Time sub-optimal nonlinear PI and PID controllers applied to longitudinal headway car control
Texte intégral
Figure
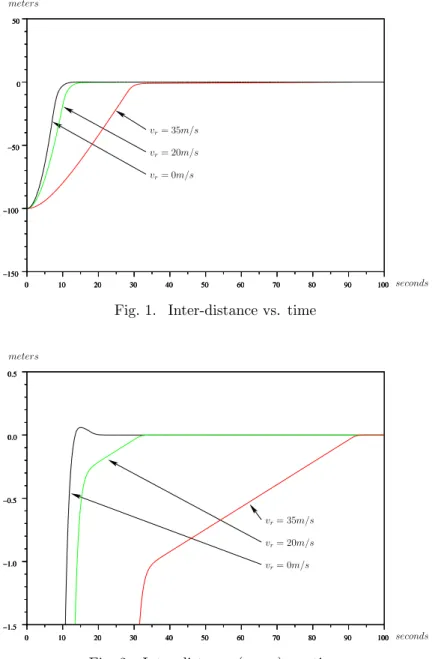

Documents relatifs
Abstract— A sub-optimal guidance and nonlinear control scheme based on Optic Flow (OF) cues ensuring soft lunar land- ing using two minimalistic bio-inspired visual motion sensors
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Model-free control and control with a restricted model, which might be useful for hybrid systems (Bourdais, Fliess, Join & Perruquetti [2007]), have already been applied in
Sename (2021), An Input-to-State Stable Model Predictive Control Framework for Lipschitz Nonlinear Parameter Varying Systems, International Journal of Robust and
The combination of these methods with Time Reversal (TR) process can be used to either increase the stress on the retrofocusing position or to retrofocuse elastic waves on the
Based on a sensitivity analysis, our optimal initial state design methodology consists in searching the minimum value of a proposed criterion for the interested parameters.. In
Given a sequence of states, we introduce an hybrid approximation of the nonlinear controllable domain and propose a new algorithm computing a controllable, piecewise
