DIET: A Scalable Toolbox to Build Network Enabled Servers on the Grid
Texte intégral
Figure
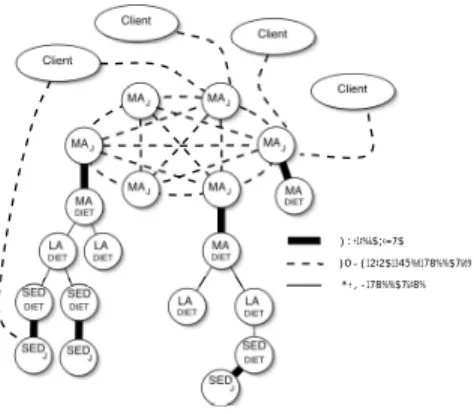
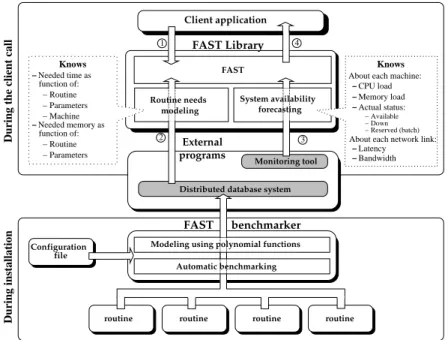
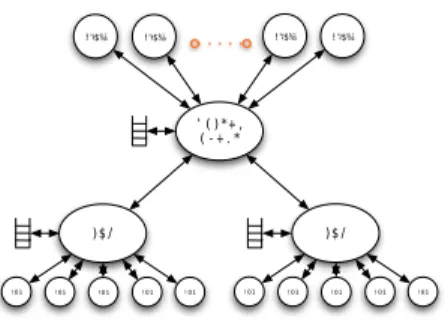

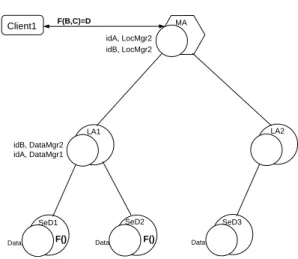
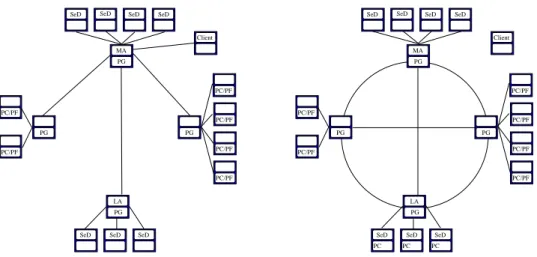
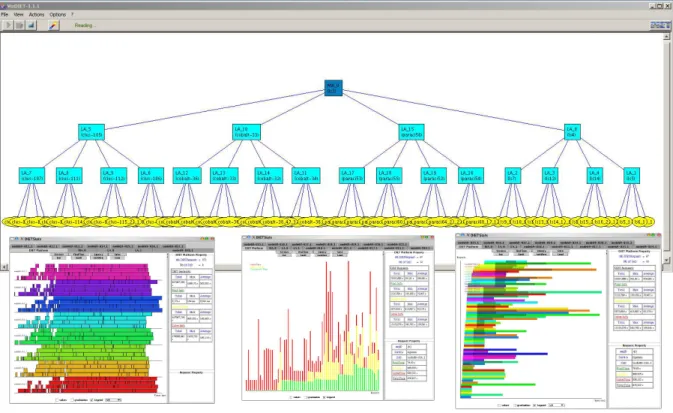
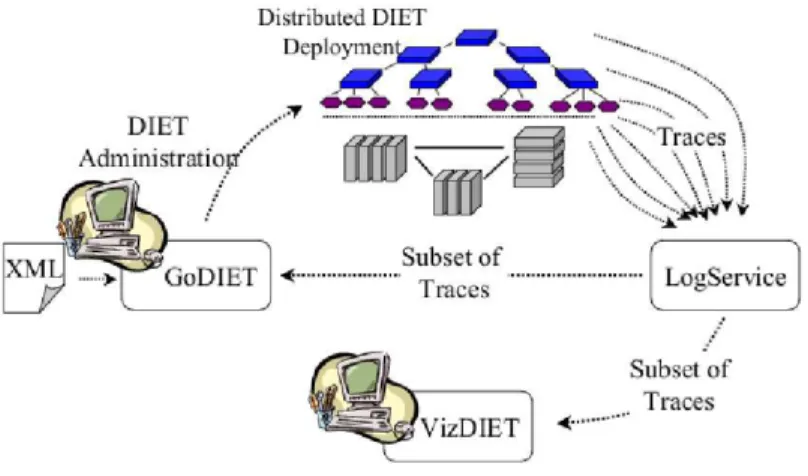
Documents relatifs
This paper presents how traffic accesses different sources of data, leverages processing methods to clean, filter, clip or resample trajectories, and compares trajectory
posterior epidural migration of an extruded lumbar disc fragment. Posterior epidural migration of extruded lumbar
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Une étude rétrospective [93] entre février 2002 et décembre 2005, a été réalisée sur 59 pieds plats valgus traités par arthrodèse articulaire talonaviculaire dans le
Une interface d’interaction avec la cellule hôte inferieure à 6 nm et en forme de petit anneau est ainsi créée, c’est la jonction mobile, (4) les protéines ROP
Unit´e de recherche INRIA Lorraine, Technopˆole de Nancy-Brabois, Campus scientifique, ` NANCY 615 rue du Jardin Botanique, BP 101, 54600 VILLERS LES Unit´e de recherche INRIA
This method uses brain ventricle injection in a living zebrafish embryo, a technique previously developed in our lab 10 , to fluorescently label the cerebrospinal fluid.. Embryos
Replace the point set by its projection on an optimal fit O(k/ ε ²)-subspace and compute a coreset for this subspace (actually, a slightly larger space)..
