HAL Id: hal-02458240
https://hal.archives-ouvertes.fr/hal-02458240
Submitted on 28 Jan 2020
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of
sci-entific research documents, whether they are
pub-lished or not. The documents may come from
teaching and research institutions in France or
abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est
destinée au dépôt et à la diffusion de documents
scientifiques de niveau recherche, publiés ou non,
émanant des établissements d’enseignement et de
recherche français ou étrangers, des laboratoires
publics ou privés.
Gérard Sabah, Brigitte Grau
To cite this version:
Gérard Sabah, Brigitte Grau. Compréhension automatique de textes. J.M. Pierrel. Ingéniérie des
langues, Informatique et systèmes d’information, 13, Hermes, pp.293–310, 2000. �hal-02458240�
Compréhension automatique de textes
113.1. Introduction
La façon de comprendre un texte dépend fortement du domaine qu’il traite, mais aussi de son type ; on distingue essentiellement des textes descriptifs, des textes argumentatifs et des textes narratifs. Jusqu’aux années quatre-vingt, la plupart des travaux existants, tant en intelligence artificielle qu’en linguistique ou en psycholinguistique, se sont limités aux récits. La compréhension de récits présente l’avantage de ne pas être orientée par une tâche précise et permet ainsi d’étudier les problèmes réels de la compréhension. Les mécanismes mis en œuvre dans ce cadre sont donc représentatifs des processus cognitifs utilisés pour la compréhension en général et peuvent être utilisés dans des applications variées.
La première idée utilisée pour mettre en évidence la structure d’un texte a consisté à tenter de décrire des structures globales de textes et à déterminer comment le texte précis analysé cadre avec une de ces structures préétablies. Nous décrirons donc tout d’abord comment ces aspects ont permis une formalisation débouchant sur la notion de grammaire du texte (avec l’exemple de Rumelhart) et sur la théorie de la structure rhétorique (RST : Rhetorical Structure Theory de Mann et Thomson). Ce premier type d’approche peut être caractérisé comme fondé sur la structuration du discours ; il est détaillé dans le paragraphe 13.2. Nous donnerons ensuite divers points de vue développés par l’intelligence artificielle, visant à expliciter les structures intentionnelles et permettant d’expliciter pourquoi le texte est cohérent vis-à-vis des connaissances générales que possède le système sur le monde de référence : reconnaissance du sujet du texte, construction des relations de cohérence
entre les phrases, de causalité, d’enchaînement chronologique, compréhension des anaphores… Cette seconde approche vise à définir les cadres théoriques, les connaissances et les processus nécessaires pour simuler une compréhension en profondeur.
13.2. Approches Structurelles des textes
13.2.1. Les grammaires de texte
Reprenant l’idée des grammaires formelles, divers auteurs ont proposé des règles de récriture pour représenter les relations entre les divers composants d’un récit : [TODOROV 1968] (qui se veut à la base d’une nouvelle science : la narratologie), [COLBY 1973] (plus concerné par l’anthropologie), [THORNDYKE 1979] (qui s’intéresse aux règles que l’on peut apprendre) et des travaux d’ordre psycholinguistique : [RUMELHART 1975, DIJK 1977, 1980, 1983]. Une telle règle sera par exemple :
Récit
→
Exposition + Thème + Intrigue + RésolutionDans toutes les théories développées, la forme des règles est telle qu’il s’agit de grammaires régulières ou de grammaires non contextuelles. Il doit être clair que les grammaires régulières, comme les grammaires non contextuelles, sont des formalismes insuffisants pour rendre compte de toutes les relations entre les divers composants d’un récit, en particulier par leur incapacité à représenter les enchâssements récursifs. On peut signaler un essai d’introduction de « transformations » dans ces grammaires [MANDLER 1977] permettant des suppressions et des réarrangements, sans que les résultats obtenus soient réellement significatifs.
Pour certaines histoires simples, ce type de règles peut avoir des applications intéressantes, en particulier pour résumer automatiquement comme le montre l’exemple suivant.
Un exemple : Rumelhart
Parmi les divers travaux fondés sur l’utilisation d’une grammaire de récits, celui de Rumelhart est l’un des plus interdisciplinaires : partant de bases psychologiques, il aboutit à une réelle mise en œuvre informatique. Un intérêt important de la grammaire proposée par Rumelhart [1975, 1977] est d’associer des règles de sémantique formelle à chaque règle de construction syntaxique du récit (pour les règles syntaxiques, les éléments facultatifs figurent entre parenthèses et l’étoile indique une répétition possible ; les règles sémantiques sont écrites sous la forme de prédicats appliqués à divers arguments figurant entre parenthèses).
R1 : Récit → Exposition + Episode
R1’: PERMETTRE (Exposition, Episode)
Ce couple de règles dit qu’un récit est composé d’une introduction, appelée ici exposition, et d’un épisode (R1) et que l’introduction doit être telle que l’épisode en soit une conséquence logique (R1’). L'exposition est ensuite un ensemble d’affirmations d’états (R2), représenté sémantiquement comme une conjonction de propositions (R2’) :
R2 : Exposition → (Etat)* R2’: ET (Etat, Etat…)
D’autres règles précisent que les épisodes sont des types d’événements qui entraînent une réaction d’un animé ; la structure des événements est ensuite indiquée, avec des relations sémantiques de causalité ou de possibilité, puis la forme de la réaction, avec la connaissance que la réaction externe est causée par la réaction interne. L’application de l’ensemble de ces règles à l’analyse d’une histoire en fournit simultanément la structure syntaxique (règles R) et la structure sémantique (règles R’). Ces structures ont été utilisées en particulier pour produire des résumés de l’histoire.
Cette approche soulève quelques difficultés, essentiellement parce qu’elle tient surtout compte de la forme du texte et qu’elle néglige les connaissances générales à propos du monde de référence. On est alors amené, pour comprendre des textes, à utiliser les connaissances sur le monde (cf. § 13.3).
13.2.2. La RST
Présentation de la théorie
La RST [MANN 1987] est une théorie descriptive de l’organisation d’un texte. Sa mise au point résulte de l’étude de plusieurs centaines de textes de différents types : textes administratifs, lettres, articles scientifiques, articles de journaux, recettes, etc. Elle permet de décrire un texte en termes de relations fonctionnelles entre ses parties, appelées aussi portées. La portée minimale, i.e. l’unité, est souvent constituée d’une proposition. Deux portées de texte liées par une relation forment à leur tour une portée qui peut alors intervenir dans une relation. Les portées sont ainsi de tailles de plus en plus grandes, et au niveau le plus haut, la portée est le texte dans son intégralité.
Contrairement aux grammaires de récit, les relations portent sur les significations et les intentions dont les portées sont les réalisations en langue. Elles précisent ainsi comment significations et intentions sont structurées et combinées dans un texte. Le
nombre de relations est ouvert, mais les auteurs en définissent souvent de 20 à 30 (cf. Figure 13.1).
Elaboration Objectif Preuve
Circonstance Condition Antithèse
Résolution Autre Concession
Cause volontaire Interprétation Motivation Résultat volontaire Évaluation Facilitation Cause non-volontaire Paraphrase Justification Résultat non-volontaire Résumé Arrière-plan
Figure 13.1. Ensemble de relations
Les relations relient deux portées de texte, généralement un noyau et un satellite, et sont définies par des contraintes sur ces portées, concernant le noyau ou le satellite seuls ou la combinaison des deux. Elles précisent les conditions d’utilisation de la relation et les effets escomptés (cf. Figure 13.2). Ces conditions ne sont jamais définies au niveau lexical, mais portent sur la sémantique ou la pragmatique du texte. Le noyau est formé d’éléments appartenant à l’avant-plan, tandis que le satellite est formé d’éléments appartenant plutôt à l’arrière-plan. Ces relations sont assemblées en arbre de structures rhétoriques sur la base de cinq schémas de constituants. Ainsi, quand l’analyste établit une relation dans un texte, (cf. Figure 13.3), cela signifie que toutes les conditions appartenant à la définition sont présentes, mais une seule analyse est possible.
