statophobes pour Statistiques
142
0
0
Texte intégral
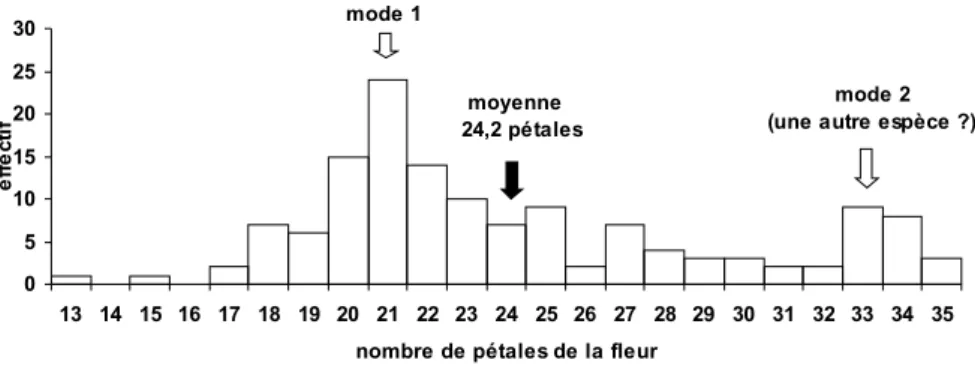
Figure
+7
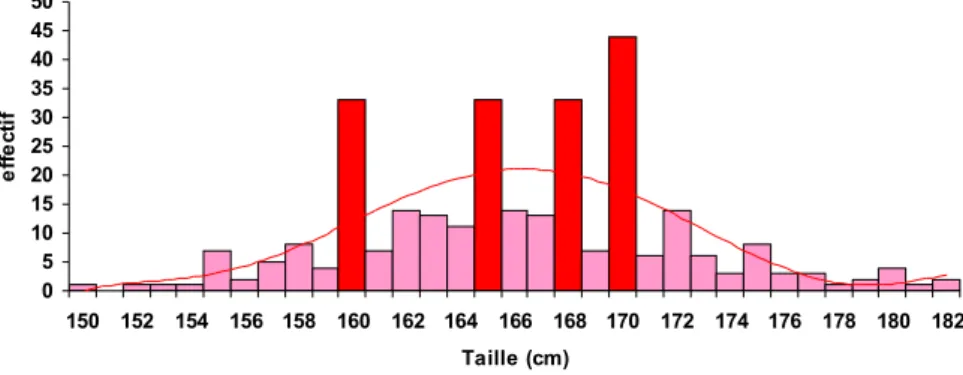

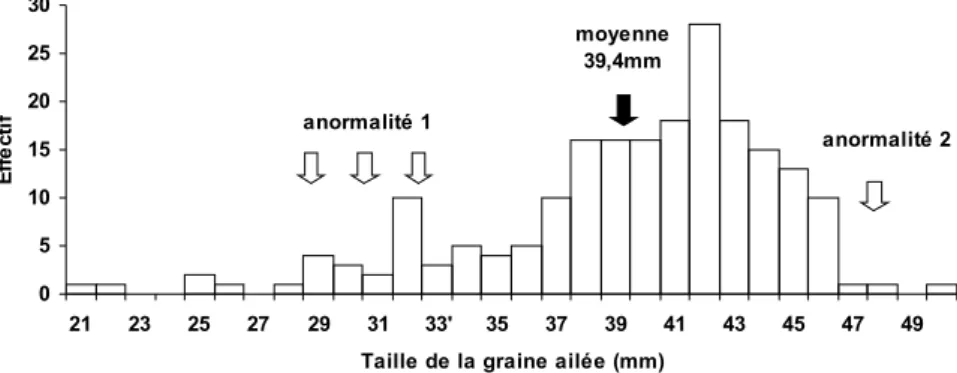
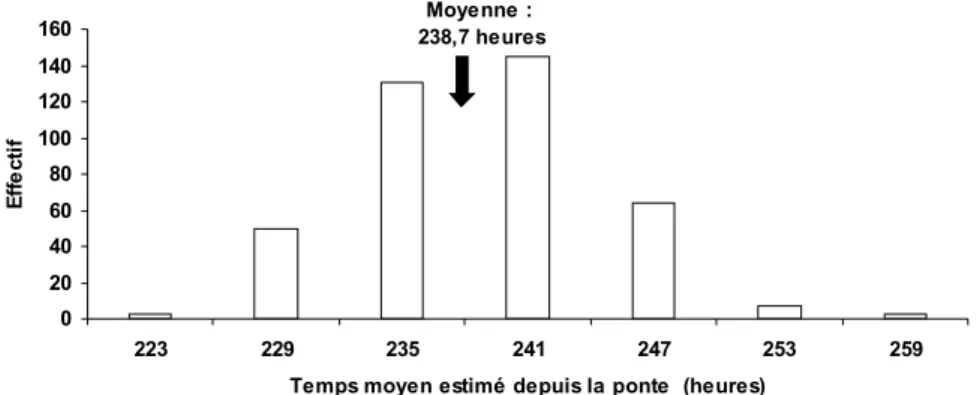
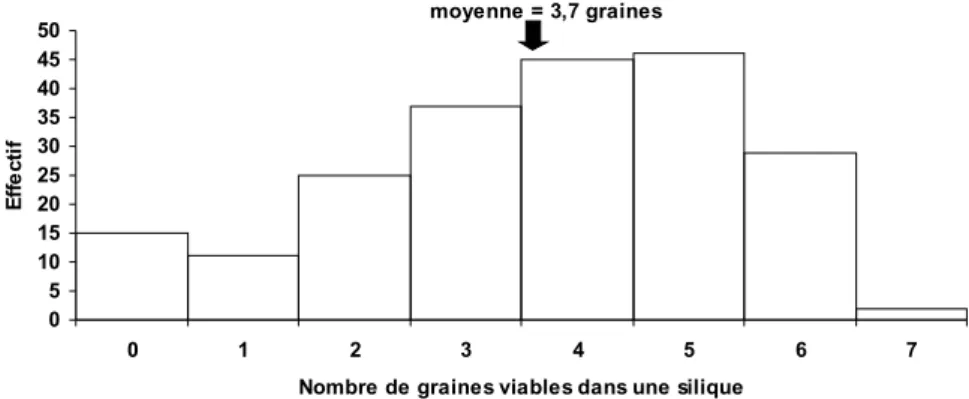
Documents relatifs
Autres médicaments et VEINAMITOL 3500 mg, poudre pour solution buvable en sachet Si vous prenez ou avez pris récemment un autre médicament, y compris un médicament obtenu
• Si vous avez moins de deux années de service ouvrant droit à pension dans le RPENB (y compris le service ouvrant droit à pension dans le régime de la LPRE); moins de deux
Autres médicaments et ALOSTIL 5 %, mousse pour application cutanée en flacon pressurisé Si vous prenez ou avez pris récemment un autre médicament, y compris un médicament obtenu sans
Si vous prenez ou avez pris récemment d’autres médicaments, y compris un médicament obtenu sans ordonnance, parlez-en à votre médecin ou à votre pharmacien.. Interactions avec
