ÉCOLE DE TECHNOLOGIE SUPÉRIEURE UNIVERSITÉ DU QUÉBEC
MÉMOIRE PRÉSENTÉ À
L’ÉCOLE DE TECHNOLOGIE SUPÉRIEURE
COMME EXIGENCE PARTIELLE À L’OBTENTION DE LA
MAÎTRISE EN CONCENTRATION GÉNIE LOGICIEL M. Sc. A.
PAR
Abderrahmane EL BARDAI
VIRTUALISATION D’UNE PLATEFORME DE GESTION DE CONTEXTE
MONTRÉAL, LE 20 OCTOBRE 2015 ©Tous droits réservés, Abderrahmane EL BARDAI, 2015
©Tous droits réservés
Cette licence signifie qu’il est interdit de reproduire, d’enregistrer ou de diffuser en tout ou en partie, le présent document. Le lecteur qui désire imprimer ou conserver sur un autre media une partie importante de ce document, doit obligatoirement en demander l’autorisation à l’auteur.
PRÉSENTATION DU JURY
CE MÉMOIRE A ÉTÉ ÉVALUÉ PAR UN JURY COMPOSÉ DE :
Mme Nadjia Kara, directrice de mémoire
Département de génie logiciel et des TI à l’École de technologie supérieure
Mme May El Barachi, codirectrice de mémoire
Professeure assistante à Collège d’innovation technologique, Université de Zayed
M. Sègla Kpodjedo, président du jury
Département de génie logiciel et des TI à l’École de technologie supérieure
M. Abdelouahed Gherbi, membre du jury
Département de génie logiciel et des TI à l’École de technologie supérieure
IL A FAIT L’OBJET D’UNE SOUTENANCE DEVANT JURY ET PUBLIC LE 14 SEPTEMBRE 2015
REMERCIEMENTS
Mes premiers remerciements vont d’abord à madame Nadjia Kara, professeure au département de génie logiciel à l’école technologie supérieure et directeur du mémoire. Qui m’a chaleureusement accueillie dans son laboratoire de recherche.
Je remercie aussi madame May El Barachi, codirectrice de mémoire professeure à l’Université Zayed d’Abu Dahbi pour son aide précieuse, de l’attention et de soutien qu’elle a portés à mon travail.
Je dédie ce mémoire de fin d’études à mon très cher père EL BARDAI DRISS et ma très chère mère REGRAGUI NAJIBA en témoignage de ma reconnaissance envers le soutien, les sacrifies et les efforts qu’ils ont faits pour mon éducation ainsi que ma formation.
Que ce travail soit le témoignage de notre respect et de notre gratitude pour la bienveillance avec laquelle vous m’avez toujours entourée.
VIRTUALISATION D’UNE PLATEFORME DE GESTION DE CONTEXTE
Abderrahmane EL BARDAI
RÉSUMÉ
Depuis son apparition, le Cloud Computing a motivé différents acteurs du secteur des technologies de l’information à créer de nouveaux services virtuels. Le Cloud Computing apporte beaucoup d’avantages comme la personnalisation, le paiement au besoin ou encore l’effet d’avoir une élasticité infinie.
Les systèmes CA sont des systèmes intelligents qui peuvent changer de comportement dépendamment du contexte dans lequel ils se trouvent. Ce type de système est le genre de système que l’utilisateur final préfère, car il anticipe ses besoins et s’y adapte. Pour avoir, un bon système CA, il faut avoir une bonne base de source d’informations. Ces informations de base permettent à ces systèmes d’être plus précis pour identifier leur contexte actuel. Les réseaux de capteurs sans fil sont une riche source d’information, car ils offrent une information diversifiée et en grand nombre.
Notre projet consiste à virtualiser les systèmes CA en utilisant les réseaux de capteurs sans fil. Notre première contribution consiste à décomposer les systèmes CA en blocs fonctionnels. La deuxième contribution est la proposition d’une architecture de gestion de contexte qui permet la composition et le déploiement de services CA dans le nuage. Cette architecture est validée à travers le prototypage et les tests. Notre dernière contribution est la proposition d’une méthodologie de dimensionnement de ces blocs fonctionnels
VIRTUALISATION OF A CONTEXT MANAGEMENT PLATFORM
Abderrahmane EL BARDAI
ABSTRACT
Since its appearance, Cloud Computing has motivated the different IT actors to create novel virtual services. Cloud Computing paradigm provide great advantages such as personalisation of services, pay-only when needed and seemingly infinite system scalability. Context aware systems are smart systems that can change their behaviour depending on the existing context. This type of system is the kind of systems that the end user wants to interact with because it anticipates the needs of the end user and adapts to them. In order to have a good context aware system, this system needs to have a good source of information. This raw information allows context aware systems to be more precise in identifying the current context. Wireless sensor networks provide a rich amount of raw information and thus can be integrated with context aware systems.
Our project tries to virtualise context aware systems using the information coming from wireless sensor networks. Our first contribution is that we portioned context aware systems to functional blocs named substrates. The second contribution is the proposition of an architecture of a context management platform that allows the composition and the deployment of context aware systems in the cloud. This architecture was validated via prototyping and testing. Our last contribution is that we presented a methodology that helps to dimension the substrates.
TABLE DES MATIÈRES
Page
INTRODUCTION ...1
CHAPITRE 1 REVUE DE LA LITTÉRATURE ...5
1.1 Les réseaux de capteurs ...5
1.1.1 Architecture des RCSFs ... 5 1.2 Les systèmes CA ...7 1.2.1 Exemples d’application ... 7 1.2.2 Fonctionnalités ... 8 1.2.2.1 Acquisition du contexte ... 8 1.2.2.2 Modélisation du contexte ... 11 1.2.2.3 Autres fonctionnalités ... 13 1.3 Le Cloud computing ...14
1.3.1 Les caractéristiques du Cloud ... 14
1.3.2 Les services du Cloud ... 15
1.3.3 Les modèles de déploiement du Cloud ... 17
1.4 Les plateformes de gestion de contexte ...18
1.5 Conclusion ...19
CHAPITRE 2 ARCHITECTURE PROPOSÉE ...21
2.1 Scénarios motivants ...21
2.2 Présentation des substrates reliées aux systèmes CA ...25
2.3 La vue globale ...27 2.4 Architecture logicielle ...29 2.4.1 La couche de plateforme ... 30 2.4.2 La couche d’infrastructure ... 33 2.4.3 Le dépôt de données (Broker) ... 34 2.5 Diagrammes de séquences ...35 2.5.1 La séquence de découverte ... 35 2.5.2 Séquence d’instanciation ... 37 2.5.3 Séquence d’exécution ... 40 2.6 Conclusion ...42
CHAPITRE 3 IMPLÉMENTATION DE LA PLATEFORME DE GESTION DE CONTEXTE ...43 3.1 Diagramme de classe ...43 3.1.1 Le fournisseur de plateforme ... 43 3.1.2 Le fournisseur d’infrastructure ... 45 3.2 Les substrates ...47 3.2.1 Acquisition ... 47 3.2.2 Modélisation ... 48 3.2.3 Dissemination ... 51
XII
3.2.4 Stockage ... 52
3.2.5 Inférence ... 52
CHAPITRE 4 ANALYSE DES PERFORMANCES DE LA PLATEFORME DE GESTION DE CONTEXTE ...55
4.1 Technologies et outils de développement ...55
4.2 Environnement de test...59
4.3 Tests de la plateforme ...60
4.3.1 Validité et fiabilité des outils de mesure ... 61
4.3.2 Temps de réponse ... 63
4.3.3 Tests de changement de données ... 64
4.3.4 Tests de stress ... 67
4.4 Dimensionnement de la plateforme de gestion de contexte ...81
4.4.1 Régression linéaire ... 81
4.4.2 Méthodologie de dimensionnement ... 97
4.5 Conclusion ...101
CONCLUSION ...103
ANNEXE I INSTALLATION DE ZABBIX SUR UBUNTU 12.04 LTS ...105
ANNEXE II INSTALLATION DE KVM ET CRÉATION DE MACHINES VIRTUELLES ...107
ANNEXE III PRÉSENTATION DE L’INTERFACE GRAPHIQUE DE LA COUCHE PLATEFORME ...111
