Learning principled bilingual mappings of word em-beddings while preserving monolingual invariance. In Proceedings of the 2016 Conference on
Empiri-cal Methods in Natural Language Processing, pages
2289–2294, Austin, Texas. Association for Compu-tational Linguistics.
parallel corpus filtering system for WMT 2019. In
Proceedings of the Fourth Conference on Machine Translation (Volume 3: Shared Task Papers, Day 2), pages 252–260, Florence, Italy. Association for
Computational Linguistics.
Vishrav Chaudhary, Yuqing Tang, Francisco Guzmán, Holger Schwenk, and Philipp Koehn. 2019. Low-resource corpus filtering using multilingual sentence embeddings. In Proceedings of the Fourth
Confer-ence on Machine Translation (Volume 3: Shared Task Papers, Day 2), pages 261–266, Florence, Italy.
Association for Computational Linguistics.
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettle-moyer, and Veselin Stoyanov. 2020. Unsupervised cross-lingual representation learning at scale. In
Pro-ceedings of the 58th Annual Meeting of the Asso-ciation for Computational Linguistics, pages 8440–
8451, Online. Association for Computational Lin-guistics.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language under-standing. In Proceedings of the 2019 Conference
of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers),
pages 4171–4186, Minneapolis, Minnesota. Associ-ation for ComputAssoci-ational Linguistics.
Cyril Goutte, Marine Carpuat, and George Foster. 2012. The impact of sentence alignment errors on phrase-based machine translation performance. In
Proceed-ings of the Tenth Conference of the Association for Machine Translation in the Americas.
Francisco Guzmán, Peng-Jen Chen, Myle Ott, Juan Pino, Guillaume Lample, Philipp Koehn, Vishrav Chaudhary, and Marc’Aurelio Ranzato. 2019. The FLORES evaluation datasets for low-resource ma-chine translation: Nepali–English and Sinhala– English. In Proceedings of the 2019 Conference
on Empirical Methods in Natural Language Process-ing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP),
pages 6098–6111, Hong Kong, China. Association for Computational Linguistics.
Eric Joanis, Rebecca Knowles, Roland Kuhn, Samuel Larkin, Patrick Littell, Chi-kiu Lo, Darlene Stewart, and Jeffrey Micher. 2020. The Nunavut Hansard Inuktitut–English parallel corpus 3.0 with prelimi-nary machine translation results. In Proceedings of
The 12th Language Resources and Evaluation Con-ference, pages 2562–2572, Marseille, France.
Euro-pean Language Resources Association.
Philipp Koehn, Francisco Guzmán, Vishrav Chaud-hary, and Juan Pino. 2019. Findings of the WMT 2019 shared task on parallel corpus filtering for low-resource conditions. In Proceedings of the
Fourth Conference on Machine Translation (Volume 3: Shared Task Papers, Day 2), pages 54–72,
Flo-rence, Italy. Association for Computational Linguis-tics.
Philipp Koehn, Kenneth Heafield, Mikel L. For-cada, Miquel Esplà-Gomis, Sergio Ortiz-Rojas, Gema Ramírez Sánchez, Víctor M. Sánchez Cartagena, Barry Haddow, Marta Bañón, Marek Střelec, Anna Samiotou, and Amir Kamran. 2018a.
ParaCrawl corpus version 1.0. LINDAT/CLARIN digital library at the Institute of Formal and Applied Linguistics (ÚFAL), Faculty of Mathematics and Physics, Charles University.
Philipp Koehn, Huda Khayrallah, Kenneth Heafield, and Mikel Forcada. 2018b. Findings of the WMT 2018 shared task on parallel corpus filtering. In
Pro-ceedings of the Third Conference on Machine Trans-lation, Volume 2: Shared Task Papers, Brussels,
Bel-gium. Association for Computational Linguistics. Samuel Larkin, Boxing Chen, George Foster, Ulrich
Germann, Eric Joanis, Howard Johnson, and Roland Kuhn. 2010. Lessons from NRC’s Portage system at WMT 2010. In Proceedings of the Joint Fifth
Workshop on Statistical Machine Translation and MetricsMATR, pages 127–132, Uppsala, Sweden.