Relation preuve 1. Contraintes :
- contraintes sur le noyau : le lecteur peut ne pas croire ce qui est dit dans le noyau de manière suffisante et satisfaisante pour l’auteur.
- contraintes sur le satellite : le lecteur croit ce qui est dit dans le satellite ou pourra le trouver crédible.
- contraintes sur la combinaison du noyau et du satellite : Si le lecteur comprend le contenu du satellite, cela tendra à accroître sa croyance du contenu du noyau
2. Effet : la croyance du lecteur en ce qui est dit dans le noyau est renforcée par l’augmentation de la croyance que le contenu du satellite est une base pertinente pour augmenter la croyance dans le noyau.
L’exemple de la Figure 13.3, ci-après, est repris de Masson et issu de [MANN
1990]. La RST est l’une des théories les plus populaires de la dernière décennie, surtout dans le domaine de la génération de discours, même si elle est aussi critiquée sur divers points (e.g., l’ontologie des relations [HOVY 1990a], l’appariement problématique entre relations et actes de langages [HOVY 1990b], la confusion des niveaux informationnels et intentionnels [MOORE 1992]). Néanmoins, quelques systèmes l’ont mise en œuvre en analyse pour construire des résumés ; comme exemple nous allons décrire celui de Marcu [1997].
1. Récemment la police de Farmington a dû aider à réguler le trafic
2. lorsque des centaines de personnes ont fait la queue pour être parmi les premiers demandeurs d’emploi à l’hôtel Marriott qui allait bientôt ouvrir.
3. L’offre d’emploi de l’hôtel - de 300 postes - était une opportunité rare pour beaucoup de sans-emploi.
4. Les gens faisant la queue arboraient un message, réfutant le fait que la revendication au travail pour les sans-emploi passait seulement par la démonstration de leur détermination.
5. Chaque règle a ses exceptions,
6. mais le tragique et trop commun tableau de centaines et peut-être même de milliers de personnes faisant la queue pour n’importe quelle tâche rémunérée illustre le manque d’emploi
7. et non la paresse paragraphe 2 paragraphe 1 1-3 1-2 3 4 5-7 5 6-7 6 7 1 2 arri re plan preuve r sultat volontaire
cause non-volontaire concession
antith se
Figure13.3. Texte tiré de [MANN 1990] et sa représentation (les flèches partent des satellites pour aller vers les noyaux, chaque unité est précédée d’un numéro)
Utilisation de la RST en analyse
Dans sa thèse, Marcu propose un analyseur de texte fondé sur la RST. Cet analyseur repose sur la détection de marques de surface afin de construire des structures de textes non restreints. A cette fin, Marcu propose une formalisation plus poussée de la RST permettant de juger de la validité des structures construites. La correspondance entre marques et relations rhétoriques résulte de l’étude d’un corpus. À chaque marque lexicale sont associées les relations dont elle peut rendre compte et les informations permettant de la détecter dans un texte et de délimiter l’unité élémentaire à laquelle elle s’applique.
Cette analyse présuppose que les textes possèdent une structure hiérarchique prédéterminée et sous-spécifiée, provenant des niveaux suivants : phrases, paragraphes et sections. Après avoir détecté les marques et leurs unités de discours associées, l’analyseur construit les arbres possibles à chacun des trois niveaux, pour sélectionner ensuite le meilleur. Lorsque des unités de texte ne comportent aucune marque, Marcu les lie ou les sépare en fonction d’une simple mesure de cohésion relative aux mots communs (cf. § 13.4.2). Finalement, les arbres obtenus à chaque niveau de granularité sont associés afin d’obtenir un arbre qui couvre l’ensemble du texte.
Cet analyseur a été testé sur cinq articles scientifiques, plus marqués lexicalement que des articles de journaux. Ces articles ont été analysés manuellement par deux personnes. Leur taux d’accord a été mesuré par les coefficients de corrélation de Spearman en attribuant un degré d’importance à chaque unité de texte. La corrélation entre eux étaient très élevée (0.798, p < 0.0001), alors qu’avec l’analyseur, il était de 0.48 et 0.449, p < 0.0001 par rapport à chaque analyse manuelle. Une autre évaluation, par rapport à la tâche finale de résumé, a aussi été menée.
L’auteur attribue ces résultats à la forme différente des arbres construits de part et d’autre, ainsi qu’à leur niveau de granularité, plus fin chez les analystes humains. Il souligne aussi qu’une analyse de ce type repose seulement sur des contraintes structurelles et la détection de marques lexicales, et que d’autres contraintes liées à la notion de thème, d’intentions et autres facteurs pragmatiques, devraient réduire le nombre de structures construites. Le problème de la complexité de l’analyse et de la définition de connaissances plus complètes se pose alors de manière plus cruciale.
13.2.3. Les différents plans du discours, Introduction
Outre des raisons de complexité évidentes, la réalisation d’un processus unique de compréhension de textes est une tâche qui reste loin de nos capacités actuelles. Il est préférable d’appréhender ce problème en le décomposant selon plusieurs
processus indépendants. Chacun d’eux constitue une simplification, mais l’ensemble permet de mettre en évidence plusieurs interprétations différentes. Les divers points de vue possibles sont les suivants :
- Le point de vue culturel, où les actions explicitées s’intègrent dans les modèles de la vie courante. On peut ainsi comprendre les relations entre deux phrases comme : Je veux organiser une réunion. Retiens la salle, à partir de nos connaissances sur le monde. On cherche ici à conduire une analyse thématique du texte, à partir de connaissances pragmatiques générales.
- Le point de vue des actions, selon lequel on cherche à comprendre quels désirs sont exprimés par les personnages et quelles actions ils entreprennent pour les réaliser. Il n’est point besoin de beaucoup de connaissances pour relier Jean a faim à Il va chez le boulanger, et comprendre que Jean va chercher à obtenir quelque chose de comestible. Les informations culturelles n’interviennent ici que pour déterminer qu’il s’agit de pain ou de gâteaux. On interprète alors la phrase d’après des éléments de base du comportement des individus.
- Le point de vue des personnages : on se réfère ici aux caractéristiques propres des personnages pour comprendre l’histoire et éventuellement résoudre des contradictions. On sera ainsi amené, pour comprendre Vous êtes jolie, dit l’homme rusé au laideron, à inférer que cet homme ment pour obtenir quelque chose de cette fille ; s’il était myope, on aurait été conduit à conclure qu’il se trompait. L’interprétation de la phrase est alors effectuée vis-à-vis des connaissances issues de l’histoire elle-même.
- Le point de vue symbolique, selon lequel les objets et les actions peuvent représenter autre chose que dans la réalité ou le monde de référence. Ainsi, l’expression cet homme est un mouton n’est pas à comprendre telle quelle, et il faut savoir quelles caractéristiques du mouton doivent être affectées à l’homme. Les connaissances culturelles sont alors essentielles pour ce type d’interprétation.
Chacune de ces explications, développée ci-dessous, correspond à une interprétation autonome du texte qui rend compte seulement d’un aspect précis. Le paragraphe 13.4 sera consacré à l’interprétation culturelle, le paragraphe 13.5 aux structures intentionnelles et nous finirons par quelques idées sur les aspects argumentatifs dans le paragraphe 13.6. Très peu de travaux, à part [SOQUIER 1980, SABAH 1981], s’intéressant à l’interprétation d’un texte vu comme un symbole, et la place manquant, nous n’avons pas développé plus avant ce point de vue…
13.3. Analyse thématique des textes
L’analyse thématique consiste à retrouver les sujets abordés par un texte. Cela couvre différents niveaux d’analyse, pouvant aller de la simple découverte des thèmes d’un texte — on parle alors de segmentation thématique — à leur
identification, à leur structuration et leur suivi. Deux approches coexistent, selon le niveau de compréhension désirée. La première est fondée sur l’utilisation de connaissances sur le monde, procurant un niveau de compréhension élevée mais couvrant alors un petit nombre de sujets possibles, au vu de l’effort de modélisation requis pour élaborer cette base de connaissances. La seconde consiste à effectuer une analyse dite de surface, plutôt fondée sur des critères numériques, permettant de couvrir un grand nombre de textes et de domaines.