ANNEXE IV FICHIER DE CONFIGURATION DES SUBSTRATES ...113
ANNEXE V FICHIER DE COMPOSITION DE SERVICE ...115
ANNEXE VI MODÈLE DE DONNÉES XML IMPLÉMENTÉ COMPLET ...119
ANNEXE VII INSTALLATION ET CRÉATION D’UNE BDD AVEC POSTGRESQL 9.1...125
LISTE DES TABLEAUX
Page
Tableau 3-1 Liste des interfaces REST du substrate acquisition ...48
Tableau 3-2 Interface REST du substrate modeling ...51
Tableau 3-3 Interfaces REST du substrate dissemination ...51
Tableau 3-4 Interface REST du substrate storage ...52
Tableau 3-5 Interfaces REST du substrate inference ...53
Tableau 4-1 Comparatif entre les différents SGBD ...58
Tableau 4-2 Temps de réponses des requêtes des clients ...64
Tableau 4-3 Utilisation maximale de la RAM par les différentes substrates ...80
Tableau 4-4 Résultats de la régression linéaire pour le subsrate modeling ...83
Tableau 4-5 Modèle de régression linéaire pour le substrate Modeling ...84
Tableau 4-6 Résultats de la régression linéaire pour le subsrate dissemination ...84
Tableau 4-7 Modèle de régression linéaire pour le substrate dissemination ...85
Tableau 4-8 Résultats de la régression linéaire pour le subsrate acquisition ...85
Tableau 4-9 Modèle de régression linéaire pour le substrate acquisition ...86
Tableau 4-10 Résultats de la régression linéaire pour le subsrate storage ...86
Tableau 4-11 Modèle de régression linéaire pour le substrate storage ...86
Tableau 4-12 Résultats de la régression linéaire pour le subsrate inference ...87
LISTE DES FIGURES
Page
Figure 1-1 Architecture d’un RCSF. ...6
Figure 1-2 Couche d’abstraction de capteur ...11
Figure 1-3 Architecture du Cloud ...16
Figure 2-1 Les acteurs du magasinage intelligent ...22
Figure 2-2 La vue générale ...29
Figure 2-3 Architecture logicielle de la plateforme de gestion de contexte ...30
Figure 2-4 Diagramme de séquence de la phase découverte des ressources ...36
Figure 2-5 Diagramme de séquence de la phase d’instanciation ...38
Figure 2-6 Diagramme de séquence de la phase d’exécution ...41
Figure 3-1 Diagramme de classe de la couche plateforme ...44
Figure 3-2 Diagramme de classe de la couche infrastructure ...46
Figure 3-3 Exemple de format des données du substrate acquisition ...48
Figure 3-4 Modèle de données XML implémenté ...50
Figure 4-1 Environnement des tests de performances ...60
Figure 4-2 Utilisation du CPU de la substrate modeling en état inactif ...62
Figure 4-3 Utilisation du CPU de la substrate modeling en état inactif ...62
Figure 4-4 Effet de Collectd sur l’utlilsation du CPU de la substrate modeling ...63
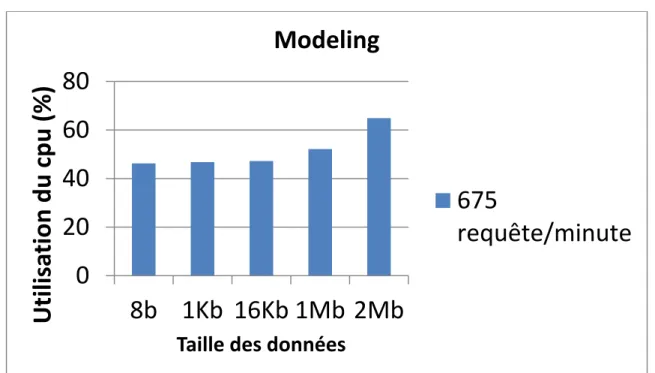
Figure 4-5 Utilisation du CPU de la substrate modeling en fonction ...65
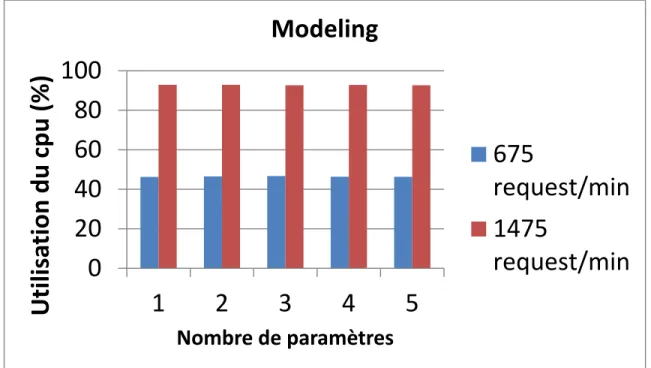
Figure 4-6 Utilisation du CPU de la substrate modeling en fonction ...66
Figure 4-7 Utilisation du CPU de la substrate inference en fonction ...67
XVI
Figure 4-9 Utilisation du CPU de la substrate modeling en utilisant deux cœurs ...69
Figure 4-10 Utilisation du CPU de la substrate inference avec trois cœurs ...69
Figure 4-11 Utilisation du CPU de la substrate modeling avec quatre cœurs ...70
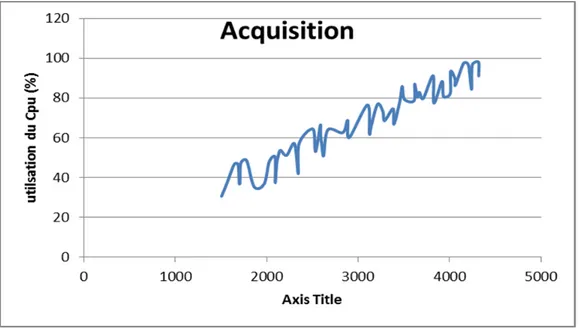
Figure 4-12 Utilisation du CPU de la substrate acquisition avec un seul coeur ...70
Figure 4-13 Utilisation du CPU de la substrate modeling avec deux cœurs ...71
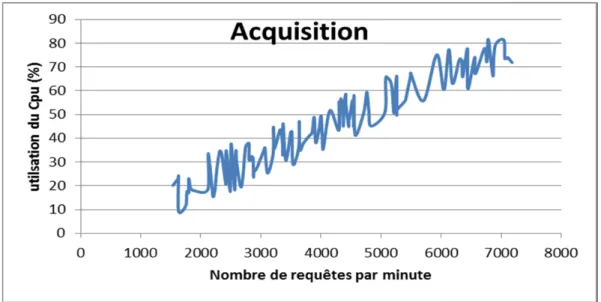
Figure 4-14 Utilisation du CPU de la substrate acquisition avec trois coeurs ...71
Figure 4-15 Utilisation du CPU de la substrate acquisition avec quatre cœurs ...72
Figure 4-16 Utilisation du CPU de la substrate modeling avec un seul coeur ...72
Figure 4-17 Utilisation du CPU de la substrate dissemination avec deux cœurs ...73
Figure 4-18 Utilisation du CPU de la substrate dissemination avec trois coeurs ...73
Figure 4-19 Utilisation du CPU de la substrate dissemination avec quatre cœurs ...74
Figure 4-20 Utilisation du CPU de la subtrate storage avec un seul cœur ...74
Figure 4-21 Utilisation de la substrate storage avec deux cœurs ...75
Figure 4-22 Utilisation de la substrate storage avec trois cœurs ...75
Figure 4-23 Utilisation de la substrate storage avec quatre coeurs ...76
Figure 4-24 Utilisation du CPU de la substrate niference avec un seul coeur ...76
Figure 4-25 Utilisation du CPU de la substrate inference avec deux cœurs ...77
Figure 4-26 Utilisation du CPU de la substrate inference avec trois cœurs ...77
Figure 4-27 Utilisation de la substrate inference avec quatre cœurs ...78
Figure 4-28 Effet de la charge sur le trafic réseau ...79
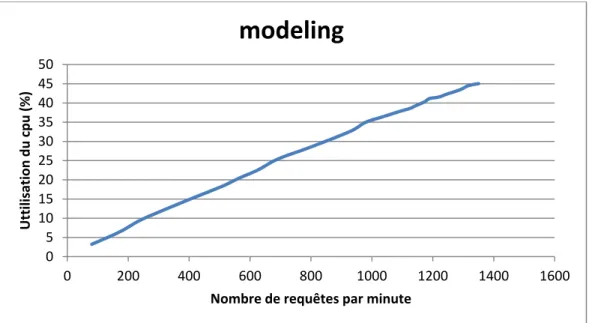
Figure 4-29 Utilisation du CPU de la substrate modeling avec un seul cœur ...88
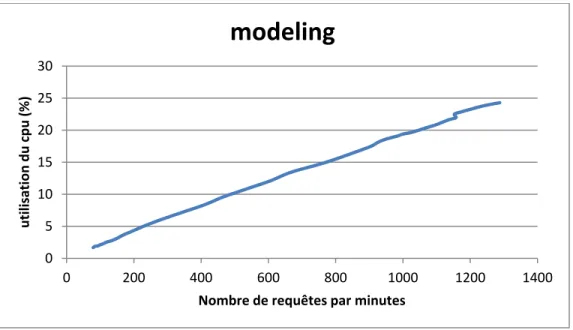
Figure 4-30 Utilisation du CPU de la substrate modeling avec deux cœurs ...88
Figure 4-31 Utilisation du CPU de la substrate modeling avec trois cœurs ...89
XVII
Figure 4-33 Utilisation du CPU de la substrate dissemination avec un seul cœur ...90
Figure 4-34 Utilisation du CPU de la substrate dissemination avec deux cœurs ...90
Figure 4-35 Utilisation du CPU de la substrate dissemination avec trois cœurs ...91
Figure 4-36 Utilisation du CPU de la substrate dissemination avec quatre cœurs ...91
Figure 4-37 Utilisation du CPU de la substrate acquisition avec un seul cœur ...92
Figure 4-38 Utilisation du CPU de la substrate acquisition avec deux cœurs ...92
Figure 4-39 Utilisation du CPU de la substrate acquisition avec trois cœurs ...93
Figure 4-40 Utilisation du CPU de la substrate acquisition avec quatre cœurs ...93
Figure 4-41 Utilisation du CPU de la substrate storage avec un seul cœur ...94
Figure 4-42 Utilisation du CPU de la substrate storage avec deux cœurs ...94
Figure 4-43 Utilisation du CPU de la substrate storage avec trois cœurs ...95
Figure 4-44 Utilisation du CPU de la substrate storage avec quatre cœurs ...95
Figure 4-45 Utilisation du CPU de la substrate inference avec un seul cœur ...96
Figure 4-46 Utilisation du CPU de la substrate inference avec deux cœurs ...96
Figure 4-47 Utilisation du CPU de la substrate inference avec trois cœurs ...97
Figure 4-48 Utilisation du CPU de la substrate inference avec quatre cœurs ...97
LISTE DES ABRÉVIATIONS, SIGLES ET ACRONYMES
BDD Base de données
CA Context aware
CC Nuage Computing CPU Central Processing Unit IAAS Infrastructure As a Service I/O Input/Output
PAAS Platform As a Service RCSF Réseau de capteur sans fils SAAS Software As a Service
SAC CA
INTRODUCTION
Depuis leur apparition, les réseaux de communication sans fil ont connu un large succès. Grâce à leurs nombreux avantages, ces réseaux ont pu s’imposer comme acteurs incontournables dans les architectures réseau actuelles. Les réseaux sans fil offrent en effet des propriétés intéressantes, qui peuvent être résumées en trois points : la facilité du déploiement, l’omniprésence de l’information et le coût réduit d’installation. Un réseau de capteurs sans fil est un réseau sans fil composé de nœuds capteurs distribués spatialement dans un environnement donné. Ces capteurs surveillent différents types de données environnementales comme la température et l’humidité ou physiques comme la pression sanguine et la température du corps humain, etc. Par ailleurs, la collecte des données n’est pas en elle-même une finalité, mais juste un moyen pour d’autres systèmes qui traitent les données.
