Unity and disunity in evolutionary sciences: process-based analogies open common research avenues for biology and linguistics
Texte intégral
Figure

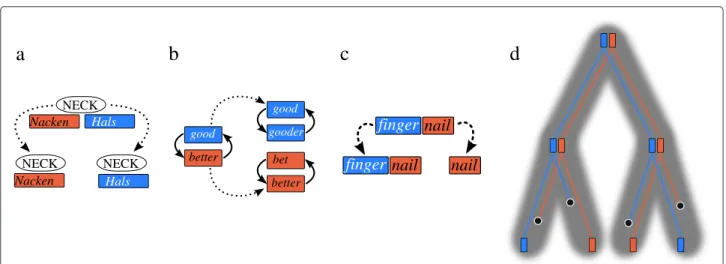
![Fig. 5 Similarity networks applied to linguistic data. a Similarity networks are reconstructed from global alignments for words meaning ‘person’ in Germanic, Romance, and Slavic languages (data taken from [101])](https://thumb-eu.123doks.com/thumbv2/123doknet/13583270.422316/9.892.85.808.130.345/similarity-networks-linguistic-similarity-reconstructed-alignments-germanic-languages.webp)
Documents relatifs
PSEE (Process-centered Software Engineering Environment) are environments designed to support the creation and exploitation of software process models that define
Since the tree structure of OPL words is given by the chain relation, this logic evaluates its formulas on pairs of positions that are either consecutive or in the chain
ABSTRACT This paper presents a comprehensive framework for studying methods of pulse rate estimation relying on remote photoplethysmography (rPPG). There has been a
– exhibits a strong analogy between sorting and Pascal’s triangle, – allows to sort in lattices with quadratic complexity, and that it – is in fact a generalization of insertion
• If the agent is empowered to perform the action, but it is known that the specified performer is not permitted to perform it (i.e. it is prohibited), then the process is finished
In order to maximize the chance of reaching the goals of the OBDA framework and based on observations regarding the previously identified OBDA architecture and the previous
Although there are many types and goals of literature reviews (Cooper, 1988b), all of them can be improved using a tool chain of free and open source software and
The goal of this paper is to discuss the possible benefits of constructing Open Data publication methods from a meta-model and the possible benefits of use of SPEM 2.0 and to