13.3.1. Analyse fondée sur une représentation des connaissances
Les travaux relevant de cette approche ne sont en général pas spécifiquement dédiés à l’analyse thématique, mais à la découverte des situations évoquées par un texte et des relations causales ou chronologiques entre phrases. Les textes traités sont de courtes histoires. Dans [SCHANK 1977, DYER 1983, GRAU 1983], les connaissances sont représentées par des schémas (ou scripts, scénarios) regroupant les événements descriptifs d’une situation dans leur ordre chronologique, les conditions pour que la situation ait lieu, et les résultats escomptés. Les premiers formalismes proposés, tels les scripts de Schank, représentaient les connaissances de manière rigide où un script équivalait à une situation. Les formalismes suivants, MOPS de [SCHANK 1982] et schémas de [GRAU 1983]) ont pallié cette rigidité en modélisant les connaissances de façon plus modulaire et réutilisable pour décrire plusieurs situations. Aini, au lieu de plusieurs scripts pour une visite chez le médecin, chez le dentiste… comportant diverses étapes identiques (e.g., salle d’attente), on construit une situation spécifique à cette attente qui peut alors être réutilisée.
La compréhension d’un texte consiste à reconnaître les situations évoquées, ce qui correspond au déclenchement de schémas, à partir d’une représentation sémantique des phrases, puis à intégrer les événements particuliers dans le schéma adéquat. Cette phase donne en général lieu à des inférences correspondant aux événements présents dans les descriptions mais qui sont restés implicites dans le texte analysé. Un texte est alors représenté par les différentes instances de schémas, que l’on peut assimiler aux différents sujets traités. Dans [GRAU 1983], un arbre des thèmes est construit où les arcs portent un label indiquant la relation thématique entre deux situations : déviation de thème pour deux sujets liés ou changement de thème.
Zweigenbaum et Cavazza [1992], ont une approche dynamique pour comprendre un texte et représenter les situations. Les textes sont des rapports médicaux et le système construit une représentation de la situation non pas à partir de descriptions mais en appliquant les actions mentionnées.
Tous ces systèmes réalisent une compréhension en profondeur, fondée sur le sens des phrases, leurs liens de causalité et la structure sémantique du texte. Malheureusement leurs applications sont limitées ; pour traiter plus de textes, on a alors recours à des analyses plus superficielles, développées ci-dessous.
13.3.2. Analyse fondée sur des critères de surface
Critères uniquement statistiques ou numériques
Ce type d’analyse part du constat que le développement d’un thème entraîne la reprise de termes spécifiques, notamment lorsqu’il s’agit de textes techniques ou scientifiques, dits expositifs. La reconnaissance de parties de texte liées à un même sujet est alors fondée sur la distribution des mots et leur récurrence. Si un mot apparaît souvent dans l’ensemble du texte, il est peu significatif, alors que sa répétition dans une zone limitée est très significative pour caractériser le thème du segment. Le principe général appliqué par les différents systèmes [MASSON 1995, SALTON 1996, HEARST 1997] consiste à associer un vecteur de descripteurs à une zone de texte, où les descripteurs sont par exemple les mots lemmatisés du texte et leurs valeurs le nombre d’occurrences de ces termes dans la zone ; le produit scalaire de ces vecteurs permet ensuite de regrouper ou de séparer les zones qu’ils décrivent s’ils sont proches ou non.
Salton et Masson ont choisi le paragraphe comme unité de base alors que Hearst délimite des blocs de pseudo-phrases, composées d’un nombre fixé de mots. Hearst a aussi testé d’autres scores entre vecteurs ; l’un est fondé sur le nombre de mots nouveaux, comme dans [YOUMANS 1991], l’autre s’inspire des chaînes lexicales de [MORRIS 1991] (cf. Figure 13.4). Pour déterminer si des zones de texte contiguës sont liées ou non, Hirst et Masson construisent une courbe dont les minimums indiquent des ruptures thématiques. Salton construit un graphe, dans lequel deux paragraphes possèdent un arc si le score entre eux est supérieur à un seuil. La délimitation d’un segment correspond à des paragraphes contigus reliés entre eux et ne possédant pas de liens avec le reste du texte.
A B C D A C E B C E A D E E F G H B F H B F G H GH I 5 1 4 (c) 1 2 3 4 5 6 7 8 A B C D A C E B C E A D E E F G H B F H B F G H GH I 1 2 3 4 5 6 7 8 8 3 9 (a) A B C D A C BC E A D E B F H B F G H G H 1 2 3 4 5 6 7 8 5 + 0 + 3 + 1 5 3 4 E E F G H I (b)
Figure 13.4. Calcul de différents scores entre quatre zones de textes composées de deux phrases chacune. Les lettres représentent les termes des phrases. a) Méthode du produit scalaire entre 2 vecteurs. b) Introduction de termes nouveaux. c) Méthode des chaînes
lexicales. (Figure reprise de [HEARST 1997])
Salton ne s’arrête pas à la segmentation du texte : il propose une méthode, fondée aussi sur le graphe de paragraphes, pour reconnaître l’organisation du texte selon les thèmes abordés en s’affranchissant de la linéarité du texte. Il construit ainsi une structure rhétorique constituée des segments regroupant des paragraphes contigus et une structure thématique.
Analyse utilisant des sources de connaissances externes non dédiées
En généralisant la notion de répétition de termes, la cohésion thématique d’un texte se traduit par l’utilisation de termes faisant référence à une même entité par l’emploi de synonymes, d’hyponymes (ex. fruit et pomme), de mots liés sémantiquement (ex. les couleurs) ou appartenant au même domaine (ex. imprimante et papier). Morris et Hirst ont ainsi émis l’hypothèse que, la cohésion lexicale étant la manifestation de la cohérence d’un texte, la rupture de cette cohésion rend compte d’une rupture thématique, d’où l’idée des chaînes lexicales constituées par des suites de mots liés sémantiquement et apparaissant à une distance maximum les uns des autres. Pour construire ces chaînes, ils ont exploité le Roget’s Thesaurus, non disponible sur support électronique ; leur travail a donc été manuel et appliqué à cinq textes extraits de magazines généraux, qui ont par ailleurs été analysés manuellement pour construire leur structure thématique. L’analyse de la corrélation entre bornes de segments et bornes des chaînes trouvées fait apparaître qu’il n’y a pas bijection entre chaînes lexicales et segments et qu’il n’y a pas une chaîne lexicale associée à chaque segment. Néanmoins, ces chaînes sont de bons indicateurs de portée thématique et de structure hiérarchique des textes. Le travail de Morris et Hirst a donné lieu à une implémentation pour le Japonais par Okumura et Honda [1994].