Après l’explosion de la bulle internet, l’informatique occupe une partie importante de notre quotidien. L’intégration des circuits électroniques dans les véhicules, l’omniprésence de la téléphonie mobile intelligente, l’arrivée sur le marché des ordinateurs portables ultra-performants donnent une idée de ce qui peut nous attendre en informatique dans les années à venir : de plus en plus de mobilité, de communication entre machines qui ressemble de plus en plus au langage humain et des utilisateurs s’attendant à ce que leurs appareils répondent à des attentes motivées aussi par leur environnement. Les systèmes CA sont là pour répondre à ces besoins. Puisque ces systèmes tirent leur information d’une source de contexte, l’utilisation des réseaux de capteurs comme source de contexte devient un volet de recherche intéressant. Cependant, avec tant d’informations fournies par les réseaux de capteurs, l’intégration de ces réseaux dans d’autres systèmes peut créer plusieurs défis. Les différents protocoles de communications utilisés et les différentes représentations des données capturées créent un problème d’hétérogénéité. La puissance de traitement nécessaire est accrue dû à la quantité des données et le stockage des données devient difficile à cause des différents formats de données et à cause de la vitesse de stockage/extraction des données.
2
Tous ces facteurs ont eu pour effet de freiner le déploiement et l’évolution commerciale de ce type de systèmes.
Problématique
Les systèmes CA sont des systèmes qui réagissent au contexte dans lequel ils se trouvent. Ce contexte est la combinaison d’une ou plusieurs données simples qui sont à la disposition de ces systèmes. Les données fournies par les réseaux capteurs sont de bonnes données à utiliser pour construire le contexte. Il serait donc intéressant de pouvoir intégrer les réseaux sans fil dans les systèmes CA. Ces systèmes sont monolithiques se présentant comme un bloc logiciel devant le client. Le fournisseur de ce type de systèmes offre un service prêt à être utilisé cependant, il n’est pas flexible et personnalisable, car il se peut que le système fournisse plusieurs services. Par ailleurs, le client n’apprécie pas un service particulier dans ce système ou bien tout simplement n’est pas intéressé par un service donné parmi les autres ou bien le client apprécie les différents services, mais la performance du système en cas de forte charge est mauvaise. Par contre, le Cloud Computing offre cette flexibilité et cette élasticité. La principale question est comment rendre ces systèmes CA plus personnalisé, plus puissant et plus optimal en termes de ressources (matérielles et financières).
Avec l’apparition du paradigme du Cloud Computing, qui consiste à fournir différents types de services à travers internet, l’idée d’intégrer les systèmes CA dans le Nuage devient intéressante; car elle permettra de pallier aux défis et limitations rencontrées précédemment. Ainsi, en rendant les systèmes CA modulaires, on peut fournir chaque module comme service dans le nuage et créer des systèmes CA composés de ces blocs fonctionnels. En faisant comme suit le client peut obtenir un système personnalisé, car il le compose lui-même et ne va payer que sur les services dont il a besoin (propriété du nuage) et ne se souciera pas des problèmes reliés aux ressources matérielles (élasticité : propriété du nuage). Donc, la principale question qui se pose est comment rendre les applications CA modulaires tout en intégrant les réseaux de capteurs? Comment peut-on fournir au client une plateforme qui lui permet de créer des services CA à partir des blocs fonctionnels fournis aussi comme service?
3
Objectifs
Les principaux objectifs de ce projet sont :
• La réalisation d’une analyse détaillée sur les réseaux de capteurs sans fil, des systèmes CA et de leur intégration dans le Nuage;
• Définir les principaux blocs fonctionnels qui composent les systèmes CA et proposer une architecture dans le Nuage qui permet la composition et le déploiement dynamique de services CA;
• Développer une plateforme de gestion de contexte;
• Tester les performances de la plateforme de gestion de contexte et les différentes substrates;
• Proposer un algorithme de gestion des ressources physiques pour une plateforme de gestion de contexte.
Plan du mémoire
Ce document commence par une introduction générale du projet et de son contexte. Il contient aussi la problématique du mémoire et ses objectifs.
Le premier chapitre est la revue de la littérature. Nous commençons tout d’abord par présenter les réseaux des capteurs sans fil. Ensuite, nous décrirons en détail les systèmes CA. Puis, nous analyserons le paradigme du Nuage. Enfin, nous passons en revue quelques travaux de recherche reliés aux systèmes CA implémentés dans le nuage.
Dans le deuxième chapitre, nous proposons des scénarios concrets qui peuvent être implémentés et qui motivent notre travail de recherche. Nous décrirons ensuite les différentes entités qui constituent les systèmes CA. Nous poursuivons en présentant une vue globale de
4
l’architecture. Ensuite, nous détaillerons l’architecture logicielle de la plateforme gestion de contexte proposée et les différents diagrammes de séquences reliés.
Le troisième chapitre décrit un prototype d’une plateforme de gestion de contexte et présente l’analyse des performances d’une telle infrastructure. D’abord, nous décrirons les différents diagrammes de classe de notre plateforme. Ensuite, nous expliquerons, l’implémentation des différents substrates développés.
Dans le quatrième chapitre, nous présentons l’environnement de test, les résultats des tests effectués et l’analyse de ces résultats. Puis, nous présenterons un algorithme de gestion de ressources physiques pour la plateforme de gestion de contexte.
Enfin, nous terminons avec une conclusion générale sur notre travail de recherche et présenterons quelques travaux futurs.
CHAPITRE 1
REVUE DE LA LITTÉRATURE 1.1 Les réseaux de capteurs
Les réseaux de capteurs sans fil (RCSF) sont composés d’un large nombre de nœuds capteurs déployés d’une façon dense dans un environnement cible.
1.1.1 Architecture des RCSFs
L’architecture classique des RCSFs est illustrée dans la figure 1-1. Les nœuds capteurs sont dispersés dans le domaine dans lequel la capture est souhaitée. Les nœuds capteurs possèdent une portée de transmission faible et communiquent avec les nœuds adjacents pour acheminer les captures vers la passerelle. La passerelle est connectée à un médium longue distance et sert de lien entre les nœuds capteurs et les clients. Le nœud capteur est l’entité de base des RCSFs et sont déployés en grand nombre. Un nœud capteur comporte au moins ces quatre composants :
• Unité de détection : cette unité peut comporter plusieurs capteurs pour détecter différents types de phénomènes et d’un convertisseur qui convertiront les différents signaux analogiques en signaux numériques pour les envoyer à l’unité de traitement; • Unité de traitement : cette unité gère en collaboration avec les autres unités de
traitement la mission de mener à bien les tâches de détection. Cette unité contient en général un composant qui permet le stockage des données;
• Unité de transmission : ce composant est responsable de connecter le nœud capteur au réseau;
• Unité d’alimentation : ce composant assure les besoins énergétiques des différentes unités du nœud capteur.
