Call Center Stress Recognition with Person-Specific Models
Texte intégral
Figure

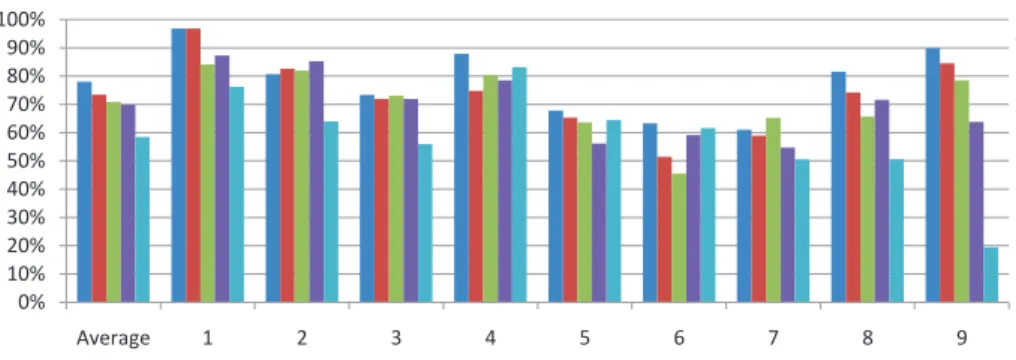
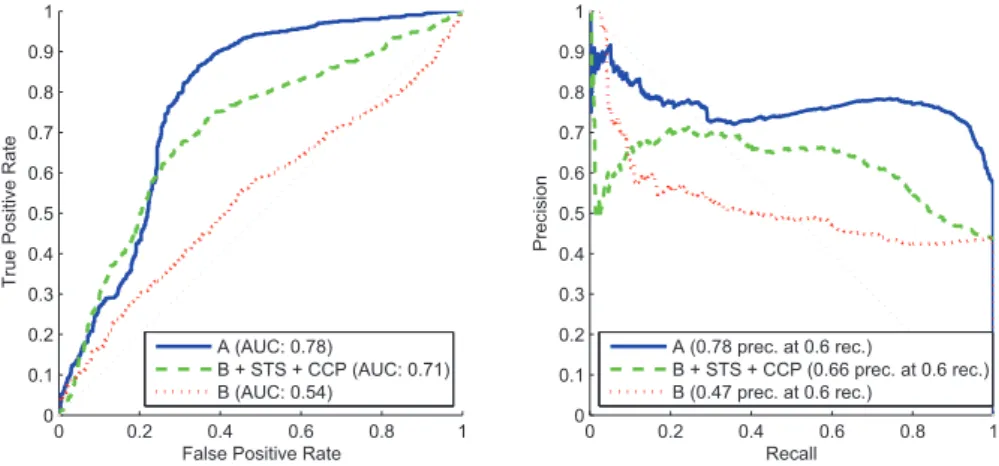
Documents relatifs
5 High Energy Physics Division, Argonne National Laboratory, Argonne IL, United States of America. 6 Department of Physics, University of Arizona, Tucson AZ, United States
Panel a: Evolution of the mixing measure Md as a function of t/δ2 for 30 MD realizations thin lines superimposed to the continuum prediction Mc D = 1.1 red, thick line, where D = 1.1
We compare four different approaches to compute the Chern classes of a tensor product of two vector bundles in terms of the Chern classes of the factors.. Introduction, some
As a conclusion, we reveal that the network is robust towards low frequency perturbations, shows adaptation at moderate stress frequencies, but transitions to
In this paper, it applys Gaussian loss function instead of ε -insensitive loss function in a standard SVRM to devise a new model and a new type of support vector
We consider in ultrahyperbolic Clifford analysis, [1], [5], [6], the rep- resentation of a k-vector function F : Ω → Cl k p,q , with 0 < k < n, in terms of functions
A 2 (sensitivity: taxonomic, thematic) x 2 (domain: living things, non-living things) analysis of variance (ANOVA) was conducted on the number of correct
While in the case of Hume’s view, such a claim is of course controversial, since he was interested in aesthetic judgements about works of art where prima facie anybody feels that
