Limits of random tree-like discrete structures
Texte intégral
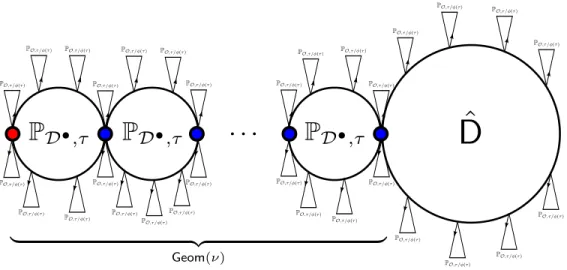
Figure

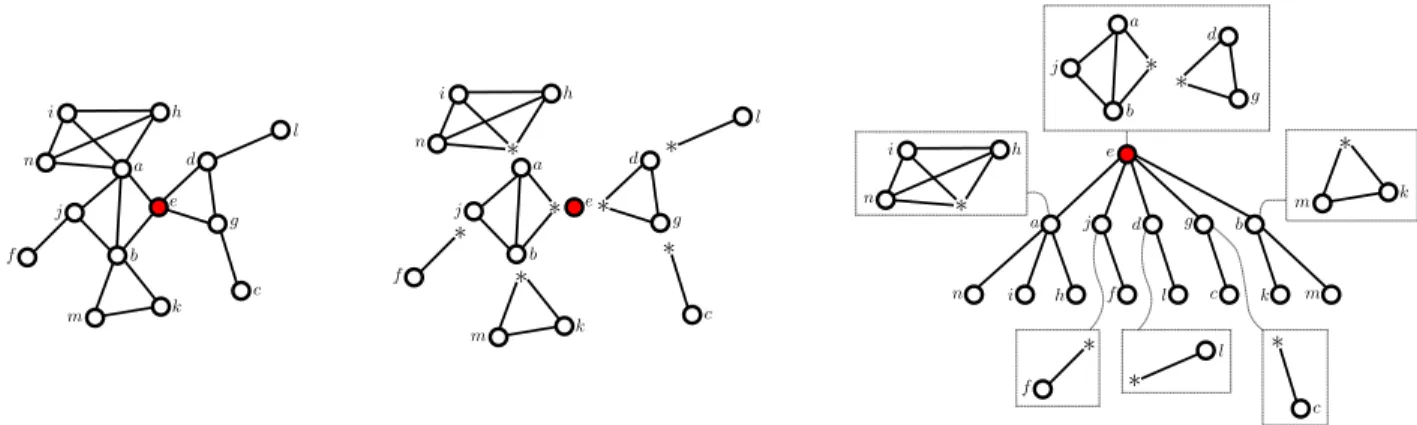
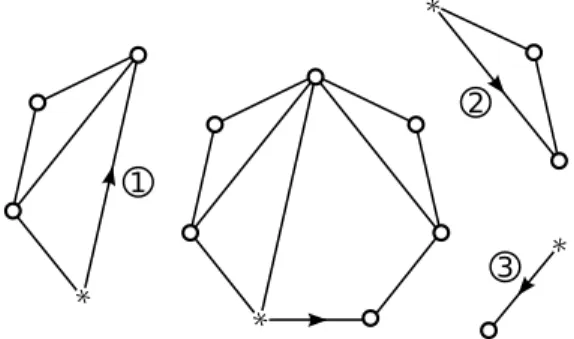
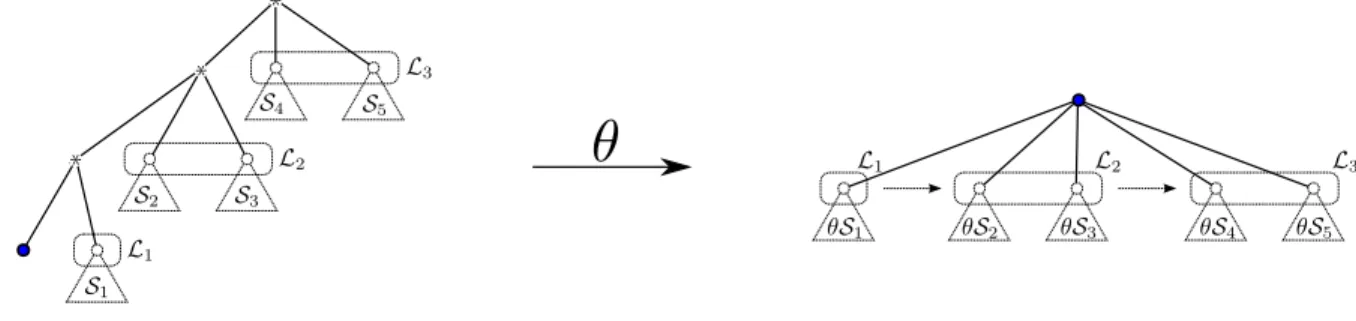
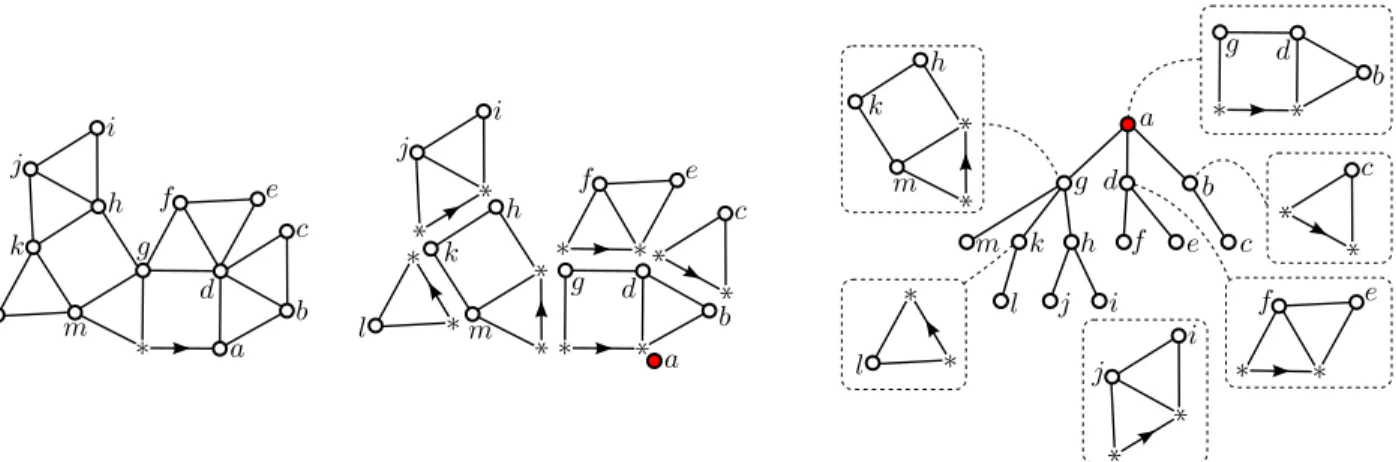
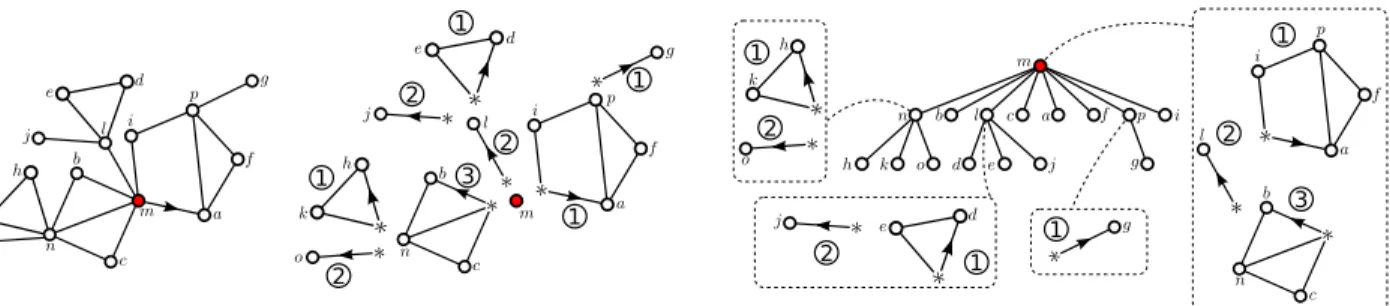
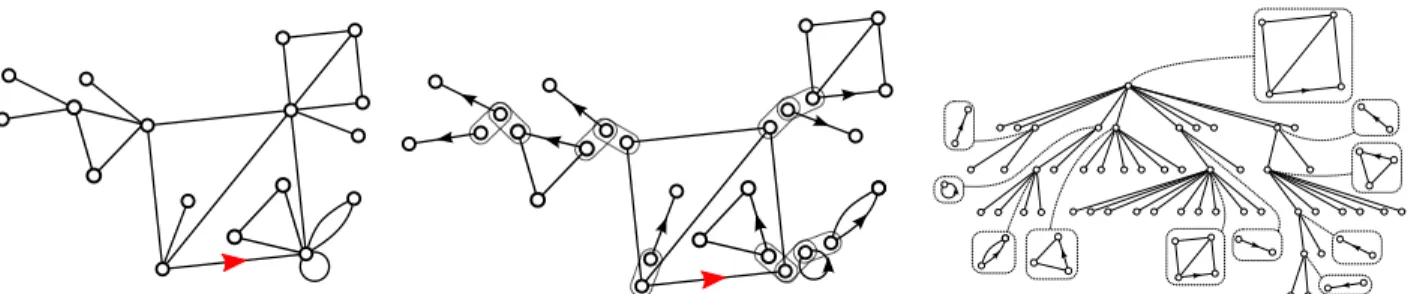
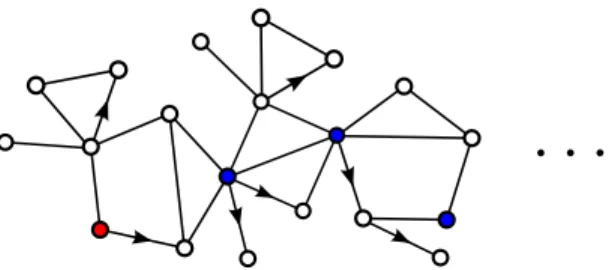
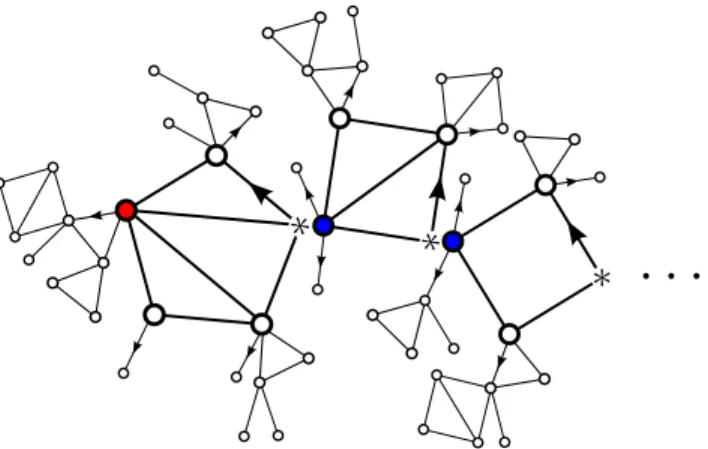
Documents relatifs
The main purpose of this work is to determine the SD of a variety of random graphs called random geometric graphs (RGGs) in the thermodynamic regime, in which the average vertex
In [15], the authors have defined an annealed Ising model on random graphs and proved limit theorems for the magnetization of this model on some random graphs including random
Chapters IV and V tackle the computation of expectation values of observables on random maps and their convergence in the continuous limit in the context of Strebel graphs, that, as
The main purpose of this work is to determine the SD of a variety of random graphs called random geometric graphs (RGGs) in the thermodynamic regime, in which the average vertex
Spectral theory; Objective method; Operator convergence; Stochastic matrices; Random matrices; Reversible Markov chains; Random walks; Random Graphs; Probability on trees; Random
Discrete random planar map models have Liouville quantum gravity as a scaling limit in the metric of weak convergence of area measures.. To be more specific, in addition to
Applications include scaling limits of consistent Markov branching model, and convergence of Galton-Watson trees towards the Brownian and stable continuum random trees.. We also
In the companion paper [ Mar ] we shall obtain the convergence of our general model of random maps towards such limits (as well as the Brownian Continuum Random Tree of Aldous [ Ald93