6
D’autres unités facultatives peuvent aussi être présentes dans un nœud capteur par exemple un générateur de courant qui transforme une énergie non électrique en courant utilisable par l’unité d’alimentation.
Figure 1-1 Architecture d’un RCSF. Tirée de Jason Lester Hill (2003)
Pour concevoir et déployer un RCSF, plusieurs facteurs doivent être pris en considération. Dans cette partie, nous essayerons de citer les plus importants :
• La fiabilité : c’est la capacité du réseau à réussir la tache de détection sans interruption malgré la défaillance de certains nœuds capteurs au sein du réseau. On désigne par défaillance toute mesure ou capture considérée fausse et non pas seulement l’arrêt du fonctionnement du nœud capteur;
• L’évolutivité : c’est la capacité du système à subvenir de manière dynamique aux besoins évolutifs en termes de ressources;
• Les coûts de production : puisque les RCSFs exigent par leur nature un large nombre de nœuds capteurs alors le prix unitaire de ces nœuds doit être justifiable. Un coût élevé aura systématiquement comme résultat l’abandon d’une solution RCSF;
7
• La consommation d’énergie : les nœuds de capteurs possèdent des ressources limitées en termes d’énergie. Certains scénarios d’applications peuvent trop utiliser les ressources du nœud capteur et se montrent très gourmant vis-à-vis la consommation d’énergie au point que la batterie ne puisse plus maintenir les besoins de l’application;
• L’environnement de déploiement : les RCSFs ont un large domaine d’applicabilité ce qui confère une grande variété d’environnement de déploiements. Le choix de nœuds capteurs adaptés à l’environnement de déploiement est donc primordial;
• Les médias de transmission : les différents médiums utilisés doivent être fiables dans le sens où la probabilité d’acheminer des informations fausses à partir de données correctes est faible, résistants aux différents types d’environnements (les médiums hertziens sont très sensibles aux détériorations climatiques) et efficaces dans la consommation d’énergie.
1.2 Les systèmes CA
Les systèmes CA (SAC) sont des systèmes qui possèdent la capacité de changer de comportement dépendamment de la situation qui entoure l’environnement d’exécution. Ces systèmes donnent naissance à un nouveau type d’applications : plus intelligentes, plus intuitives et tendent à comprendre les intentions de l’utilisateur et agissent en fonction de ces intentions. La situation ou le contexte n’est pas limité seulement à l’utilisateur final, son profil et ses préférences, mais aussi à d’autres éléments par exemple le lieu dans lequel il se trouve, un facteur de temps, l’état du matériel, etc.
1.2.1 Exemples d’application
Dans cette partie, nous essayerons de donner deux scénarios qui illustrent les avantages des systèmes CA.
8
Dans le domaine de la santé, on peut considérer une application SAC qui permet de surveiller à distance l’état des patients. Les capteurs envoient régulièrement des informations sur l’état du patient par exemple la fréquence cardiaque, la vitesse de déplacement, la localisation. L’application se chargera en temps normal à l’aide d’un pilulier intelligent de rappeler la personne responsable du patient par SMS ou autre type de média (e-mail, alarme…) des médicaments qu’il doit prendre. En cas de comportement jugé anormal comme par exemple une crise cardiaque, l’application se chargera de contacter l’entité la plus proche de lui qui peut lui venir en aide.
Une autre application intéressante est dans le domaine social. Un assistant de vie intelligent inspiré de l’application lancée par Nike nommée Nike+ training App. Les chaussures sportives de la nouvelle génération comportent des capteurs et fournissent différents types de données : saut vertical, la vitesse, le nombre de sauts effectués lors d’un entraînement, la durée en l’air durant les sauts, la fréquence cardiaque et le taux de glucose dans le sang. Toutes ces informations sont envoyées à un mobile intelligent dans lequel l’utilisateur peut visionner ses performances, les partager dans un réseau et rivaliser et se comparer à d’autres utilisateurs. L’application peut aussi fournir des indications et des conseils pour améliorer les performances et elle peut aussi proposer des programmes d’entraînements pour atteindre des objectifs fixés.
1.2.2 Fonctionnalités
Les systèmes SAC sont des systèmes complexes et leur compréhension est essentielle pour le bon déroulement du projet. Dans ce qui suit, nous essayerons d’éclaircir les principales fonctionnalités des systèmes SaC.
1.2.2.1 Acquisition du contexte
L’acquisition du contexte est une fonctionnalité initiale et de base. Dans cette phase nous collectons de l’information contextuelle depuis les différentes sources de contexte. Nous définissons le contexte par « toute information qui peut être utilisée pour caractériser la
9
situation d’une entité. Une entité peut être une personne, une place, ou un objet qui s’avère pertinent à l’interaction entre l’utilisateur et l’application » (Devajaru, Hoh et Hartle, 2007). L’information qui constitue le contexte peut provenir de deux types de sources :
• Sources physiques : ce sont les mesures qui proviennent des différents nœuds capteurs des RCSFs. Ils représentent des mesures associées à des phénomènes physiques par exemple la température, la pression, l’humidité…
• Sources logiques : ce sont des mesures qui représentent des états logiques d’entités contextuelles. Par exemple : la bande passante du réseau, la fiabilité des mesures des nœuds capteurs…
Il existe trois méthodes d’acquisition de contexte : soit par accès directs aux ressources physiques. Dans ce cas les capteurs et le module d’acquisition se trouvent sur le même appareil. Cette méthode est pratique, mais le contexte collecté est limité et n’est pas adapté aux systèmes distribués. Soit à travers un intergiciel ou bien à travers une base de données. L’acquisition du contexte est une grande fonctionnalité et peut être composée de plusieurs sous-fonctionnalités :
• La détection des données : c’est la capacité du module à recevoir les mesures des nœuds capteurs et aussi envoyer des commandes vers ces nœuds;
• Le balayage : cette fonctionnalité permet la découverte dynamique des ressources du réseau et permet aussi d’identifier l’ensemble de nœuds capteurs optimaux pour effectuer une tâche de détection;
• L’agrégation : consiste à fusionner un grand nombre de mesures pour en tirer des valeurs significatives par exemple une moyenne de valeurs ou une variance. Cette opération a pour effet d’alléger l’effort de traitement et de stockage. Et donc, optimise l’utilisation des ressources;
• L’adaptation : on désigne par l’adaptation l’obtention de l’information que lorsque l’on a vraiment besoin de celle-ci.
À cause de l’aspect propriétaire et la diversité des technologies des RCSFs, les développeurs de systèmes SaC développent leurs propres modules d’acquisition de contexte
10
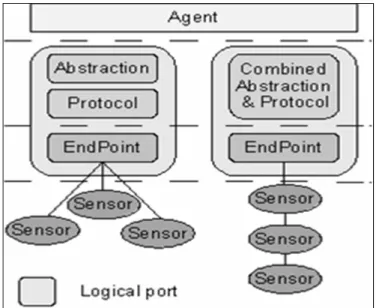
dépendamment de la technologie implémentée dans le RCSF. Dans ce sens, plusieurs travaux de recherches ont été réalisés proposant des solutions qui effectuent l’acquisition du contexte indépendamment de la technologie utilisée dans les RCSFs. On cite par exemple les travaux de Devajaru, Hoh et Hartle (2007) et de Gigan et Atkinson (2007). La solution proposée par Gigan et Atkinson est particulièrement intéressante, car elle introduit une couche d’abstraction qui cache les détails et les spécifications matérielles des nœuds capteurs. La figure 1-2 illustre l’architecture de cette solution décomposée en trois niveaux.
La couche agent supérieure est responsable de communiquer avec les clients de la solution. Elle reçoit les paquets, les analyse puis fait appel aux méthodes appropriées de la couche inférieure et envoie les réponses de requêtes aux clients. La couche suivante est la couche de communication. Cette couche fournit des APIs et des fonctions génériques qui permettent le contrôle et la gestion des différents capteurs indépendamment de la technologie des RCSFs.
Cette couche a aussi pour rôle d’identifier le réseau et les capteurs cibles des requêtes des clients. La couche inférieure est responsable de traduire la requête générique envoyée par la couche de communication en requêtes natives compréhensibles par le RCSF correspondant. Cette couche est étroitement liée à la partie matérielle du RCSF et son implémentation varie suivant le protocole de communication et l’encodage des données du RCSF.
11
Figure 1-2 Couche d’abstraction de capteur Tirée de Gigan et Atkinson (2007)
1.2.2.2 Modélisation du contexte
Après l’obtention du contexte, il est indispensable de formater et représenter ce contexte le plus efficacement possible. La modélisation joue un rôle important dans les systèmes SaC, car une bonne modélisation permettra d’améliorer l’efficacité des traitements, des raisonnements, du stockage et de l’échange des données contextuelles. Plusieurs sujets de recherche se sont intéressés à l’aspect modélisation. Nous citerons d’abord les exigences qui doivent être prises en considération lors de la modélisation du contexte puis présenterons les différentes approches de modélisation qui existent.
