Safety Analysis and Evaluation of an Air Traffic Control Computing System
12
0
0
Texte intégral
Figure
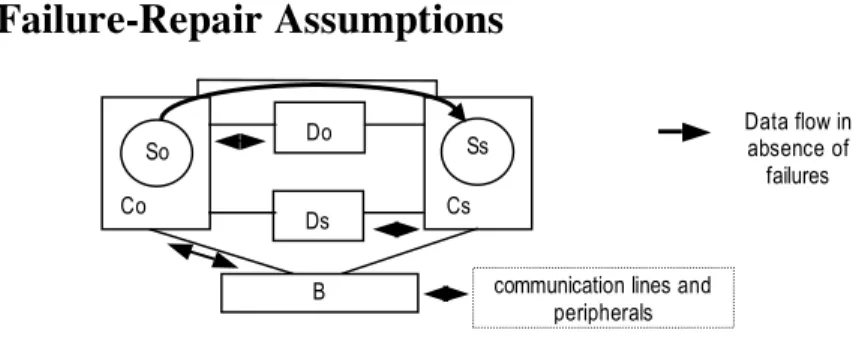
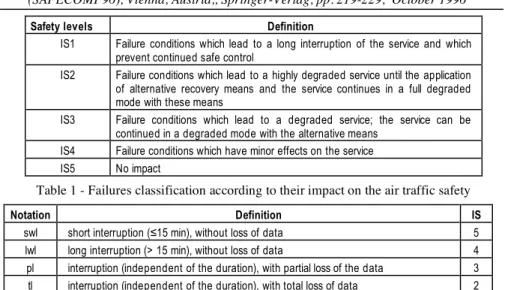
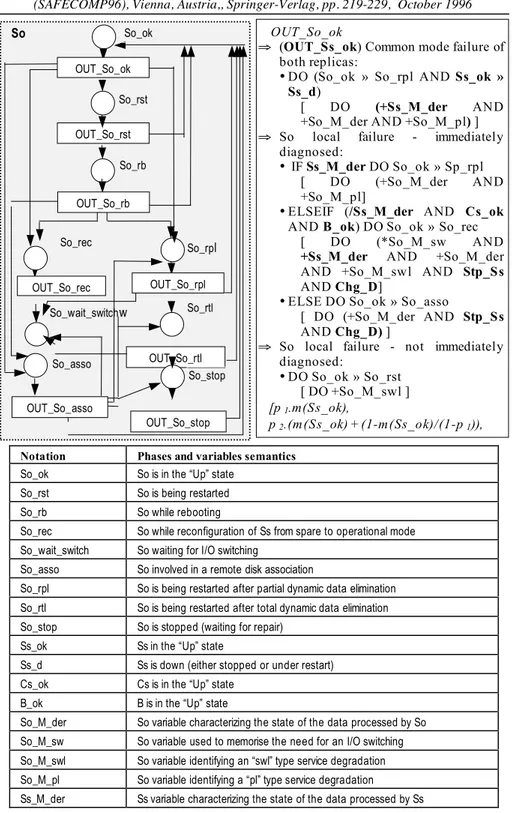
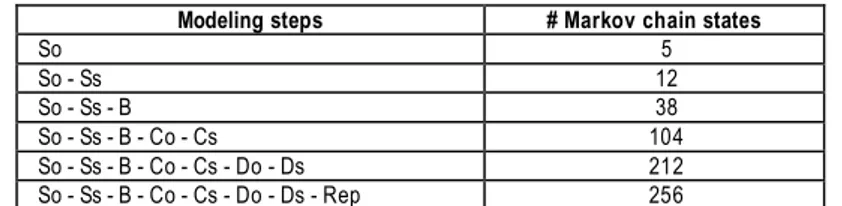
+2
Documents relatifs