Efficient product sampling using hierarchical thresholding
10
0
0
Texte intégral
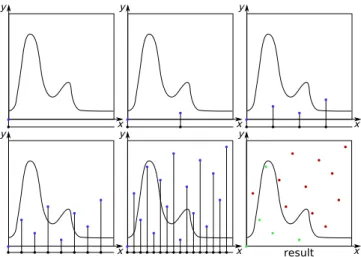
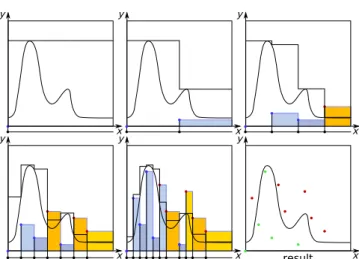
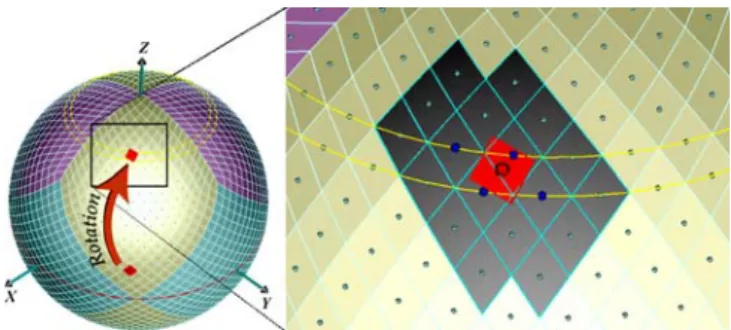
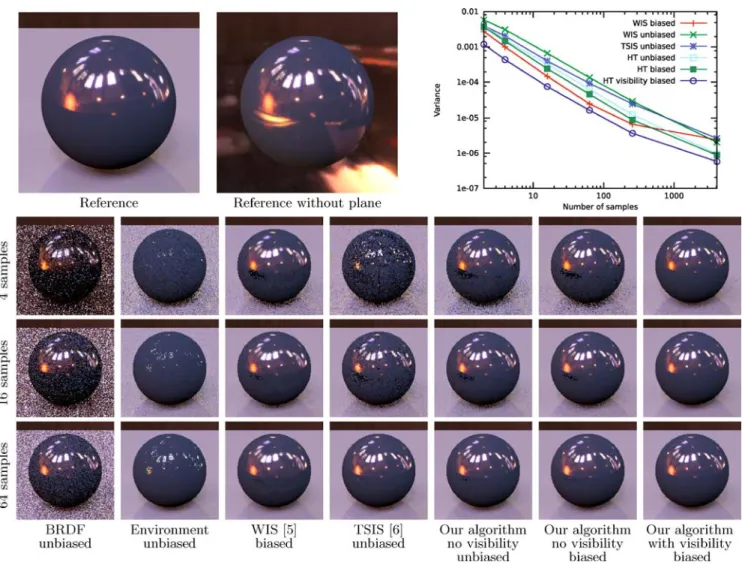
Figure

+3

Documents relatifs