Ce principe de cohésion lexicale sous-tend le travail de [FERRET 1998b] qui se situe dans le paradigme de l’approche numérique présenté au paragraphe précédent. Segmenter uniquement sur la base de la répétition de termes est inefficace pour des textes narratifs (comme des articles de journaux), où les répétitions sont peu
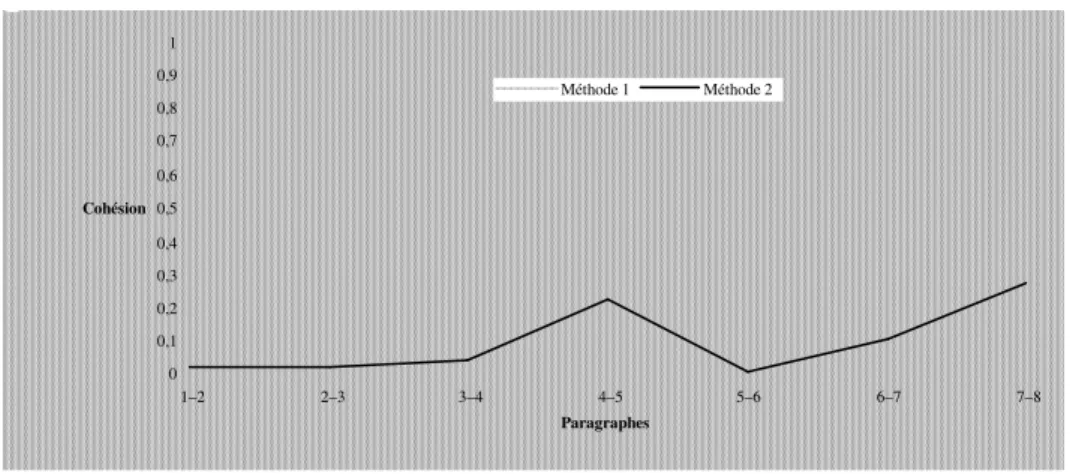
nombreuses et où la cohésion lexicale apparaît au travers l’emploi de mots proches sémantiquement. De manière à introduire ces aspects dans une analyse vectorielle d’un texte, Ferret utilise un réseau de cooccurrences construit automatiquement sur un corpus d’articles de journaux afin d’enrichir les vecteurs décrivant un paragraphe. Le principe utilisé consiste à augmenter la valeur de descripteurs lorsqu’ils sont liés de manière significative dans le réseau à un descripteur du paragraphe. Cette modification des vecteurs tend à rapprocher des paragraphes comportant des mots liés, comme le montre la Figure 13.5. Dans cet exemple tiré du Monde comportant huit paragraphes, la valeur de cohésion entre deux paragraphes est très basse avec la méthode n’exploitant pas le réseau (méthode 1), ce qui signifierait qu’il y a changement de thème après chaque paragraphe. En utilisant les liens entre mots, la seconde méthode trouve des rapprochements effectifs entre les paragraphes 4 et 5 et les paragraphes 7 et 8. 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 1–2 2–3 3–4 4–5 5–6 6–7 7–8 Paragraphes Cohésion Méthode 1 Méthode 2
Figure 13.5 Deux analyses vectorielles d’un texte
Une autre approche ([KOZIMA 1993, FERRET 1998a]) fondée sur la cohésion lexicale consiste à calculer une valeur de cohésion pour chaque mot situé au centre d’une fenêtre, en fonction de ses liens avec les autres mots de la fenêtre, puis à faire glisser cette fenêtre sur tout le texte. Ces valeurs entraînent la construction d’une courbe dont les minimums sont caractéristiques des coupures entre segments de texte. Un minimum de la courbe correspond à une position de la fenêtre à cheval sur deux thèmes : le mot au centre entretient moins de liens avec ses voisins que lorsque la fenêtre est située sur une zone thématiquement homogène. Ce type de méthode requiert donc un réseau pondéré entre mots, réseau de cooccurrences dans Ferret, ou construit à partir d’un dictionnaire dans Kozima. A la différence des autres approches, elle n’exige pas la définition d’une taille minimale pour un segment. Sa tendance est d’ailleurs de former globalement des segments de longueur plus petite.
Dans [FERRET 2002b], les deux approches présentées, répétition de mots et cohésion lexicale, sont combinées pour segmenter un texte et détecter des liens de similarité thématique entre segments.
13.4. Repérage de marques rhétoriques et analyses alliant différents types d’indices
Les travaux présentés précédemment ont tous pour but la délimitation de segments de texte thématiquement homogènes. Dans ce cadre, seules quelques approches se fondent aussi sur la présence de marques pour délimiter ces segments. La caractérisation des changements de thème est alors réalisée par un inventaire des marques linguistiques d’introduction d’un nouveau thème2 ou de fin du thème courant [PASSONNEAU 1997]. Ces marques délimitent des cadres de discours [CHAROLLES 1997] qui sous-tendent la cohésion textuelle que le lecteur reconstruit à partir d’indices dont les marques explicites que sont les introducteurs de cadres. Les cadres thématiques et les cadres organisationnels, qui ont été plus particulièrement étudiés dans REGAL [COUTO 2004], ont en commun deux propriétés essentielles : (i) leurs introducteurs explicitent l’organisation du contenu textuel et sont donc de nature méta-discursive, (ii) leurs introducteurs peuvent fonctionner de concert pour baliser une série de segments discursifs.
Les introducteurs thématiques (en ce qui concerne, pour ce qui est de, à propos de, sur, à ce sujet, à ce propos, etc.) [PORHIEL 2003] assurent une cohérence thématique le plus souvent au niveau local dans un texte. En effet, un texte est rarement entièrement balisé par ces marques. C’est pourquoi celles-ci sont en général utilisées conjointement avec d’autres indices de cohésion lexicale. Passonneau et Litman font appel pour partie à une résolution des chaînes anaphoriques et REGAL allie la présence de ces marques avec un repérage des segments analogue à TextTiling [HEARST 1997]. Toujours dans un objectif de structuration de textes, Marcu [MARCU 1997] s’intéresse aussi à la structuration par connecteurs. Il signale néanmoins qu’en leur absence, la cohésion lexicale lui permet de lier ou non des segments contigus.
Les marqueurs d’intégration linéaire (MIL) quant à eux ont la propriété caractéristique d’être indépendants des contenus sémantiques des segments textuels qu’ils introduisent et relient entre eux sur le mode d’une série linéaire. Ce sont des marques du type d’une part… de l’autre… ; en premier lieu … en second lieu… ; premièrement… deuxièmement… troisièmement…. Chaque marqueur d’intégration linéaire constitue à lui seul un introducteur de cadre à même d'indexer plusieurs
2. Ces marques sont des mots ou des locutions apparaissant généralement en tête de phrase
propositions, voire paragraphes. Cette structure en série est généralement introduite par une amorce, c’est-à-dire une annonce qui explicite le principe fédérateur des items de la série et en précise la longueur [JACKIEWICZ 2002].
L’hypothèse retenue dans REGAL est que ces marques participent toutes à la détermination de la même structure de texte. En considérant les informations provenant des marques linguistiques prépondérantes sur les délimitations de segments proposées par la reconnaissance de rupture de la cohésion lexicale, le segmentation thématique de REGAL ajuste les bornes des segments proposés ou crée de nouveaux segments en fonction de ces marques. En effet, ces marques sont généralement des introducteurs de cadre et non des marques de clôture de segments. Aussi, une première analyse globale du texte reposant sur le principe de la cohésion lexicale, affinée localement par la présence de ces marques est réalisée.
D’autres marques servent aussi à repérer des informations thématiques ou de nature sémantique ou discursive– repérage d’énoncés saillants (ex. j’insiste sur), typage d’énoncés (ex. par exemple, nous montrons que) - que l’on peut vouloir extraire ou mettre en évidence dans les textes. Ainsi, les travaux de Minel (benHazezAl01,minelAl01) et Teufel et Moens [TEUFEL 2002] visent à accéder au contenu sémantique des textes afin d'en repérer les séquences les plus pertinentes.
Partant de la difficulté à définir les expressions pertinentes, Hernandez
[HERNANDEZ 2003] a mis en œuvre une acquisition automatique de
meta-descripteurs qui ne présume pas de la forme des marques. Les marques potentielles sont des n-grams collectés sur un ensemble de textes de domaine différents, mais de même genre. Les marques candidates sont celles que l’on retrouve de façon transversale aux textes, et qui possèdent une fréquence inter-texte minimale. Un algorithme de filtrage fondé sur la proximité des nombres d’occurrences de chaque sur-marque avec ses sous-marques permet de choisir la ou les taille(s) qui semble(nt) décrire au mieux le meta-descripteur. Ces meta-descripteurs correspondent à toutes les expressions utilisées par les auteurs pour mettre en relief leur propos, pour en préciser le type (introduction, hypothèse, etc.) ou pour expliciter leur argumentation. Ce sont donc à la fois des marques indicatrices de contenu, mais aussi des marques rhétoriques explicitant des liaisons ou des ruptures entre énoncés ou segments (par exemple des connecteurs).
