Fast Two-Level-Dynamic-Programming Algorithm For Speech Recognition
Texte intégral
Figure
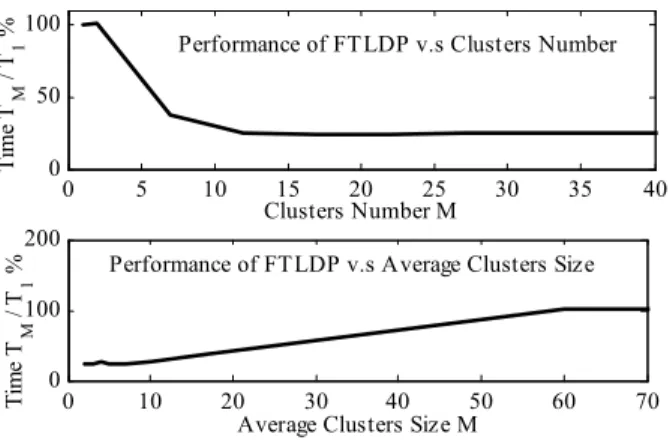
![Figure 1.1: Block diagram for fast speech recognition Without doubting the accuracy or effectiveness of Stage 1 (DSP), the focus of this paper is to have the second stage running a fast TLDP (to help find phone boundaries [8]), but without using HMM pr](https://thumb-eu.123doks.com/thumbv2/123doknet/14192812.478420/3.918.475.815.271.666/figure-diagram-recognition-doubting-accuracy-effectiveness-running-boundaries.webp)


Documents relatifs
In this context, we have developed a new approach for modelling the tire vibrations and the contact with the rigid road surfaces during rolling.. For the tire, a periodic model is
Each class is characterized by its degree of dynamism (DOD, the ratio of the number of dynamic requests revealed at time t > 0 over the number of a priori request known at time t
We also have proven that the use of interval contractors, used to reduce the complexity of SIVIA, can be integrated easily within the presented vector implementation of SIVIA
Dynamic programming with blocs (DP Blocs) decrease the number of la- bels treated by 79% compared to the label correcting algorithm (DP LC), this is due to the reduction of the
We have evaluated the contribution of dynamic program- ming by comparing the disparity map obtained by local methods (Fig. 9a) and imposing global constraints (Fig. 9b) by the
Considering 0.6 mm thick mesa structure (Fig.6), enables to decrease the maximum electric field down to 65 kV/mm, which means that the stress at the triple point is
In addition, thanks to the flat extrinsic gm, the fT of the nanowire channel device showed a high linearity over a wide gate bias range although the maximum value
Ensuite, vous commencez lentement a` en comprendre les caracte´ristiques et vous pouvez partir tout seul comme a` la chasse, ou comme a` la cueillette des champignons, a` la
