Towards Multi-Service Traffic Shaping in Two-Tier Enterprise Data Centers
Texte intégral
Figure

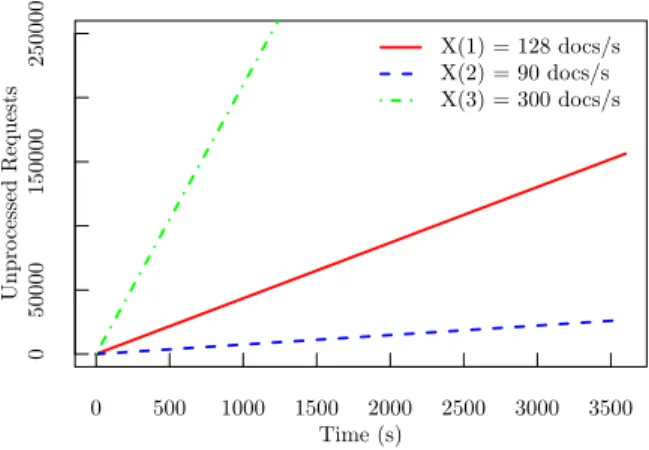
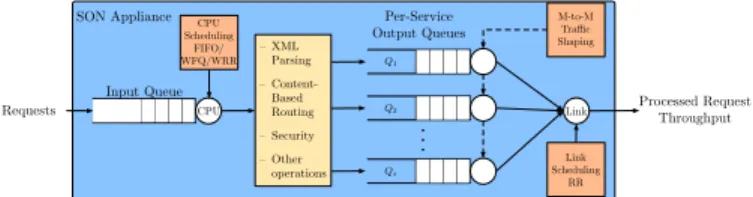
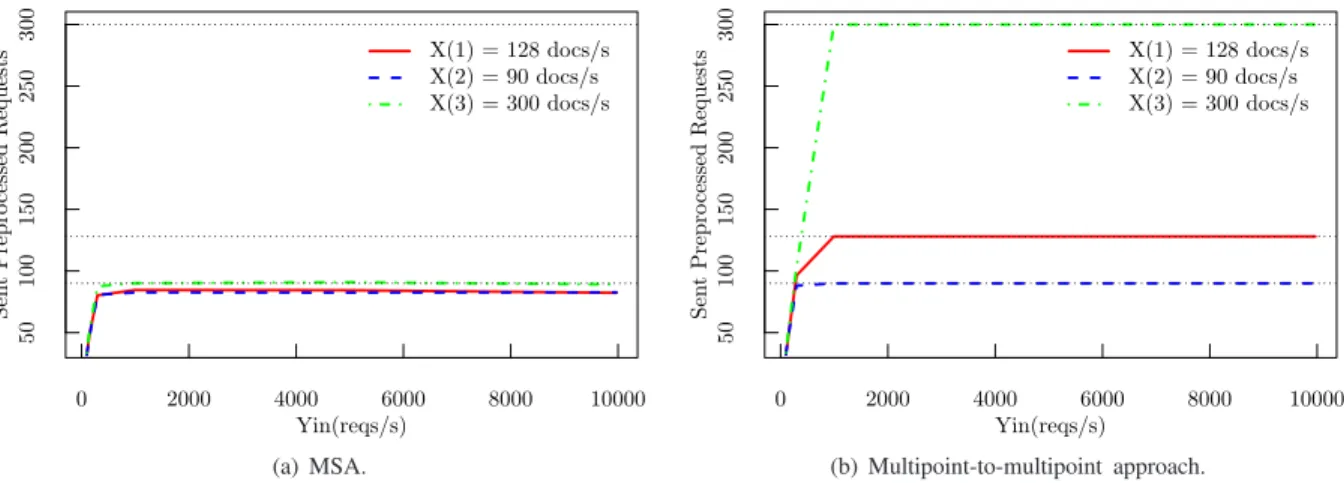
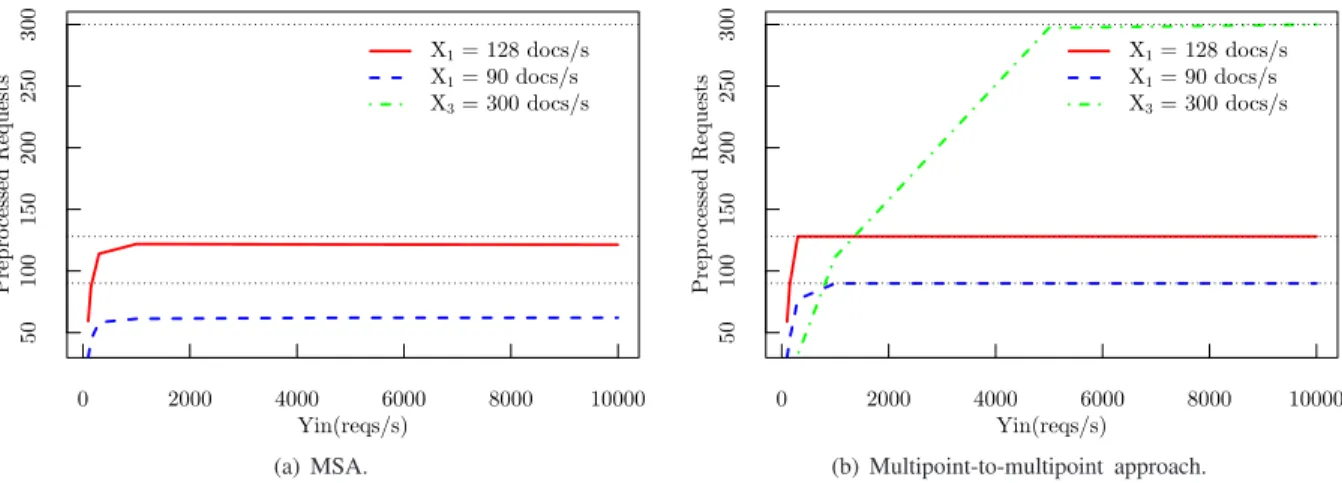
Documents relatifs
1) Centralized model – the macro-cell BS chooses both Ψs and the policies for the players, aiming to maximize � ��. 2) Stackelberg model – there are two stages: at the first
The proposed algorithm, named Double-Distribution Optimization Algorithm (DDOA) uses a simple univariate model to represent the angle distribution p(θ 1 ,. , θ n ), but
These sentences, as they do not present non-lexical nor ambiguous phenomena, can be easily parsed by a “core” grammar (see section 4.1) with very high precision and recall rates
Based on these local observations, femto base stations learn the probability distribution of their transmission strategies (power levels and frequency band) by minimizing their
Using mathemat- ical tools from stochastic geometry, we derive the effect of feedback delay and quantization error on the probability of outage and achievable rate of the
Rate of the primary system for different number of receivers compared to the secondary receiver’s rate (N = 128, L = 32 and bandwidth of 1.42
It is shown that the percentage increase in genetic gain of assortative mating over random mating is greatly increased at low to moderate heritability when BLUP
In figure 5, for large J/kT (and small values of AP/kT-near zero) the radius of gyration becomes constant. As the value of J/kT decreases, the radius decreases slowly, without a