13.5 Analyse intentionnelle des textes
13.5.1. Personnages, actions-désirs
Suivant l’analyse présentée au paragraphe 13.3, divers programmes ont été développés dans notre groupe de recherche pour rendre compte de ces différents
aspects. Un premier programme [SABAH 1978a, 1978b] produit une compréhension partielle du texte d’une histoire en cherchant à expliciter les relations de causalité entre les actions et les désirs des personnages du texte. Pour cela il introduit un niveau spécifique de représentation de la phrase : un abrégé de la phrase qui ne contient que l’information utile au traitement prévu. On peut ainsi classer les phrases en un nombre restreint de types d’événements (désir, intention, action, relation, perception), ce qui permet ensuite de n’avoir besoin que de quelques règles de comportement (sept) pour expliciter les relations causales possibles entre ces classes. Le système est ainsi capable d’inférences non triviales pour rendre compte de la cohérence du texte de ce point de vue. Il peut également découvrir, à partir de cette base, les plans qu’un personnage met en œuvre pour atteindre un but qu’il ne peut réaliser immédiatement.
Un deuxième programme [BERTHELIN 1979] cherche à interpréter un texte d’après le comportement des personnages, leurs caractéristiques et le contenu de ce qu’ils disent. Un personnage est représenté selon divers points de vue : celui de l’auteur et celui des autres personnages de l’histoire. Le programme essaie également d’expliquer les contradictions qui apparaissent entre les discours des différents personnages (il sait qu’une contradiction peut survenir si un personnage ment, se trompe, délire… Il analyse alors les informations sémantiques connues à propos de ces concepts et des caractéristiques des personnages pour voir quelle est la solution la plus adéquate).
D’autres aspects ont également été traités dans notre groupe [SOQUIER 1980, GRAU 1983], mais, afin de n’être pas trop égocentriques, nous nous fonderons plutôt sur les travaux de Schank pour illustrer les points suivants.
15.5.2. Les plans
Alors que les scénarios (cf. § 13.4) décrivent des connaissances spécifiques correspondant à des situations fréquemment rencontrées, les plans fournissent des connaissances générales sur le comportement de l’homme qui vont permettre d’interpréter ses actions, même en présence d’une séquence d’actions jamais rencontrée auparavant.
Un plan sert donc à mettre en évidence les liens qui existent entre des actions accomplies afin de satisfaire certains buts : aux différents états souhaités (les buts et sous-buts à atteindre) on associe les actions à entreprendre pour les réaliser. De façon moins précise qu’un scénario indiquant ce qui se passe couramment au restaurant (mais peut-être plus efficace si l’on n’est pas dans une région très civilisée), un plan général pour se nourrir pourrait ainsi être le suivant :
Savoir où il y a de la nourriture ; aller à l’endroit où elle se trouve ; prendre le contrôle de cette nourriture ; préparer cette nourriture (scénario) ; la manger.
Le deuxième but de cette séquence pourra par exemple être réalisé par les actions usuelles liées à la notion de déplacement (marcher, prendre les transports en commun, prendre sa voiture, utiliser un animal…), d’autre buts utiliseront des scénarios connus. On distingue deux sortes de buts : les sous-buts spécifiques (réalisables par des séquences d’actions simples dépendant de l’objet sur lequel elles portent) et les sous-buts généraux issus de la combinaison d’éléments primitifs comme [SCHANK 1977,WILENSKY 1977] :
Savoir ; Contrôler ; Contrôler socialement ; Être proche de ; Intermédiaire. À chaque sous-but primitif est attaché un ensemble de réalisations possibles : les actions de base élémentaires usuelles employées pour les réaliser.
Tous ces éléments seront activés, lors du processus de compréhension, à partir d’informations lexicales ; les connaissances attachées à un mot peuvent alors être élémentaires ou complexes et déclencher plusieurs sous-buts. Ainsi, au concept Utiliser (X) seront attachés les sous-buts :
Savoir (Lieu (X)), Être proche de (X), Contrôler (X), Préparer (X), Action (X), et la phrase Jean veut un livre activera successivement ces cinq sous-buts (les deux derniers sont spécifiques à X = livre, c’est-à-dire qu’à ce concept même seront attachées des informations particulières précisant comment réaliser ces sous-buts : par exemple l’action envisagée sera de lire le livre).
L’utilisation des buts dans ce type de connaissances permet de gagner beaucoup de généralité : on recouvre toutes les actions qui peuvent être effectuées afin de réaliser un but. En contrepartie, le texte devra donner plus de détails pour que le lecteur puisse comprendre effectivement ce qui s’est passé.
15.5.3. Les thèmes
Dans une histoire, les buts peuvent ne pas être explicites. Un autre type de connaissances peut alors être utilisé pour les mettre en évidence : le thème. Un thème spécifie des acteurs ainsi que la situation dans laquelle ils peuvent se trouver. Des buts généraux et les actions qu'ils peuvent entreprendre pour les atteindre, d'une façon cohérente avec le thème, sont alors précisés. Le même type d'information est donné dans des situations particulières prévues a priori.
L'amour est un exemple de thème où l'on va trouver des informations générales (si Jean aime Marie, il la respecte, il veut se marier avec elle [même si cela peut changer avec les époques ou la mode]…) et des informations plus spécifiques (si
Marie n'aime pas Jean, il essaye de faire en sorte qu'elle l'aime, si quelqu'un l'ennuie, il veut la protéger…).
De façon plus précise on peut distinguer trois sortes de thèmes [WILENSKY
1977] :
- Les thèmes généraux. Ils précisent les buts normaux dans la vie d'un individu (être heureux, être bien portant, être riche, être important…).
- Les thèmes interpersonnels. Ils font intervenir plusieurs personnages et indiquent leurs buts selon leurs situations particulières (amour, relations parents-enfants, relations patron-employés…).
- Les thèmes de rôle. Certains personnages ont des rôles systématiquement liés à des buts spécifiques. (Elle s'adresse au shérif provoquera implicitement, sans autre information, l'inférence qu'elle veut probablement obtenir justice).
Le programme de Wilensky PAM (Plan Applier Mechanism) utilisait ce type de connaissances pour comprendre des histoires comme celle-ci : Jean aimait Marie, la fille du roi. Un jour, un dragon enleva la princesse. Jean prit son cheval et tua le dragon. Le roi donna alors la main de sa fille à Jean. Il détermine le but principal et les sous-buts qui vont le satisfaire, puis analyse les entrées comme des réalisations potentielles liées aux sous-buts reconnus. Comprendre une histoire consiste alors à garder la trace des buts de chaque personnage de l'histoire et à interpréter ses actions comme moyens de satisfaire ces buts (ce type de mécanisme permet de retrouver les liens logiques entre les diverses phrases de l'histoire, même quand ils ne sont pas explicités).
En résumé, à propos de ces structures, on peut préciser les liens suivants : - les thèmes donnent lieu à des buts ;
- un plan est compris lorsque ses buts sont identifiés et quand des actions cohérentes avec ces buts sont reconnues ;
- un scénario est un modèle standardisé d'événements ; - les plans fréquents sont l'origine des scénarios ; - les scénarios sont spécifiques, les plans sont généraux ;
- les plans sont une façon de représenter explicitement les buts. Ces buts sont implicites dans les scénarios qui ne représentent que les actions.