Exigences
• La rapidité : certains systèmes SaC sont temps réel et donc il est nécessaire dans ce cas que l’approche de modélisation permette la récupération des données requises le plus rapidement possible;
12
• La gestion des dépendances : le modèle doit prendre en considération les différentes relations qui existent entre les contextes. Un changement dans la valeur d’un contexte peut affecter un autre ou plusieurs contextes;
• Support du raisonnement : le modèle choisi doit donner l’opportunité au client d’effectuer plus de traitements sur le contexte collecté pour pouvoir l’exploiter au mieux;
• Formalisme : le formalisme permet de décrire les informations de manière précise et permet de supprimer les ambiguïtés qui peuvent être générées lors de l’échange des informations contextuelles entre les différentes parties prenantes;
• Interopérabilité : c’est la capacité du modèle à pouvoir communiquer et interagir avec d’autres systèmes pour échanger des données;
• Support de la qualité : le modèle doit prendre en considération, en dehors des valeurs de captures, des métriques de la qualité du contexte.
Approches
• Les modèles de type clé-valeur : ces modèles consistent à associer à chaque classe de contexte (la clé) les mesures acquises des capteurs (la valeur). Cette méthode de modélisation est simpliste, mais s’avère très performante et simple à implémenter. Elle est très pratique pour les systèmes simples et non complexes;
• Les modèles basés sur des profils XML;
• Les modèles graphiques qui sont des modèles basés sur des organigrammes. C’est-à-dire que l’on va essayer de représenter de manière graphique les données contextuelles. On note dans ce sens le CML (context modeling language);
• Les modèles basés sur la logique qui sont des modèles qui représentent le contexte sous forme de règles. Ce sont des modèles caractérisés par leur haut degré de formalité et leur capacité à effectuer du raisonnement;
• Les modèles basés sur les ontologies : Ce sont des modèles très formels et très descriptifs et offrent la possibilité de raisonner et échanger le contexte. Cependant,
13
ces modèles sont complexes et très couteux et consomment beaucoup des ressources de traitement;
• Les modèles hybrides : Ce sont des modèles qui incorporent au moins deux des approches citées avant. Le but de ce mélange est d’essayer de bénéficier des avantages qu’offrent les différentes approches de modélisation.
1.2.2.3 Autres fonctionnalités
Le raisonnement du contexte est une autre fonctionnalité intéressante et qui doit être prise en considération. Le raisonnement consiste à traiter les données et les rendre plus utiles. On distingue deux types de raisonnement. Un raisonnement déductif qui va permettre de générer et d’inférer de nouvelles connaissances à partir d’informations contextuelles. Le deuxième type raisonne sur l’incertitude du contexte et a pour finalité d’améliorer la qualité du contexte. La logique floue, la logique probabilistique, les réseaux bayésiens, les modèles cachés de Markov sont des approches adoptées pour ce type de raisonnement.
L’échange du contexte est une autre fonctionnalité importante. Elle représente la capacité du système à interagir avec d’autres systèmes SaC. L’échange du contexte est un moyen efficace pour augmenter la quantité des informations contextuelles. Un système SaC ouvert vers l’extérieur est plus puissant et plus efficace. Cependant, une bonne définition des acteurs, du contenu à échanger et des protocoles utilisés lors des échanges est cruciale pour éviter d’obtenir des incohérences et des effets inverses.
Le stockage des données contextuelles est important. La quantité et la qualité du contexte sont un actif précieux qu’il faut gérer intelligemment. Le stockage du contexte doit être optimal en termes d’efficacité et la manière avec laquelle s’effectuera le stockage dépendra étroitement de la modélisation du contexte. Le stockage des données devra donc permettre le stockage et la récupération efficace des données et la mise à jour des données pour éliminer tout contenu désuet. Pour certaines applications temps réel, il est nécessaire que le stockage des données permette la récupération rapide des données requises.
14
Certains systèmes SaC peuvent exiger des fonctionnalités spécifiques par exemple un support de la sécurité dans le sens où le système possède des données jugées critiques et qu’il veut les protéger. Dans ce cas le système doit assurer les trois propriétés de base de la sécurité : la confidentialité, l’intégrité et la disponibilité des données. Assurer une bonne qualité peut s’avérer nécessaire dans certains scénarios. La fonctionnalité de qualité devra alors être présente et couvrira la qualité du contexte et la qualité de service.
D’autres fonctionnalités qui ne sont pas spécifiques à la nature des RCSFs peuvent aussi prendre part d’un système SaC par exemple une fonctionnalité qui prédit de futurs contextes à partir de données historiques, une fonctionnalité qui permet la visualisation des données ou une fonctionnalité d’analyse des données.
1.3 Le Cloud computing
Le Cloud Computing (CC) est un modèle qui permet un accès pratique, omniprésent et sur demande à un ensemble de ressources informatiques configurables (réseaux, serveurs, stockage, applications et services). Ces ressources peuvent être rapidement provisionnées et libérées avec un effort minime de gestion et d’interaction avec les fournisseurs de services. Le modèle du Nuage est composé de cinq caractéristiques essentielles, trois modèles de service, et quatre modèles de déploiement.
1.3.1 Les caractéristiques du Nuage
Les principales caractéristiques du Nuage sont :
• Libre-service à la demande : Un consommateur peut être provisionné par des capacités informatiques, telles que le temps de serveur et de stockage en réseau, au besoin automatiquement sans nécessiter une interaction humaine avec chaque fournisseur de services;
15
• L’accès à un réseau large : Les capacités informatiques sont disponibles sur le réseau et accessibles via mécanismes normalisés qui favorisent l’utilisation par les plateformes client hétérogènes (par exemple, téléphones mobiles, tablettes, ordinateurs portables et stations de travail);
• Mise en commun des ressources : Les ressources informatiques (ex. ressources de stockage, de traitement, de mémoire et de bande passante réseau) du fournisseur sont regroupées pour desservir plusieurs consommateurs en utilisant un modèle multilocataire, avec différentes ressources physiques et virtuelles dynamiquement assignée et réassignée selon la demande des consommateurs. Le client n’a généralement pas de contrôle ou de connaissances sur l’emplacement exact des ressources fournies, mais peut être en mesure de préciser l’emplacement à un niveau plus élevé d’abstraction (par exemple, pays, état, ou datacenter);
• Élasticité rapide : Les capacités peuvent être élastiquement provisionnées et libérées, dans certains cas automatiquement, dépendamment de la demande. Du point de vue du consommateur, les capacités disponibles pour provisionner souvent semblent être illimitées et peuvent être appropriées en tout moment;
• Service mesuré : Les systèmes du Nuage contrôlent automatiquement et optimisent l’utilisation des ressources en tirant parti de la capacité de mesure à un certain niveau d’abstraction approprié pour le type de service (par exemple, stockage, le traitement, la bande passante, et les comptes d’utilisateurs actifs). L’utilisation des ressources peut être surveillée, contrôlée et rapportée en assurant la transparence à la fois pour le fournisseur et consommateur du service utilisé.
1.3.2 Les services du Nuage
16
Figure 1-3 Architecture du Nuage. Tirée de Randy Bias (2009)
• Software as a Service (SaaS). Le service prévu pour le consommateur est d’utiliser les applications du fournisseur exécutées sur une infrastructure de Cloud. Les applications sont accessibles à partir de divers dispositifs de clients à travers soit une interface client léger, comme un navigateur Web ou une interface de programme. Le consommateur ne gère ni contrôle l’infrastructure Cloud sous-jacente, y compris le réseau, les serveurs, les systèmes d’exploitation, le stockage, ou même les capacités d’application individuelles;
• Platform as a Service (PaaS). Le service prévu pour le consommateur est de déployer sur le nuage les infrastructures consommateur créées ou les applications créées à l’aide des langages de programmation, les bibliothèques, les services acquis, et des outils supportés par le fournisseur. Le consommateur n’a pas à gérer ou à contrôler l’infrastructure infonuagique sous-jacente, y compris le réseau, les serveurs, les systèmes d’exploitation, ou le stockage, mais il a le contrôle sur les applications déployées et, éventuellement, les paramètres de configuration de l’environnement d’application d’hébergement;
• Infrastructure as a Service (IaaS). Le service prévu pour le consommateur est le provisionnement des ressources de traitement, de stockage, de réseaux et autres ressources informatiques fondamentales où le consommateur est en mesure de déployer et d’exécuter un logiciel arbitraire, qui peut inclure les systèmes d’exploitation et les applications. Le consommateur ne gère ni contrôle le Nuage
17
sous-jacent, mais a le contrôle sur les systèmes d’exploitation, le stockage et les applications déployées; et le contrôle éventuellement limité de certaines composantes du réseau (par exemple, pare-feu).
