Object-based classification of grasslands from high resolution satellite image time series using Gaussian mean map kernels
Texte intégral
Figure


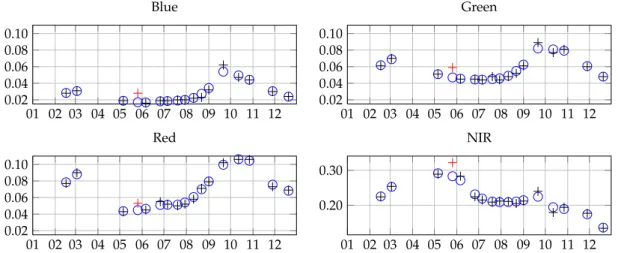







Documents relatifs
Cette opacité narrative qui marque l’écriture textuelle de l’espace, s’inscrit sans détour dans une isotopie de l’écart.. Lorsque le narrateur évoque la ville d’Alger,
Ce chapitre traite encore le chimisme des eaux souterraines, et nous permettra d’expliquer le comportement, l'origine et l’évolution de certains éléments chimiques ainsi que
As expected, the World Bank is undertaking the widest scope activities and projects with significant environmental goals and components, followed by the EBRD, and
But this doesn't mean that these mixed use developments don't increase the likelihood of people living in them being within walking distance of work. Because
Pour déterminer si les effets observés sur la barrière épithéliale intestinale sont spécifiquement dépendants de l’impact de l’acide palmitique, j’ai étudié
In general terms, the goal of the Chestnut Ridge SCS Demonstration Project was to demonstrate how an existing monitoring network, existing air quality models,
Nevertheless, different representation models for satellite images can be defined, i.e., based on complex network models, which may allow to discover new relations between the
a Researcher, CIRAD, UMR TETIS F‐34398, Montpellier, France, b PhD Student, presently at UMR Espace‐Dev, Université de la Réunion,