13.6. Structure de textes
Peu de travaux portent sur l’explicitation automatique de la structure thématique d’un texte sans se fonder sur sa structure logique, c’est-à-dire son découpage explicite en sections ou paragraphes. Certains requièrent une analyse conceptuelle complète des phrases du texte, comme par exemple [HOBBS 1993] ou [ASHER
1994] qui explicitent des relations causales et temporelles entre phrases, ce qui est irréalisable pour traiter des textes dans des domaines non restreints. D’autres ne proposent pas une théorie suffisamment bien spécifiée pour envisager sa mise en œuvre directement ; il en est ainsi des modèles de [GROSZ 1986] quant à l’explicitation des intentions dans le discours et de la RST [MANN 1987] . Marcu [MARCU 1997] propose la construction automatique de la structure d’un texte, fondée en partie sur la (cf. § 13.2.2). Il met en relation des éléments consécutifs et construit une structure arborescente. Il en est de même dans [YAARI 1997] qui rapproche aussi des segments consécutifs sur un critère de similarité lexicale. Ces approches répondent à une vision « montante » de la structuration en regroupant des unités proches et en les agglomérant.
Des travaux plus récents ([MARCU 1999, KUROHASHI 1994, CHOI 2002, POLANYI 2004]), repris par N. Hernandez [HERNANDEZ 2005], proposent des algorithmes de structuration consistant à rattacher chaque énoncé entrant à un ensemble de points d’attaches possibles. Marcu et Kurohashi et al. construisent ainsi la structure rhétorique du texte. Dans Marcu, les relations entre énoncés sont étiquetées par des relations rhétoriques qui déterminent la structure arborescente produite en fonction du point d’attache trouvé (algorithme Shift and Reduce). Choi et Hernandez en construisent une structure thématique, structure assez analogue à celle produite par Polanyi et al. qui visent la construction de la structure sémantique des textes suivant leur modèle LDM (Linguistic Discourse Model). Ces travaux élaborent une structuration des segments de discours fondée sur les relations de subordination et de coordination ; leurs différences proviennent de la détermination des unités minimales considérées, des indices pris en considération pour déterminer la nature des relations, ainsi que des approches utilisées pour trouver le point d’attachement. Le principe de structuration consiste pour tous à rechercher un nœud appartenant à la frontière droite de l’arbre en cours de construction auquel va se rattacher l’unité de discours en cours. Marcu, Choi et Hernandez déterminent les relations de dépendance par apprentissage alors que Polanyi et al. ont élaboré manuellement des règles de reconnaissance. Globalement, les indices considérés sont : a) la mesure de la cohésion lexicale évaluée par la présence de mots communs, la reconnaissance de chaînes anaphoriques ou de la relation sémantique existant entre deux mots, b) la présence de connecteurs et c) la présence d’indices typographiques ou syntaxiques (parallélisme syntaxique, découpage thème-rhème).
Ces travaux proposent une structuration du texte à grain fin. Or, ce type de structure n’est sans doute pas toujours le plus pertinent selon les types d’application envisagées. Afin de donner une vision globale d’un texte (pour en faciliter sa lecture
ou donner une idée de son contenu par exemple) il peut être intéressant de disposer aussi d’une structure globale du texte. Dans ce cadre, [SALTON 1996] proposent une mesure de similarité lexicale pour construire un graphe des relations entre segments afin de mettre en évidence les thèmes d’un texte. Ceux-ci sont définis comme certains chemins caractéristiques dans le graphe, pouvant relier des segments discontinus. Il y a alors omission complète de la structure linéaire du texte : seuls les thèmes semblables sont liés, sans qu’ils soient positionnés les uns par rapport aux autres.
L’approche choisi dans REGAL [COUTO 2004] pose l’hypothèse que l’auteur d’un texte a organisé son propos en suivant une logique d’imbrication (cas le plus fréquent pour des articles scientifiques) et non d’entrelacement des thèmes. Nous supposons ainsi que si l’auteur revient à un sujet préalablement traité dans le texte, il clôt la digression ou le changement de sujet en cours et qu’il n'y reviendra pas par la suite. C’est ce principe qui conduit à emboîter des thèmes : les thèmes emboîtés sont secondaires par rapport au thème englobant et forment ainsi une structure hiérarchique du texte. Afin de construire la structure emboîtée d’un texte, REGAL applique une approche descendante et met d’abord en évidence le niveau le plus englobant en recherchant les deux segments non consécutifs les plus liés. Cela délimite ainsi la portée du thème développé dans ces passages. Il ré-applique récursivement le même principe aux segments inclus dans la structure de plus haut niveau ainsi qu’à ceux qui sont restés au même niveau.
Un objectif peut être de construire une structure à la fois à gros grain et à grain fin : délimiter d’une part de larges segments de textes et leur liens de dépendances, et d’autre part analyser plus finement ces segments. Cette analyse précise viserait à repérer les notions importantes et représentatives des segments ainsi que les thèmes satellites. Une telle structure permettrait à la fois de synthétiser un texte, qui n’est jamais monolithique et développe en général des thèmes différents, et aussi de représenter chacun des thèmes plus finement que par une liste de termes, comme c’est généralement fait. En terme d’application, cela permettrait non seulement d’indiquer à l’utilisateur les thèmes traités, mais aussi de présenter la partie du texte qui les développe, en positionnant celle-ci par rapport aux autres parties tout en conservant l’organisation spatiale d’origine, et de lui indiquer les thèmes proches et la nature du lien qui les unit, par exemple conséquence, hypothèse, résultat.
13.6.2 Structure argumentative des textes
Certains raisonnements peuvent apparaître dans des textes, ou dans des interventions de notre interlocuteur. Les mécanismes de compréhension, comme les processus de gestion de dialogues doivent donc pouvoir les comprendre pour réagir de façon adéquate. Or, on remarque que les raisonnement effectués dans la vie
courante consistent à poser des affirmations que l'on essaie d'étayer ensuite par des arguments ultérieurs. Ce mécanisme est fondamentalement différent des syllogismes, et il convient donc de distinguer la logique formelle (qui établit la validité d'un raisonnement sur la seule base de sa forme) de la logique naturelle (qui permet de raisonner à l'aide de la langue seule). Cette dernière part principalement de prémisses conformes à l'opinion générale et cherche à en tirer des conséquences acceptables par l'interlocuteur [GRIZE 1986].
Les études linguistiques éventuellement utilisables à l'heure actuelle portent sur des points très précis, comme la schématisation des raisonnements sous-jacents à l'utilisation de mais [RACCAH 1984], ou la mise en évidence des conditions minimales permettant de distinguer l'utilisation de mots voisins comme parce que, puisque, car [MOESCHLER 1986].
Certaines études, comme celle du logicien Toulmin [1958], mettent en évidence des aspects plus généraux de l'argumentation. Ainsi distingue-t-il entre la notion de donnée (évidence sur laquelle tout le monde est d'accord), de prétention (une assertion d'une personne à propos de quelque chose telle qu'une autre personne n'est pas immédiatement convaincue) et de justification (le lien entre une donnée et une prétention). Il tente ensuite de mettre en évidence les marqueurs du discours qui permettent de reconnaître de quel élément il s'agit. Ces résultats dépendent toutefois trop de l'intuition pour être réellement utilisés dans un programme automatique.
[GRANDCHAMP 1996] a repris les travaux de Ducrot [1979, 1980, 1988] pour
rendre compte des ressorts rhétoriques que la langue possède et qui ne sont jamais traités dans les représentations sémantiques habituelles du sens dans les systèmes informatiques. Les raisonnements sont alors des événements uniques, ancrés dans la situation d’énonciation, et remplis d’inférences vraisemblables et de lieux communs. La théorie de la polyphonie lui permet de différencier, pour l’occurrence d’un énoncé, les notions de sujet parlant (auteur des paroles, qui accomplit les actes de langages), de locuteur (à qui l’énoncé est imputable) et d’énonciateur (celui qui prend en charge ou à qui est attribué le contenu). Ces rôles permettent d’expliquer les différents phénomènes de détachement par rapport à ce qu’on dit, qu’il s’agisse de discours rapporté, de style indirect libre ou de polyphonie pure.
Il propose une modélisation complète du raisonnement en langue naturelle incluant :
(1) une logique naturelle pour exprimer les différents mouvements dialectiques, décrivant en particulier des éléments de raisonnement informel ainsi que l’organisation logique d’un texte ;
(2) une sémantique linguistique tenant compte des phénomènes argumentatifs dans les mots, les connecteurs, et surtout dans les enchaînements discursifs ; (3) l’articulation entre ces deux niveaux.
