2013 — Openicra : vers un modèle générique de déploiement automatisé des applications dans le nuage informatique
Texte intégral
Figure

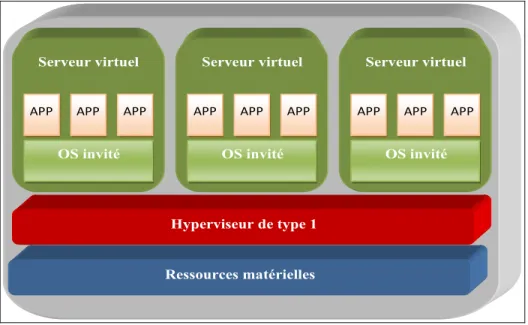

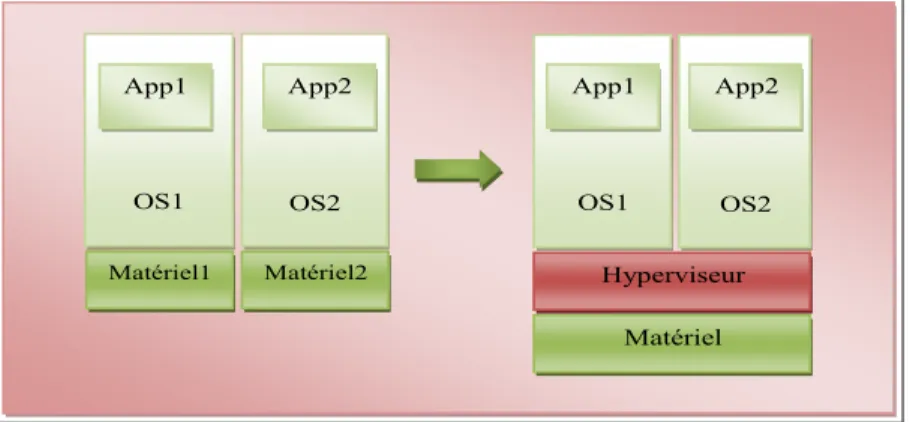
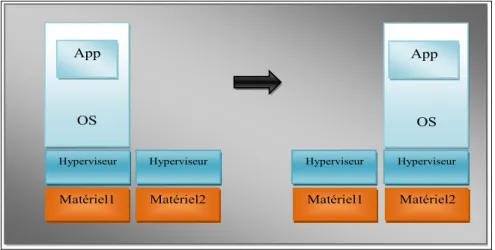
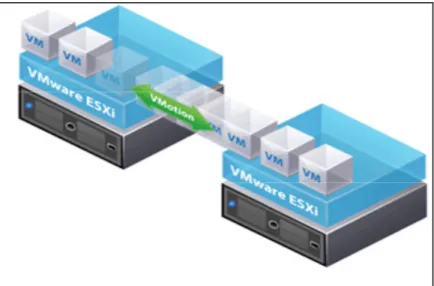
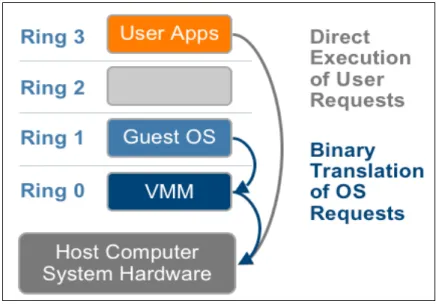

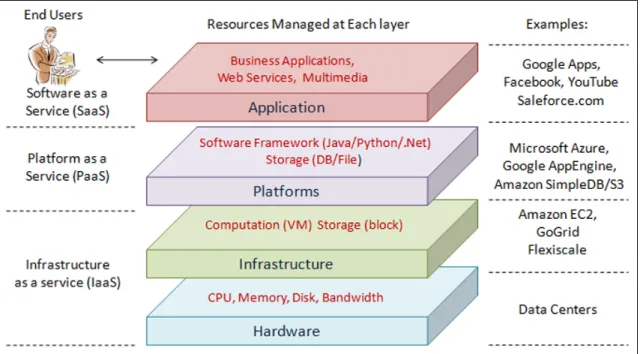

Documents relatifs
Dans un premier temps, nous évaluons les performances du prototype lors d’un dé- ploiement simple, c’est-à-dire que nous prenons en compte le traitement d’une seule re- quête.
Ainsi, les principales contributions de cette thèse sont regroupées au sein d’une plate-forme appelée VAMP (Virtual Applications Management Platform) capable d’assurer le
L’objectif principal de notre travail consiste à concevoir et à développer un nouveau modèle générique de déploiement automatique des applications dans le nuage informatique,
Dans cette unité, vous avez appris les différents projets de grilles tels que la DataGrid qui est un grand projet européen axé sur la construction de l’infrastructure informatique
Soit F une formule de l’arithmétique du second ordre, démontrable en arith- métique du 3ème ordre avec les axiomes : ACD et l’existence d’un ultrafiltre sur N.. Alors F
Nous onsidérons un ensemble de n appliations à déployer sur la grille, es appliations peuvent être soit séquentielles, soit parallèles, soit enore des appliations hiérarhiques1.
Dans le cadre d'une stratégie de gouvernance, gestion des risques et conformité de nuage, les réponses à ces questions vous aideront à développer un Système de gestion de
• Conditions relatives au modèle dynamique de l’usager : Il s’agit de conditions qui s’appuient, soit sur les actions de l’usager au cours de la réalisation de la tâche à
