Towards Scheduling Evolving Applications
Texte intégral
Figure
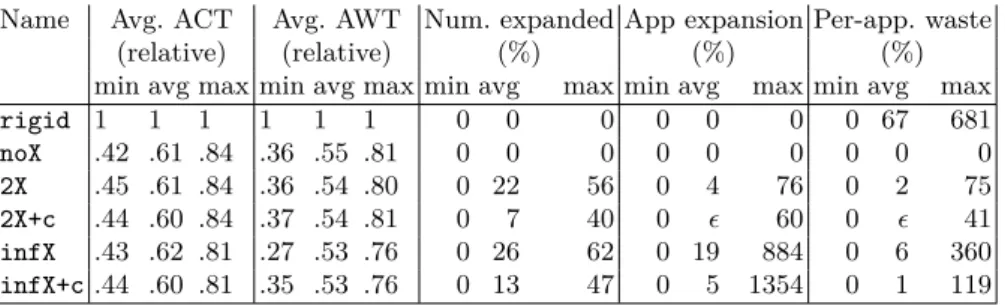
Documents relatifs
(1) If the time average of an interior orbit of the replicator dynamics converges, then the limit is a Nash equilibrium.. Indeed, by Proposition 5.1 the limit is a singleton
Un résultat faux-positif a été obtenu avec le latex Strep B et la souche de Corynebacterium (mais la taille/l’aspect de la colonie était différent(e) de
You 'll find that our complete device programming and handling systems also decrease cost-per-device for programming today's popular devices.. DESIGNED TO QUICKLY
1) If the time average of an interior orbit of the replicator dynamics converges then the limit is a Nash equilibrium.. Indeed, by Proposition 5.1 the limit is a singleton invariant
Running time for computing pairwise distances by finding lower and upper bounds in the SA, and by processing LCP based clusters, as function of the number d of profiles and
Remarque: Si le Internal Control RNA est utilisé comme un contrôle de l’extraction pour la préparation de l’échantillon et comme un contrôle de l’inhibition, il convient
For the class of the almost-periodic functions, a non normal limit distribution for the normalized error of the time average estimate can be obtained when the normalizing factor
Keywords: Information retrieval, Query log analysis, Topic modelling, Users search behaviour, Time sensitive search patterns..