1.3.3 Les modèles de déploiement du Nuage
Il existe quatre principaux modèles de déploiement de Clouds :
• Le nuage privé. L’infrastructure infonuagique est provisionnée pour une utilisation exclusive par une seule organisation comprenant plusieurs consommateurs (par exemple, les unités d’affaires). Elle peut être détenue, gérée, et exploitée par l’organisation, un tiers, ou une combinaison d’entre eux;
• Le nuage communautaire. L’infrastructure infonuagique est provisionnée pour une utilisation exclusive par une particulière communauté de consommateurs de différentes organisations qui ont des préoccupations communes (par exemple, une mission, des exigences de sécurité, des politiques et des considérations de conformité). Elle peut être détenue, gérée et exploitée par un ou plusieurs des organismes de la communauté, une tierce partie, ou une combinaison d’entre eux, et elle peut exister sur ou en dehors des locaux;
• Le nuage public. L’infrastructure infonuagique est provisionnée pour une utilisation ouverte par le grand public. Elle est détenue, gérée et exploitée par une entreprise, ou une organisation universitaire, gouvernementale ou une combinaison d’entre eux. Elle existe dans les locaux du fournisseur du Nuage;
• Le nuage hybride. L’infrastructure infonuagique est une composition de deux ou plusieurs nuages d’infrastructures distinctes (privé, communautaire ou public) qui restent des entités uniques, mais sont liées ensemble par une technologie normalisée ou propriétaire qui permet aux données et applications la portabilité.
18
1.4 Les plateformes de gestion de contexte
Plusieurs travaux ont été réalisés et qui avaient pour but de fournir des plateformes de gestion de contexte dans le nuage. L’article de Hyun Jung, Moon et Soo (2012) présente un Framework qui fournit des fonctionnalités primaires de gestion de contexte dans le nuage. En particulier, des fonctionnalités de raisonnement et de visualisation du contexte collecté. L’architecture est composée en deux parties : une partie qui sera installée au niveau du client qui se chargera de la collecte et la transmission des données contextuelles dans le Nuage et une partie au niveau du Nuage qui se chargera réceptionner les contextes, les stocker et enfin fournir les fonctionnalités aux clients à partir du stock de contexte. Le principal défaut de cette approche est qu’elle est monolithique. En d’autres termes, on ne va pas allouer à chaque requête du client une instance qui se chargera de traiter sa requête. C’est le serveur central qui se chargera de traiter toutes les requêtes des clients. Cette approche n’emploie pas la réutilisabilité des composants qui est un des grands avantages du Nuage. Par contraste à cette approche, Chihani, Bertin et Crespi (2012) proposent une architecture pour la gestion de contexte qui se focalise principalement sur le raisonnement du contexte qui le fournit comme service (reasoning as service). L’architecture se base sur le fait qu’il existe plusieurs fournisseurs qui peuvent fournir des moteurs de raisonnement et que la plateforme se chargera à partir de la requête de l’utilisateur de solliciter le fournisseur le plus approprié et créer une instance qui se chargera de raisonner sur le contexte collecté. Ce que l’on peut reprocher à cette plateforme est le fait que les travaux se sont focalisés sur la fonctionnalité du raisonnement du contexte et ont négligé les autres fonctionnalités qui sont elles aussi primordiales.
Les travaux de Hyung Jung et Soo Dong (2010) présentent un Framework qui permet l’adaptation dynamique des services. Le Framework capture le contexte et l’analyse pour déterminer l’action à effectuer puis réalise et adapte le service. Le Framework se base sur un « arbre d’adaptation » pour déterminer à partir du contexte collecte le type d’adaptation de service à réaliser.
19
Le travail de Babidi et Taleb (2011) propose une plateforme de gestion de contexte basée sur le courtier. Le courtier dans ce cas sert d’intermédiaire entre les consommateurs de contextes qui sont des Web services SaC et les fournisseurs de contextes. Le courtier a pour objectif de détacher les consommateurs des fournisseurs de contextes. Il permet aux fournisseurs de publier leur contexte et aux abonnés de s’abonner aux contextes désirés.
Belqasmi et al (2012) présente une plateforme de gestion d’application IVR dans le Nuage. La plateforme permet aux fournisseurs d’applications IVR la possibilité de créer et composer leurs services à partir de modules fournis appelés ressources physiques (substrates). La plateforme fournit des interfaces graphiques et des APIs qui permettent au client de créer et composer son service. La plateforme s’occupe de gérer la requête et instancier les différentes ressources physiques nécessaires pour réaliser la requête du client. Elle permet aussi de gérer, opérer et exécuter les différentes ressources physiques instanciées. L’avantage de cette solution est que l’on profite des avantages offerts par le Nuage.
1.5 Conclusion
Pour résumer, les réseaux de capteurs sont des réseaux vastes et offrent un grand nombre de données. Par ailleurs, les systèmes CA restent encore monolithiques et n’utilisent qu’une quantité limitée d’information. Malgré les efforts de recherche effectués, il n’existe aucun système CA distribué qui utilise la richesse des données des capteurs sans fil.
CHAPITRE 2
ARCHITECTURE PROPOSÉE 2.1 Scénarios motivants
Pour illustrer les services que nous pouvons offrir avec des systèmes CA en utilisant des capteurs, nous avons choisi dans notre projet le magasinage intelligent (Smart shopping). Longues files d’attente, produits en rupture de stock, location inconnue de certains produits, des rabais ratés sont des facteurs parmi d’autres qui rendent l’expérience de magasinage un peu énervante et plutôt un fardeau. Mais qu’en est-il d’une nouvelle méthode de magasinage? Une nouvelle méthode qui rendra l’expérience de magasinage plus intéressante et dans laquelle les clients prennent plus de plaisir. On présente dans ce qui suit un scénario de magasinage intelligent en utilisant les RCSF (réseaux de capteurs sans fil) et les systèmes CA.
Définition des différents acteurs (utilisateurs finaux)
Client : c’est le consommateur des produits. Il est là pour profiter au maximum de son
expérience de magasinage. L’application du magasinage intelligent doit anticiper avec le plus de précision possible les actions de l’utilisateur. Les détails de la manière dont le client peut utiliser cette application sont expliqués après la définition des différents acteurs.
Employé du magasin : il peut interagir avec l’application et bénéficier de plusieurs services
comme :
• Des informations à propos des produits, leurs localisations, les quantités de stock exposées aux clients, et les quantités de stock dans l’inventaire. L’application peut aider et assister les clients en recherche d’aide ou de conseil;
22
• Des mises à jour d’informations reliées aux stocks des produits comme le prix ou la quantité disponible;
• Des offres pour des rabais du vendeur aux consommateurs.
Gestionnaire ou le superviseur du magasin : il peut utiliser l’application pour visualiser et
analyser les données du magasin. Par exemple, l’application peut lui fournir des informations de son stock de provisions, des articles les plus populaires, des périodes du jour où le magasin vend le plus, etc. L’application fournit aux gestionnaires des informations utiles et des rétroactions par rapport à l’expérience de magasinage des clients. Ainsi cela permet aux gestionnaires de prendre des décisions efficaces et stratégiques par rapport à leur politique de réapprovisionnement de stock et les choix des produits à étaler.
Figure 2-1 Les acteurs du magasinage intelligent
Scénarios typiques
Le comportement du consommateur varie en fonction de la nature du magasinage. On peut diviser ce comportement en deux catégories : magasinage actif et magasinage passif.
23
En mode passif, le système construit un profil du consommateur et envoie des notifications et des suggestions au client à propos d’articles, de rabais ou bien d’évènements qui pourraient l’intéresser.
En mode actif, le client montre un intérêt pour le magasinage en utilisant l’application intelligente ou bien en visitant directement le magasin, dans ce cas, le système se comportera dépendamment de la nature du magasinage. Nous avons sélectionné deux activités de magasinage et nous essayons de montrer quels sont les différents services que l’application peut fournir.
Magasinage de l’épicerie : Une famille modèle composée d’un père, une mère et deux enfants va partir au supermarché pour effectuer leur magasinage hebdomadaire habituel. Une fois sur place, l’application identifie les quatre personnes et les associe comme étant un groupe. Lorsque la mère a téléchargé gratuitement l’application, elle s’est inscrite et a configuré son profil et celui des membres de sa famille. Puisque la mère est le créateur du groupe, elle est désignée comme leader. Les enfants resteront à l’aire de jeu offerte par le magasin tandis que les parents vont s’occuper du magasinage. Avant leur arrivée, la mère avait déjà préparé une liste d’épicerie. L’application se charge de transférer automatiquement cette liste vers « le chariot intelligent ». Le chariot crée un plan du supermarché et montre la localisation des produits sélectionnés de la liste et le chemin optimal pour les atteindre. L’application peut aussi proposer les rabais du supermarché et les produits qui pourraient intéresser la famille en se basant sur le profil de chacun des membres. La mère peut effectuer son magasinage tout en ayant l’esprit tranquille puisque l’application offre la localisation exacte de chaque membre du groupe à tout moment à l’aide des capteurs des cellulaires des membres du groupe. Le père quant à lui, n’est pas en charge de la liste d’épicerie, mais il est plutôt intéressé par un complément alimentaire spécifique. Il demande alors à l’application de lui fournir plus d’informations à propos de l’article. Ne se contentant pas du produit, il demande en plus un régime basé sur ce complément alimentaire qui conviendrait à sa condition médicale et qui ne contient pas des aliments auxquels il est allergique, ce que l’application est en mesure de lui fournir en consultant son profil. Après un certain temps,
24
l’application envoie un message de notification qui informe la mère qu’ils ont atteint la limite des dépenses, car la famille a fixé un seuil de dépenses dans leurs préférences. À la caisse, le chariot affiche la somme des articles scannés automatiquement lors du magasinage et demande une confirmation de paiement. Puisqu’ils sont des clients fidèles, les membres de la famille bénéficient d’un rabais personnel. Le compte est bon; la transaction est effectuée. Entre temps, l’application envoie un message de notification aux enfants leur disant que le temps de jeu est terminé et qu’il est temps de rentrer à la maison.