Par ailleurs, avant même son interprétation en situation, la signification (sens littéral) des phrases comporte des éléments de contraintes sur les argumentations qu’elles peuvent supporter. Ces contraintes seront attachées à certains mots (comme peu, un peu, presque), à des connecteurs (comme si, parce que, puisque, donc) et porteront sur les topoï (lieux communs) contenus dans les mots pleins. Ces contraintes définissent une acceptabilité argumentative des énoncés.
Le modèle informatique proposé précise les dimensions du sens qui sont pertinentes pour les actions du système. Les théories de l’argumentation et de la polyphonie interviennent dans le calcul de la signification littérale des phrases par l’enrichissement des représentations sémantiques intermédiaires produites, indiquant les relations avec la situation d’énonciation et les argumentations potentielles. Au niveau de l’interprétation (construction du sens) elles peuvent contribuer à des processus habituels tels que la désambiguïsation ou la recherche d’inférences, mais peuvent aussi mener à la construction d’une structure argumentative du discours. Ces raisonnements sont fondés sur la notion de topos, garante des enchaînements linguistiques, mais pas d’une quelconque inférence. Ce travail a consisté essentiellement en une formalisation rigoureuse préalable à la mise en œuvre et à leur utilisation en machine de tous ces aspects.
13.7. Conclusion
Après cet exposé de diverses tâches à réaliser lors de la compréhension d’un texte, une question reste largement ouverte : comment rendre toutes ces analyses cohérentes entre elles et les faire collaborer ? Sans entrer dans les détails de ce problème complexe, plutôt situé dans le domaine des sciences cognitives, signalons simplement que nous avons présenté par ailleurs [SABAH 1997] une architecture informatique générale destiné à la compréhension automatique des langues et permettant des fonctionnements adaptables à des tâches diverses. Nous avons montré l’inadéquation des architectures classiques, et la nécessité de mettre en œuvre des systèmes “multi-agents” réflexifs (possédant la capacité de raisonner sur leur propre comportement) pour permettre une utilisation modulaire de diverses connaissances sans introduire d’ambiguïté artificielle.
Pour rester dans le cadre de l’ingénierie linguistique, on peut souligner que la principale limitation pour l’utilisation d’analyses sémantiques reste la modélisation de bases de connaissances. Aussi, les travaux actuels concernent-ils surtout des analyses de surface, visant à couvrir un large éventail de textes, ces analyses étant essentiellement utilisées en recherche d’information. Pour tenter d’éliminer le goulet d’étranglement dû à la constitution des connaissances sémantiques, des travaux comme [PAZZANI 1988,RAM 1993, HARABAGIU 1997,FERRET 1997, FERRET
fondés sur une approche incrémentale de l’apprentissage et de la compréhension. Ram et Pazzani cherchent à apprendre des spécialisations de situations générales, tandis que Ferret et Harabagiu & Moldovan veulent délimiter des connaissances sur des domaines, à différents niveaux de structuration.
Un autre aspect étudié actuellement — et que nous ne ferons qu’évoquer ici — concerne l’évaluation des systèmes de compréhension. C’est ainsi que s’est développé la campagne MUC (Message Understanding System), avec notamment la tâche consistant à remplir un schéma décrivant un événement, ou la campagne TDT (Topic Detection and Tracking), avec des tâches consistant à identifier ou suivre des thèmes sur un ensemble de textes de type articles de journaux. Si on peut espérer que ces campagnes permettront une validation scientifique solide des programmes de traitement automatique des langues, il faut aussi veiller à ce qu’elles ne tarissent pas les idées originales nécessaires à ce domaine fondamental pour l’intelligence artificielle et la communication homme-machine…
15.8. Références bibliographiques
[ASHER 1994] ASHER N., and LASCARIDES A., Intentions and information in discourse, Proceedings of the 32nd ACL, pp. 34-41, 1994.
[BERTHELIN 1979] BERTHELIN J.B., Le traitement des personnages dans un système de
compréhension du langage, thèse de 3ème cycle, Paris VI, 1979.
[CAVAZZA 1992] CAVAZZA M. et ZWEIGENBAUM, P. Compréhension automatique du langage
naturel par construction de modèles, TSI (Technique et science informatique), 11, 4, 1992. [CHAROLLES 1997] CHAROLLES M., « L’encadrement du discours - Univers, champs, domaines et espaces », Cahier de recherche linguistique, 6, LANDISCO, URA-CNRS 1035 Université Nancy 2, 1997.
[CHOI 2002]CHOI F. Y. Y., Content-based Text Navigation, PHD thesis, Department of
Computer Science, University of Manchester, 2002.
[COLBY 1973] COLBY K., A partial grammar for eskimo folktales, American Anthropologist,
75, 3, 1973.
[COUTO 2004] COUTO J,FERRET O.,GRAUB.,HERNANDEZN.,JACKIEWICZA.,MINELJ.-L.,
PORHIEL S., REGAL, un système pour la visualisation sélective de documents, Revue
d’Intelligence Artificielle (RIA), 18, 4, p. 481-514, 2004
[DIJK 1977] DIJK T. van, Semantic macro-structured and knowledge frame in discourse
comprehension, Cognitive processes in comprehension, Just et Carpenter (Ed.), Hillsdale, New Jersey, 1977.
[DIJK 1980] DIJK T. van, Semantic macrostructures, Lawrence Erlbaum, New York, 1980.
[DIJK 1983] DIJK T. van et W. Kintsch, Strategies in discourse comprehension, Academic
Press, New York, 1983.
[DUCROT 1979] DUCROT O., Les lois du discours, Languefrançaise,42, p. 21-33, 1979
[DUCROT 1988] DUCROT O., Topoï et formes topiques, Bulletin d'études de linguistique
française, Tokyo, 22, p. 1-14, 1988.
[DYER 1983] DYER M., In-depth understanding, MIT Press, Cambridge, MA, 1983.
[FERRET 1997] FERRET O., GRAU B., « An Aggregation Procedure for Building Episodic
Memory », Fifteenth International Joint Conference on Artificial Intelligence (IJCAI), Nagoya, Japan (1997), p. 280-285.
[FERRET 1998a] FERRET O. et GRAU B. A Thematic Segmentation Procedure for Extracting Semantic Domains from Texts, Actes ECAI'98, Brighton, p. 155-159, 1998.
[FERRET 1998b] FERRET O., GRAU B. et MASSON N., Thematic segmentation of texts: two
methods for two kinds of texts, Actes ACL-COLING'98, Montréal, Canada, volume 1, p. 392-396, 1998.
[FERRET 2002a] FERRET O. et GRAU B, A Bootstrapping Approach For Robust Topic
Analysis, Journal Natural language Enginering (NLE), Special issue on robust methods of corpus analysis, vol 8 (2/3), pp 209:233, 2002.
[FERRET 2002b] FERRET O., Using collocations for topic segmentation and link detection,
Actes COLING, Tapeï, Taiwan, 2002.
[GRANDCHAMP 1996] GRANDCHAMP J.-M., l'argumentation dans le traitement automatique
de la langue, thèse d'Université, Paris XI, 1996.
[GRAU 1983] GRAU B., Analyse et représentation d'un texte d'après le thème du discours,
thèse de 3ème cycle, Université Pierre et Marie Curie (Paris VI), 1983.
[GRIZE 1986] GRIZE J.-B., Logique naturelle et vraisemblance, Actes colloque Logique
naturelle et argumentation, Royaumont, 1986.
[GROSZ 1986] GROSZ B., SIDNER C., Attention, Intentions and the structure of discourse,
Computational Linguistics, 12(3), pp. 175-204, 1986.
[HARABAGIU 1997] HARABAGIU S. et MOLDOVAN D., TextNet - A text-based intelligent system, Natural Language Engineering, 3, 2/3, p. 171-190, 1997.