Association for Computational Linguistics.
Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. 2020.Multilingual denoising pre-training for neural machine translation.
Chi-kiu Lo. 2019.YiSi - a unified semantic MT quality evaluation and estimation metric for languages with different levels of available resources. In
Proceed-ings of the Fourth Conference on Machine Transla-tion (Volume 2: Shared Task Papers, Day 1), pages
507–513, Florence, Italy. Association for Computa-tional Linguistics.
Chi-kiu Lo, Cyril Goutte, and Michel Simard. 2016.
CNRC at SemEval-2016 task 1: Experiments in crosslingual semantic textual similarity. In
Proceed-ings of the 10th International Workshop on Seman-tic Evaluation (SemEval-2016), pages 668–673, San
Diego, California. Association for Computational Linguistics.
Chi-kiu Lo and Michel Simard. 2019. Fully unsuper-vised crosslingual semantic textual similarity metric based on BERT for identifying parallel data. In
Pro-ceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), pages 206–
215, Hong Kong, China. Association for Computa-tional Linguistics.
Chi-kiu Lo, Michel Simard, Darlene Stewart, Samuel Larkin, Cyril Goutte, and Patrick Littell. 2018. Ac-curate semantic textual similarity for cleaning noisy parallel corpora using semantic machine translation evaluation metric: The NRC supervised submissions to the parallel corpus filtering task. In Proceedings
of the Third Conference on Machine Translation: Shared Task Papers, pages 908–916, Belgium,
Brus-sels. Association for Computational Linguistics. Thang Luong, Hieu Pham, and Christopher D.
Man-ning. 2015. Bilingual word representations with monolingual quality in mind. In Proceedings of the
1st Workshop on Vector Space Modeling for Natural Language Processing, pages 151–159, Denver,
Col-orado. Association for Computational Linguistics. Qingsong Ma, Johnny Wei, Ondřej Bojar, and Yvette
Graham. 2019. Results of the WMT19 metrics shared task: Segment-level and strong MT sys-tems pose big challenges. In Proceedings of the
Fourth Conference on Machine Translation (Volume 2: Shared Task Papers, Day 1), pages 62–90,
Flo-rence, Italy. Association for Computational Linguis-tics.
Robert C. Moore. 2002. Fast and accurate sentence alignment of bilingual corpora. In Proceedings of
the Conference of the Association for Machine Trans-lation in the Americas, pages 135–144.
Franz Josef Och and Hermann Ney. 2003. A systematic comparison of various statistical alignment models.
Computational Linguistics, 29(1):19–51.
Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli. 2019. fairseq: A fast, extensible toolkit for sequence modeling. In Proceedings of
the 2019 Conference of the North American Chap-ter of the Association for Computational Linguistics (Demonstrations), pages 48–53, Minneapolis,
Min-nesota. Association for Computational Linguistics. Kishore Papineni, Salim Roukos, Todd Ward, and
Wei-Jing Zhu. 2002. Bleu: a method for automatic eval-uation of machine translation. In Proceedings of the
40th Annual Meeting of the Association for Computa-tional Linguistics, Philadelphia, Pennsylvania, USA.
Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word repre-sentations. In Proceedings of the 2018 Conference
of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 2227–
2237, New Orleans, Louisiana. Association for Com-putational Linguistics.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI
Blog, 1(8):9.
Michel Simard. 2014. Clean data for training statisti-cal MT: the case of MT contamination. In
Proceed-ings of the Eleventh Conference of the Association for Machine Translation in the Americas, pages 69–
82, Vancouver, BC, Canada.
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. Bertscore: Eval-uating text generation with BERT. In International
Conference on Learning Representations.
Wei Zhao, Goran Glavaš, Maxime Peyrard, Yang Gao, Robert West, and Steffen Eger. 2020. On the lim-itations of cross-lingual encoders as exposed by reference-free machine translation evaluation. In
Proceedings of the 58th Annual Meeting of the Asso-ciation for Computational Linguistics, pages 1656–
1671, Online. Association for Computational Lin-guistics.