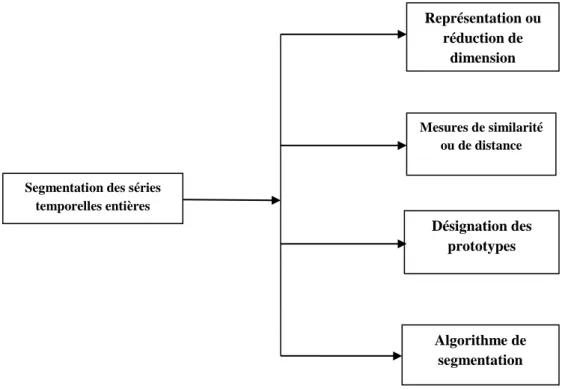
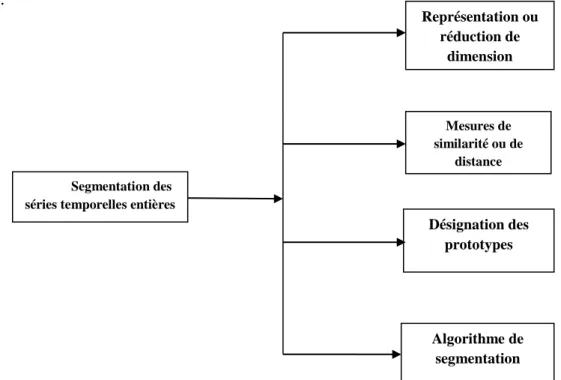
l'étude de classification des séries temporelles àlongueurs variées
Texte intégral
Figure



Documents relatifs
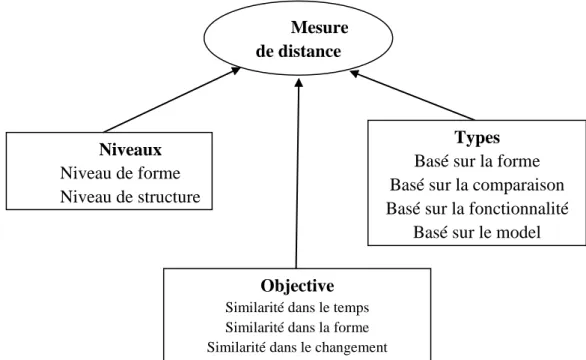
Les contributions de cet article sont donc les suivantes : nous proposons deux mesures de ressemblance basées sur la forme pour la comparaison de séries temporelles.. Nous montrons
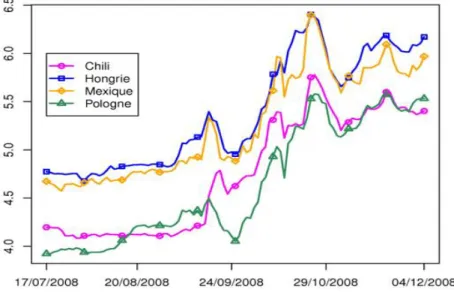
Cette base contient en particulier des données collectées par les agences de l’eau dans le cadre du réseau de suivi créé pour évaluer l’état écologique de masses d’eau,
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Nous d´ ebutons cette section avec un ´ enonc´ e d’int´ erˆ et propre, le th´ eor` eme ergo- dique qui affirme que la loi des grands nombres s’applique pour la plupart des mod`
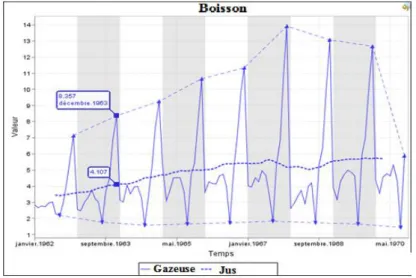
— Le second concerne la recherche de motifs pour l’imputation de valeurs successives manquantes dans une série. Après avoir exposé un point de vue sur les techniques d’im-
maternant les employés en situation de handicap mental et doutent majoritairement de leurs compétences pour occuper un tel poste. La personne en situation de handicap mental
Ce sont des objets de classe mts (abréviation de multiple time series ) qui représentent simultanément plusieurs séries temporelles dont les observations correspondent
ﺔﺒﺴﻨﻟﺎﺒ ﻬﻓ ﺏﻁﻠﻟ ﻲ ﺀﺎﺒﻋﻷﺍ ﻥﻤ ﺭﻴﺜﻜﻟﺍ ﻪﻨﻋ ﻊﻓﺭﺘ ﻰﻟﺇ لﻭﺼﻭﻟﺍ ﻥﻭﺩ لﻭﺤﺘ ﻲﺘﻟﺍ ﺘﻟﺍ ﺔﻴﻠﻤﻋ ﻥﻋ ﺔﺠﺘﺎﻨﻟﺍ ﺓﻭﺍﺩﻌﻟﺍ ﻲﻀﺎﻘ 2. ﺇ ﺔﻴﺩﺭﻔﻟﺍ لﻤﻌﻟﺍ ﺕﺎﻋﺯﺎﻨﻤﻟ ﺔﻴﺩﻭﻟﺍ ﺔﻴﻭﺴﺘﻟﺍ ﺔﻤﻬﻤ ﻥ ﺔﺒﺴﻨﻟﺎﺒ
