Exploiting heterogeneous manycores on sequential code
Texte intégral
Figure

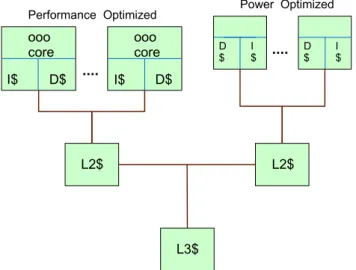

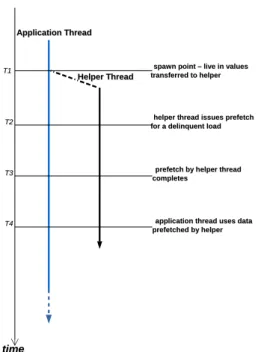

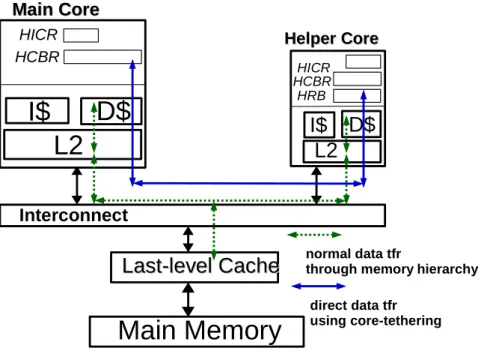



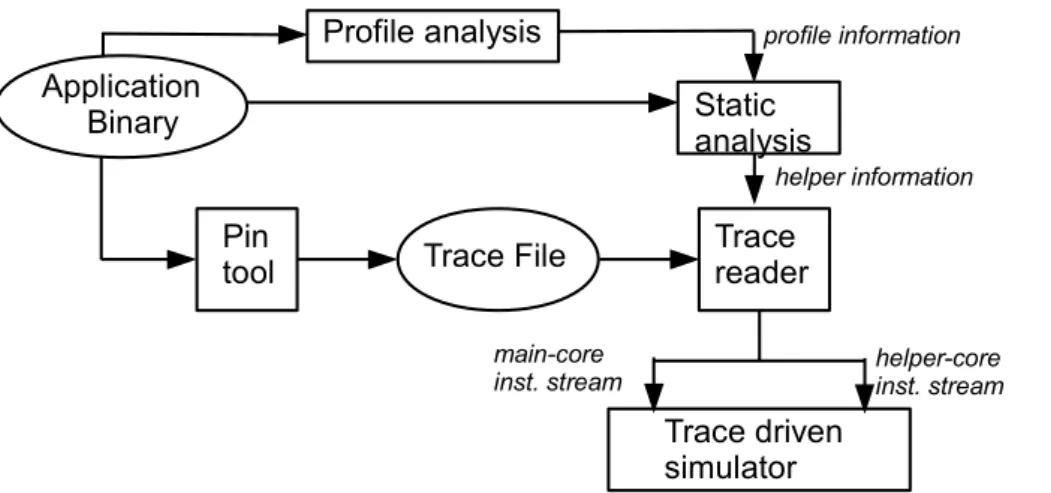
Documents relatifs
Key-words: Feynman–Kac flow, nonnegative selection function, binary selection function, interacting particle system, extinction time, random number of particles, central limit
Compensatory mechanisms in apraxic speech: preliminary acoustic evidence for the interaction between nasality and voicing.. Anna Marczyk 1 , Melissa Redford 2 , Yohann Meynadier 1
Finally, Gene Ontology (GO) analysis revealed an important dichotomy between genes more expressed in DS and Acb that might underlie diversity in the biological functions of DS and
In the language of nonparametric Bayesian statistics (see Remark 2.5 ), Gaussian process priors are conjugate with respect to this sampling model. The following result formalizes
In some applications such as MASH, simulations are too expensive in time and there is no prior knowledge and no model of the environment; therefore Monte-Carlo Tree Search can not
We revisit the compilation of such rules into a single se- quential transducer given by Roche and Schabes (Comput. 1995) and provide a direct construction of the minimal
The basic idea of MMISP (Mining Multidimensional Itemsets Sequential Patterns) consists in transforming the mds-data into a “classical form” (i.e., sequence of itemsets) and
