Resilience for Collaborative Applications on Clouds
Texte intégral
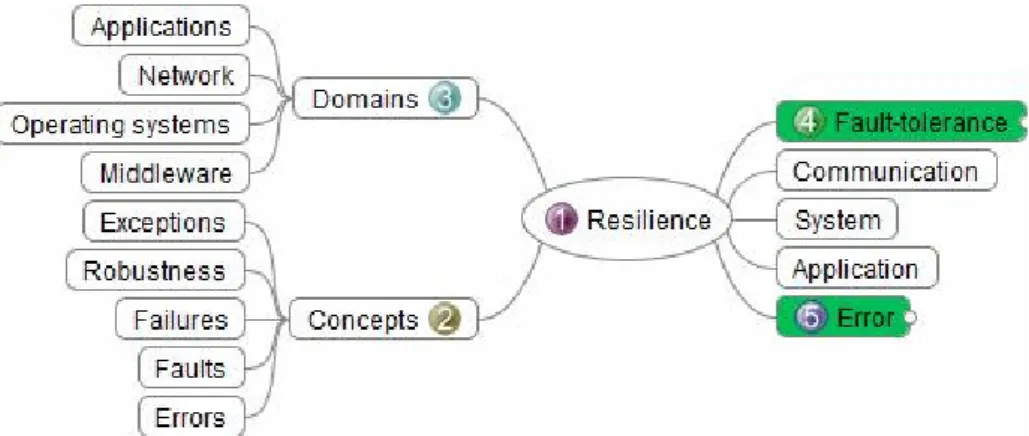
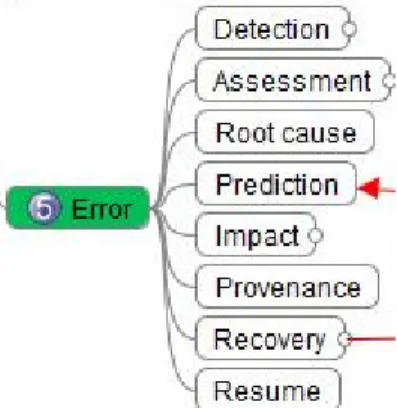
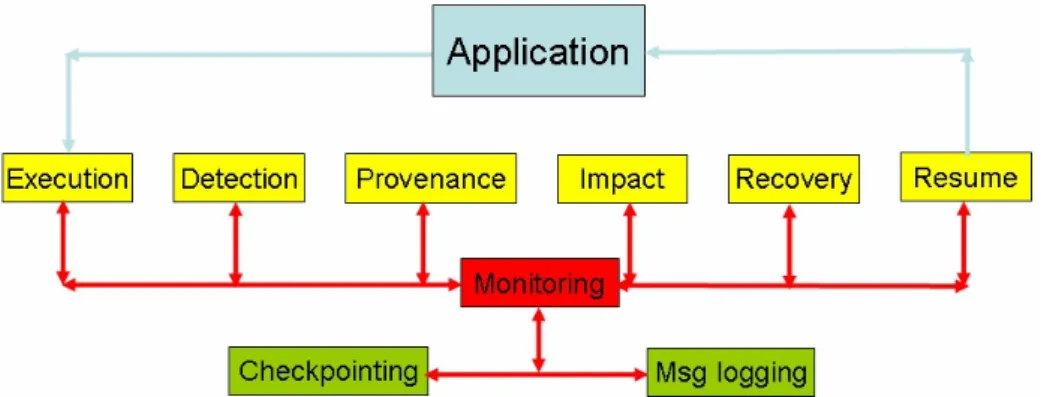
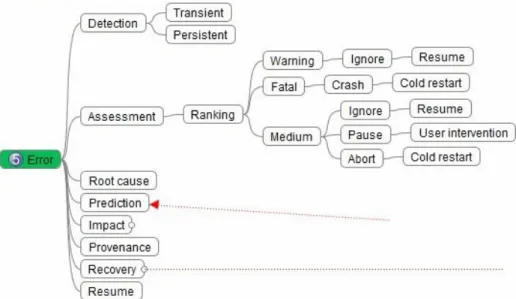
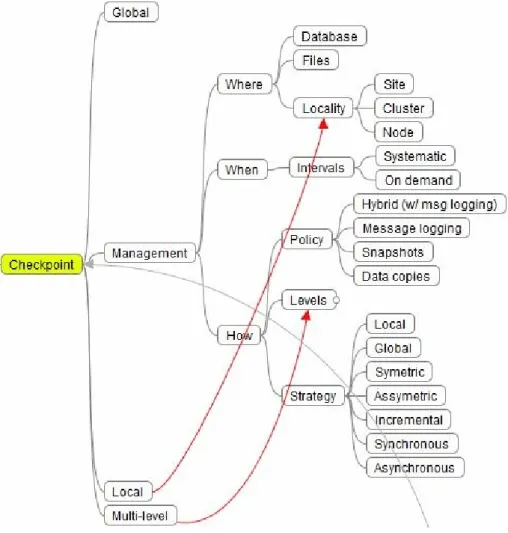
Figure
Documents relatifs
Application of smoothed particle hydrodynamics (SPH) and pore morphologic model 2 to predict saturated water conductivity from X-ray CT imaging in a silty loam Cambisol...
The protogenic properties of the majority of poly- electrolytes used for proton exchange membrane (PEM) preparation are most commonly provided by sulfonic acid functionalities. The
Avec un Conseil national pour l’éducation et la formation, comme partout dans le monde, recommandé aussi par la CNRSE ainsi qu’un Observatoire pour les mêmes secteurs
C’est ainsi que, Le RIFFEAC dans le cadre du Projet d’appui au Programme Elargi de Formation en Gestion des Ressources Naturelles dans le Bassin du Congo (PEFOGRN-BC) dont
The purpose of the present paper is to study the stability of the Kalman filter in a particular case not yet covered in the literature: the absence of process noise in the
It is shown in this paper that the uniform complete observability alone is sufficient to ensure the asymptotic stability of the Kalman filter applied to time varying output
Fabien AMIOT, Michel BORNERT, Pascal DOUMALIN, Jean Christophe DUPRÉ, Marina FAZZINI, Jean José ORTEU, Christophe POILANE, Laurent ROBERT, René ROTINAT, Evelyne TOUSSAINT,
It is shown in this paper that the uniform complete observability is sufficient to ensure the stability of the Kalman filter applied to time varying output error systems, regardless