Magasinage de vêtements : l’application peut fournir un catalogue contenant une sélection de vêtements qui convient aux préférences de l’utilisateur. Le catalogue peut être personnalisé en fonction des critères du client : prix, tendances de mode, rabais, marque, matière de fabrication, etc. Lorsque le client entre dans un magasin, il peut se connecter à l’application de son propre appareil mobile ou bien de l’appareil du magasin. L’application va fournir les fonctionnalités citées ci-dessus tout en l’adaptant aux spécifications de chaque magasin. Elle peut aussi fournir un « outil d’essai virtuel » qui permet aux clients d’essayer virtuellement les vêtements exposés dans le magasin. C’est une méthode simple, rapide et non encombrante pour essayer des vêtements. L’application permet aussi de montrer la localisation des articles sélectionnés. Elle peut aussi fournir un « outil de personnalisation de vêtements » qui permet aux clients de concevoir leurs propres vêtements basés sur des modèles ou bien de leur propre création. La commande est soumise et une réponse est envoyée au client contenant les détails de sa commande : faisabilité, prix, temps pour la production, estimation du temps de livraison, etc.
Magasinage de mobilier : le client peut interagir avec l’application et utiliser ces fonctionnalités :
• Conseiller de décor : l’application peut utiliser les préférences de l’utilisateur pour fournir des conseils sur le décor intérieur de la maison;
• Simulateur de maison : l’application peut créer une réplique virtuelle de la maison du client (en utilisant des capteurs installés à la maison). Le client peut alors naviguer à
25
travers les produits et simuler comment les différents meubles peuvent être disposés dans les pièces de la maison et voir en général à quoi ressemblera sa maison de l’intérieur. Ceci permet d’avoir une vue plus réaliste et plus claire des articles à acheter et permet d’éviter certains problèmes comme les dimensions des produits, le style et la compatibilité té avec le décor existant;
• Assistant d’assemblage : un guide interactif peut assister le client lors la phase d’assemblage du meuble acheté. Le client peut utiliser par exemple la caméra du téléphone au cours de son assemblage pour valider avec le guide les bonnes pièces à utiliser et l’allure du meuble durant son montage;
• Livraison personnalisée : le magasin peut utiliser les informations contextuelles du client (emploi du temps/agenda) pour programmer le temps de livraison optimal et convenable pour le client (ex. quand le client est à la maison).
2.2 Présentation des substrates reliés aux systèmes CA
Un substrate est un bloc logiciel qui remplit une fonctionnalité déterminée d’un système CA. Pour avoir un bon système CA, il est nécessaire et requis que certaines fonctionnalités soient présentes dans ce système. D’autres systèmes peuvent aussi demander certaines fonctionnalités qui restent reliées à la nature du système. C’est dans cette optique que nous avons divisé les substrates nécessaires pour créer un système CA en deux catégories. Des substrates primaires qui regroupent substrates nécessaires et obligatoires pour faire fonctionner un système CA. Pour qu’un système soit CA, tous ces substrates doivent être implémentés. Ce sont des fonctionnalités de base. Les substrates secondaires, par contre, sont des fonctionnalités qui peuvent être ajoutées aux substrates primaires pour servir un but précis qui dépend de la nature du système visé. Ce sont donc des fonctionnalités complémentaires. Dans notre étude nous avons recensé au total sept substrates primaires et cinq substrates secondaires. Dans la suite de cette section, nous allons définir et décrire chaque substrate.
26
Les substrates primaires
Suite à notre étude de l’état de l’art sur la sensibilité du contexte dans les réseaux de capteurs sans fil, nous avons recensé au total sept substrates primaires :
• La détection du contexte (Sensing) : consiste à détecter et capturer les valeurs et les données recueillies à partir des nœuds capteurs;
• Agrégation : consiste à combiner données capturées pour avoir des valeurs représentatives des données recueillies de la même nature. Par exemple, on prend la moyenne de toutes les données de température capturées par les différents capteurs durant une durée déterminée;
• Classification & modélisation : consiste à représenter le contexte de manière à pouvoir effectuer un stockage, un raisonnement et un échange efficaces. Deux approches différentes de modélisation influent sur l’efficacité de l’échange des données. Un modèle basé sur XML définit un schéma sur lequel les données doivent se conformer. La validation des données XML est plus simple et efficace que pour un modèle clé-valeur où les données sont textuelles et leur validation se fait manuellement et donc moins efficace. Au niveau du stockage, encore parcourir un format texte est nettement moins performant que de parcourir du XML;
• Validation : consiste à effectuer du prétraitement sur le contexte collecté. Les données collectées par les capteurs ne sont pas toujours exactes. Une température ambiante supérieure à 100 Celcius est surement une valeur fausse. Ce substrate permet d’enlever ces mauvaises valeurs qui compromettent la véracité du contexte;
• Inférence : consiste à inférer un nouveau contexte à partir du contexte collecté. Ce substrate utilisera une combinaison de valeurs de contexte pour générer une information contextuelle de niveau supérieur que l’on ne peut pas avoir directement à partir d’un capteur spécifique. Elle apporte une richesse d’information au niveau du contexte;
27
• Stockage : ce substrate permet de stocker les informations contextuelles efficacement et élimine les données redondantes et désuètes;
• Échange : ce substrate permet d’échanger le contexte avec les d’autres systèmes CA.
Les substrates secondaires
De la même manière, nous avons recensé et gardé à la fin cinq ressources physiques secondaires décrites comme suit :
• Prédiction : consiste à prédire de futures modifications de l’information contextuelle à partir de données historiques afin d’agir suivant ce contexte. Par exemple, la prédiction sur le contexte de la pression sanguine du corps humain peut sauver une vie humaine si on arrive à prédire correctement l’arrivée d’une hypotension;
• Support de la qualité : ce substrate permet de garantir des propriétés de qualité de contexte et de qualité de service;
• Support de la sécurité : ce substrate permet d’assurer la confidentialité et l’intégrité des données jugées critiques;
• Visualisation des données : ce substrate fournit des outils pour visualiser l’information contextuelle;
• Analyse des données : ce substrate fournit des outils pour analyser les données contextuelles.
2.3 La vue globale
D’après l’analyse de l’état de l’art, nous proposons un Framework qui respecte le concept infonuagique. Le nuage offre trois types de services : le logiciel comme service, la plateforme comme service et l’infrastructure comme service. Dans un niveau supérieur, nous trouverons la couche qui fournit les logiciels comme services. Pour les systèmes qui nous intéressent, ce sont des applications CA. La richesse du contexte que l’on peut acquérir des
28
réseaux de capteurs sans fil permet de concevoir une grande variété d’application dans différents domaines.
La couche qui suit est la couche de plateforme dans laquelle le fournisseur de service trouve tout ce dont il a besoin pour créer son application CA. Cette couche fournira des interfaces graphiques et des APIs qui constitueront les points d’accès au fournisseur de service. Cette couche peut aussi fournir des blocs fonctionnels qui entrent dans le développement des systèmes CA, mais ne sont pas spécifiques à ceux-ci. Ce sont des fonctionnalités génériques que l’on peut trouver présentes dans d’autres types de systèmes. Nous citons la fonctionnalité de prédiction, de visualisation des données et d’analyse des données. Le lien commun de ces blocs fonctionnels est qu’ils acceptent comme entrées des données sous format standard Independent du système qui lui fait appel.
Dans la couche inférieure qui est l’infrastructure, on retrouve les différents blocs fonctionnels qui constituent la base d’un système CA. Les blocs fonctionnels retrouvés dans cette couche sont spécifiques et liés à la nature des réseaux de capteurs sans fil. Le principal avantage de cette architecture est la simplicité avec laquelle il devient possible de développer des applications CA. Les développeurs d’applications classiques pourront migrer facilement les applications CA, car l’architecture cache toute la complexité qui se cache derrière la sensibilité au contexte. Mais, en même temps, elle fournit des fonctionnalités avancées pour les développeurs expérimentés dans le domaine de la sensibilité au contexte.