[HEARST 1997] HEARST M. A., TextTiling: Segmenting Text into Multi-paragraph Subtopic
Passages, Computational Linguistics, 23, 1, p. 33-64, 1997.
[HERNANDEZ 2003] HERNANDEZ N. et GRAU B., Automatic extraction of meta-descriptors for
text description, International Conference on Recent Advances In Natural Language Processing (RANLP), Borovets, Bulgaria, 2003
[HERNANDEZ 2005] HERNANDEZ N. et GRAU B., Détection Automatique de Structures Fines de Texte, Actes de la conférence Traitement Automatique de la Langue Naturelle (TALN), 2005.
[HOBBS 1993] HOBBS J.R., STICKEL M., APPELT D. and MARTIN P., Interpretation as
abduction, Artificial Intelligence, vol. 63, pp. 69-142, 1993.
[HOVY 1990a] HOVY E., Pragmatics and natural language generation, Artificial Intelligence,
43, p. 153-197, 1990.
[HOVY 1990b] HOVY E, Unresolved issues in paragraph planning, Current research in
Natural Language generation, Chris Mellish Robert Dale, Mickaël Zock (Ed.), Academic Press, New York, p. 17-45, 1990.
[JACKIEWICZ 2002] JACKIEWICZ A. Repérage et délimitation des cadres organisationnels
pour la segmentation automatique des textes, CIFT’02, pp. 95-107., Hammamet, Tunisie, 2002.
[KOZIMA 1993] KOZIMA H., Text Segmentation Based on Similarity between Words, Actes 31th Annual Meeting of the Association for Computational Linguistics (Student Session), Colombus, Ohio, USA, p. 286-288, 1993.
[KUROHASHI 1994] KUROHASHI S. and NAGAO M., Automatic Detection of Discourse
Structure by Checking Surface Information in Sentences, COLING, 1994.
[MANDLER 1977] MANDLER J. et JOHNSON N., Remembrance of things parsed : story structure
and recall, Cognitive psychology, 9, p. 111-151, 1977.
[MANN 1990] MANN W. et MATTHIESSEN C., Functions of language in two frameworks, University of Southern California, ISI/RR-90-290, 1990.
[MANN 1987] MANN W. et THOMPSON S., Rhetorical Structure Theory: A Theory of Text
Organization, The Structure of Discourse, L. Polanyi (Ed.), Ablex, Norwood, 1987.
[MARCU 1997] MARCU D., The rhetorical parsing, summarization and generation of natural
language textx, PhD, Toronto, 1997.
[MARCU 1999] MARCU D., A decision-based approach to rhetorical parsing, The 37th Annual Meeting of the Association for Computational Linguistics (ACL'99), 1999.
[MASSON 1995] MASSON N., An automatic method for document structuring , Actes 18th
International Conference on Research and Development in Information Retrieval, ACM-SIGIR , Seattle, USA, p. 372-373, 1995.
[MOESCHLER 1986] MOESCHLER J., Stratégie argumentative et structure de la conversation :
parce-que et la reprise dialogique, Actes colloque Logique naturelle et argumentation, Royaumont, 1986.
[MOORE 1992] MOORE J.D. et POLLACK M.E., A problem for RST : the need for multi-level discourse analysis, Computational linguistics, 18, 4, 1992.
[MORRIS 1991] MORRIS J. et HIRST G., Lexical Cohesion Computed by Thesaural Relations
as an Indicator of the Structure of Text, Computational Linguistics, 17, 1, p. 21-48, 1991. [OKUMURA 1994] OKUMURA M. et HONDA T., Word Sense Disambiguation and Text Segmentation Based on Lexical Cohesion, Actes 15th International Conference on Computational Linguistics (COLING), Kyoto, Japan, volume 2/2, p. 755-761, 1994.
[PASSONNEAU 1997] PASSONNEAU J.R. et LITMAN J. D., Discourse Segmentation by Human
and Automated Means, Computational Linguistics, vol. 23, n° 1, ACL, 1997, p. 103-139. [PAZZANI 1988] PAZZANI M.J., Integrating explanation-based and empirical learning methods
in OCCAM, Actes Third European Working Session on Learning, Glasgow, volume 1/1, p. 147-165, 1988.
[POLANYI 2004]POLANYI L.,CULY C., VAN DEN BERG M.,THIONE G. L. and AHN D., A Rule Based Approach to Discourse Parsing, Proceedings of the 5th SIGdial Workshop on Discourse and Dialogue at HLT-NAACL, Boston, Massachusetts, 2004.
[PORHIEL 2003] PORHIEL S. Les introducteurs de cadre thématique, Cahiers de Lexicologie
83, 2 : 1-36, 2003.
[RACCAH 1984] RACCAH P.-Y., Argumentation et raisonnement implicite, Actes Les modes
de raisonnements, Orsay, 1984.
[RAM 1993] RAM A., Indexing, elaboration and refinement: incremental learning of explanatory cases, Machine Learning, 10, 3, p. 7-54, 1993.
[RUMELHART 1975] RUMELHART D., Note on a schema for stories, Representation and
understanding, Studies in cognitive science, Bobrow et Collins (Ed.), Academic Press, New York, p. 211-236, 1975.
[RUMELHART 1977] RUMELHART D., Understanding and summarizing brief stories, Basic
processes in reading, Laberge et Samuel (Ed.), Hillsdale, New Jersey, 1977.
[SABAH 1978a] SABAH G., Contribution à la compréhension effective d'un récit, doctorat ès
sciences, Université Pierre et Marie Curie (Paris VI), 1978.
[SABAH 1978b] SABAH G., A conversational system that understands short stories, Actes
AISB/GI Conference, Hambourg, 1978.
[SABAH 1997]SABAH G.,Consciousness:aRequirementforUnderstandingNaturalLanguage,
Twosciencesofmind,SeánÓNualláin,PaulMcKevittetEoghanMacAogáin(Ed.),Advances inConsciousnessresearch,JohnBenjamins,Amsterdam,p.361-392,1997.
[SABAH 1981] SABAH G. et SOQUIER S.H., Un exemple d'interprétation de métaphores, Actes
3ème Congrès RF-IA, Nancy, 1981.
[SALTON 1996] SALTON G., SINGHAL A., BUCKLEY C. et MITRA M., Automatic Text
Decomposition Using Text Segments and Text Themes, Actes Hypertext'96, Seventh ACM Conference on Hypertext, Washington, D.C., p. 53-65, 1996.
[SCHANK 1982] SCHANK R., Reminding and memory organisation : an introduction to MOPs,
Strategies for natural language processing, Lehnert et Ringle (Ed.), Lawrence Erlbaum, Hillsdale, N.J., 1982.
[SCHANK 1977] SCHANK R. et ABELSON R., Scripts, plans, goals and undestanding, N.J.
Lawrence Erlbaum, Hillsdale, 1977.
[SOQUIER 1980] SOQUIER S.H., Uneinterprétationautomatiquedemétaphores,l'exempledes Chengyu, thèse de 3ème cycle, Université Pierre et Marie Curie (Paris VI), 1980.
[TEUFEL 2002]TEUFEL S.etMOENS M., Summarizing Scientific Articles -- Experiments with Relevance and Rhetorical Status, Workshop on Discourse Structure and Discourse Markers, ACL, Montreal, Canada, 2002.
[THORNDYKE 1979] THORNDYKE P., Knowledge acquisition from newspaper stories,
Discourse processes, 2., 1979.
[TODOROV 1968] TODOROV T., La grammaire du récit, Langage, 121968.
[TOULMIN 1958] TOULMIN J., The use of arguments, Cambridge University Press, Cambridge,
1958.
[WILENSKY 1977] WILENSKY R., PAM A program that infers intentions, Actes 5° IJCAI, MIT
Cambridge, Mass, 1977.
[YAARI 1997] YAARI Y. Segmentation of Expository Texts by Hierarchical Agglomerative
Clustering, Proceedings of RANLP ,1997.
[YOUMANS 1991] YOUMANS G., A New Tool for Discourse Analysis: The