Dynamic Enrichment of Social Users' Interests
12
0
0
Texte intégral
Figure
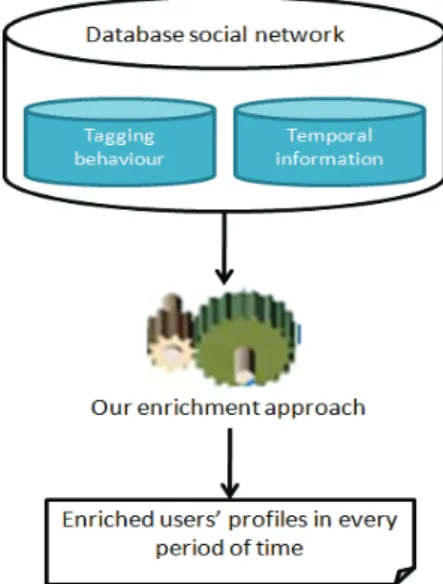
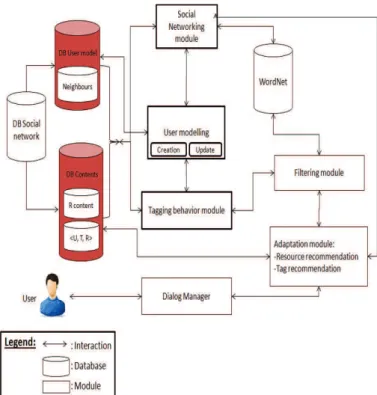
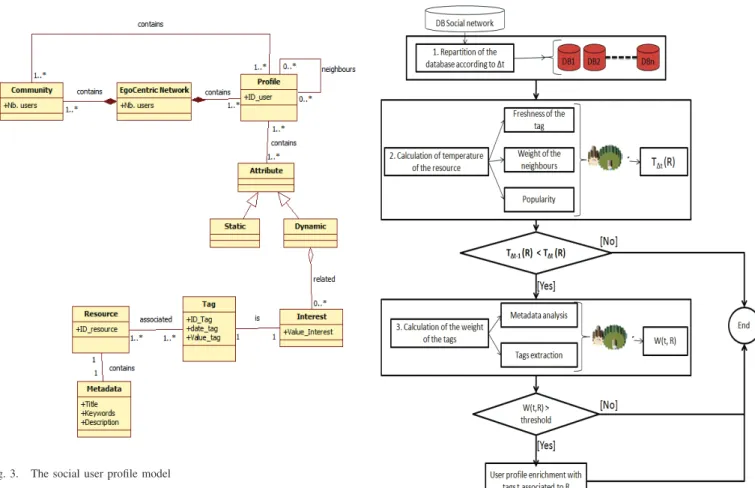

+2
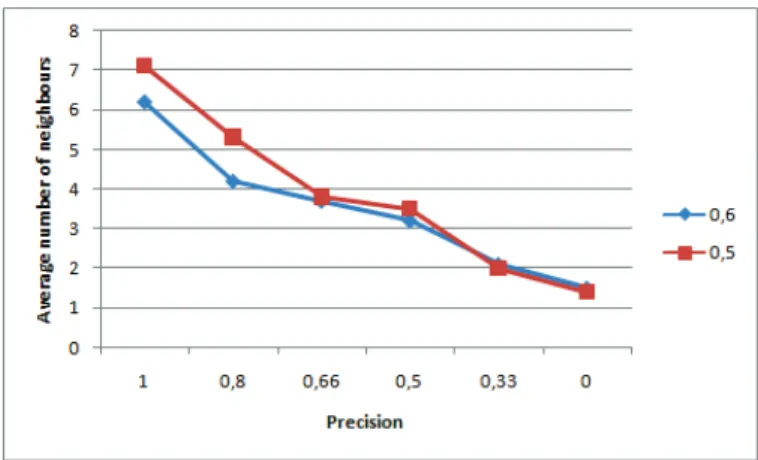
Documents relatifs