29
Figure 2-2 La vue générale
2.4 Architecture logicielle
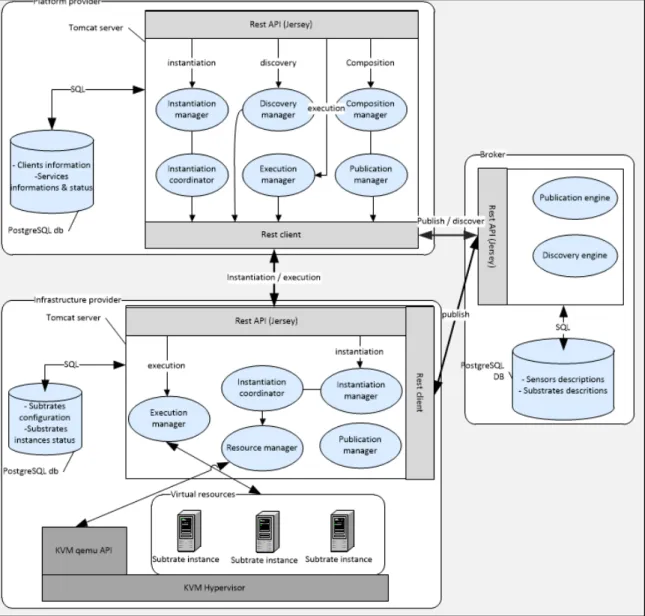
La figure 2-3 illustre l’architecture logicielle globale. Cette architecture est composée de deux couches : plateforme et l’infrastructure ainsi que d’un dépôt de données (Broker).
30
Figure 2-3 Architecture logicielle de la plateforme de gestion de contexte
2.4.1 La couche de plateforme
Cette couche offre aux fournisseurs de services un ensemble d’outils nécessaires (ex, interfaces graphiques, API, etc.) pour développer des services CA. Elle représente une couche d’abstraction entre les applications contextuelles et les infrastructures physiques. La couche de plateforme offre aux fournisseurs de services des substrates et des capteurs. En réalité, les différentes ressources sont seulement exposées par la couche de plateforme. Ce sont en fait les fournisseurs d’infrastructure qui fournissent et gèrent ces ressources.
31
La couche plateforme fournit les blocs fonctionnels clés suivants :
• Interfaces graphiques : elles sont utilisées par les fournisseurs de services. Ces interfaces sont les points de contact entre la plateforme comme service et le fournisseur de service. À travers ces interfaces graphiques, le client (fournisseur de service) peut découvrir les différentes ressources offertes par la plateforme. Il peut aussi, les utiliser pour composer et créer un service. Enfin les interfaces graphiques peuvent être utilisées pour voir le statut de ses services et même pour tester leur bon fonctionnement;
• API : ces librairies sont destinées à chaque fournisseur de service. Elles sont destinées à être consommées et utilisées lors de la phase de développement du service par son fournisseur. Ces APIs doivent utiliser des protocoles standardisés (Interfaces REST dans notre cas);
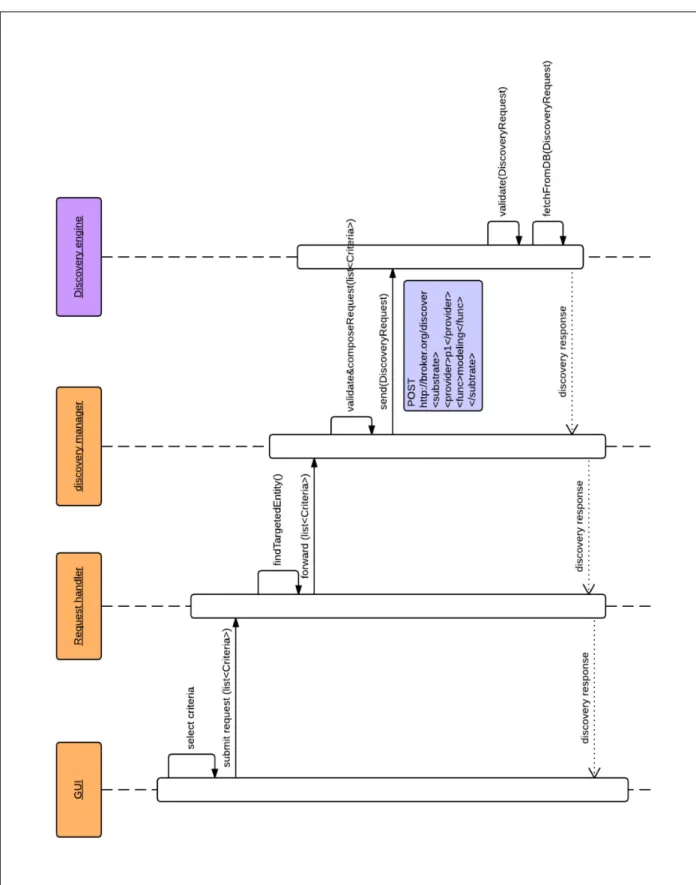
• Gestionnaire de découverte (Discovery manager) : il sert à traiter les différentes requêtes de découvertes qu’il reçoit de la part des fournisseurs de service. Ce gestionnaire valide le format des données de la requête, puis il l’analyse selon les différents critères de découverte et il compose une nouvelle requête destinée au courtier. La réponse du courtier est envoyée alors au fournisseur de service;
• Gestionnaire de composition (Composition manager) : ce gestionnaire permet de traiter les requêtes de composition provenant des clients. Ces requêtes sont envoyées lorsque le client a l’intention de composer un service. Le client sélectionne depuis l’interface graphique un ensemble de substrates et de capteurs et soumet la requête de composition. La principale tâche de ce gestionnaire est de créer un fichier descriptif du service composé nommé le « fichier de composition de service ». Ce fichier contient toutes les informations nécessaires pour déployer un service CA suivant le choix du client;
• Gestionnaire de publication (Publication manager) : lorsque le fournisseur de service décide de publier son service au public ou à un ensemble spécifique d’utilisateurs. Il
32
envoie une requête de publication au gestionnaire de publication. Ce dernier compose une nouvelle requête destinée au courtier pour que ce dernier la publie;
• Le gestionnaire d’instanciation (Instantiation manager) : lorsque le client est satisfait de sa composition de son service. Il valide en envoyant une requête d’instanciation. Cette requête permet de déployer physiquement les ressources sélectionnées. Ce gestionnaire a pour principale fonctionnalité de valider cette requête, d’identifier les différents fournisseurs d’infrastructure qui offrent les ressources dont le service a besoin. Enfin, il envoie ces informations au coordinateur d’instanciation;
• Le coordinateur d’instanciation (Instantiation coordinator) : ce nœud fonctionnel est responsable de gérer les diverses requêtes d’instanciation provenant des différents fournisseurs de services. Il utilise l’information du gestionnaire d’information pour créer différentes requêtes d’instanciation destinée à des fournisseurs d’infrastructure ciblés. Ces requêtes sont mises dans une file d’attente et sont traitées selon leurs priorités. Enfin, le coordinateur garde trace de l’instanciation du service, et dépendamment des réponses reçues des requêtes d’instanciation, il génère un message indiquant le statut générique de la requête et de son déroulement, puis l’envoie au client (fournisseur de service). Si la requête générique d’instanciation s’est bien exécutée, le coordinateur crée au niveau de la base de données un descriptif du service et expose au client les différentes API générées par le déploiement des ressources;
• Le gestionnaire d’exécution (Execution manager) : le gestionnaire d’exécution permet de traiter les requêtes d’exécution de service envoyées par le client. Le but de ces requêtes est de connaitre le statut des services déployés et aussi de tester le bon fonctionnement de ses services. Le gestionnaire d’exécution identifie alors les fournisseurs d’infrastructures qui offrent et qui déploient les ressources et envoie des requêtes d’instanciation à ces fournisseurs.
33
2.4.2 La couche d’infrastructure
Cette couche est responsable de fournir les différentes ressources nécessaires pour créer un service CA. Ainsi, les différents blocs fonctionnels relatifs aux systèmes CA discutés dans le chapitre précédent sont implémentés à ce niveau. L’accès aux données collectées par les capteurs est aussi implémenté au niveau de cette couche. Cette couche assure la gestion efficace des ressources pour assurer la qualité de service aux usagers. Elle offre les blocs fonctionnels suivants :
• APIs : elles sont principalement des librairies de communication qui permettent à cette couche de s’interfacer avec d’autres entités externes (le fournisseur de Plateforme comme service, autres fournisseurs d’infrastructure comme service, dépôt de données, etc.);
• Le gestionnaire d’instanciation (Instantiation manager) : ce gestionnaire traite les requêtes d’instanciation qui proviennent des différents fournisseurs de plateforme. Le rôle principal de ce gestionnaire est d’identifier les différentes ressources à déployer et les grouper sous forme de ressources appartenant au même service, puis envoyer ces informations vers le coordinateur d’instanciation;
• Le coordinateur d’instanciation (Instantiation coordinator) : cette entité priorise et traite les requêtes d’instanciation en se basant sur l’information fournie par le gestionnaire d’instanciation. La deuxième fonctionnalité qu’offre cette entité est l’envoi des demandes d’instanciations des ressources tout en gardant trace de l’état d’instanciation des autres ressources appartenant au même service. Le coordinateur a toujours une vue globale de l’état d’avancement général de l’instanciation d’un service donné;
• Le gestionnaire de ressources (Resource manager) : il est responsable de la gestion des ressources logicielles et physiques. Ce bloc a pour rôle de créer/supprimer les ressources (substrates), les configurer et les connecter entre elles. Le gestionnaire des ressources envoie régulièrement des messages de notifications au coordinateur pour