Efficient Enumeration for Conjunctive Queries over X-underbar Structures
Texte intégral
Figure
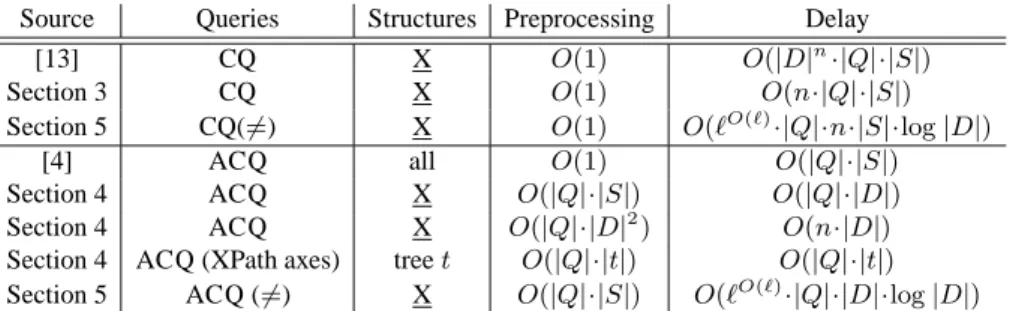
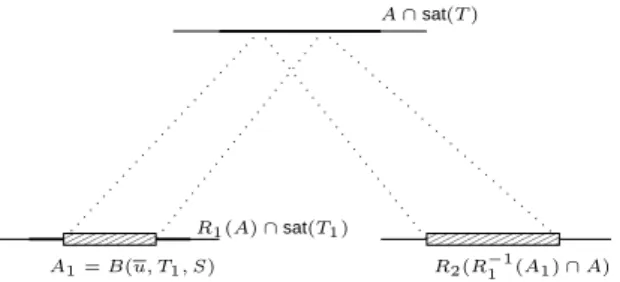
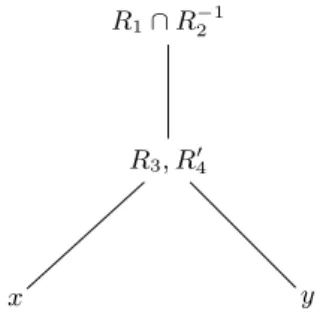

Documents relatifs
In the linear case, CRPQ answering is E XP T IME -complete in combined complexity, PS PACE - complete in combined complexity with bounded predicate arity and NL-complete in data
These results have a important practical impact, since they make it possible to identify those sets of binary guarded existential rules for which it is possible to answer every
Ontology-based data access, temporal conjunctive query language, description logic knowledge base..
However, while for acyclic and bounded hypertreewidth queries we have shown a number of examples of interesting approximations, for queries of bounded treewidth the study had
We then provide a way of “collapsing” such forest quasi-models back into real models that still have a kind of forest shape, called forest model, but which have a possibly infinite
Inference services required for modelling legislation and building legal assessment applications can be feasible using grounded queries resulting in a decidable formalism.. Since
After finding mappings from the subgoals in the query to view, a major part of a rewriting process is spent in performing the cartesian products of a set of large buckets that
The role of canonical models in our decision procedure is roughly speaking the following: for deciding query entailment, we first rewrite a given query into a set of
