Core Extraction and Non-Example Generation:
Debugging and Understanding Logical Models
by
Robert Morrison Seater
Submitted to the Department of Electrical Engineering and Computer
Science
in partial fulfillment of the requirements for the degree of
Masters of Science in Computer Science and Engineering
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
November 2004
@
Massachusetts Institute of Technology 2004. All rights reserved.
A u th or ... ... ...
Department of Electrical Engineering and Computer Science
November 30, 2004
C ertified by ...
.. ...-.
Daniel N. Jackson
Associate Professor
Thesis Supervisor
Accepted by ...
. ... ...
- .-.
.
.
Arthur C. Smith
Chairman, Department Committee on Graduate Students
MASSACHUSETS INSTMi OF TECHNOLOGY
Core Extraction and Non-Example Generation: Debugging
and Understanding Logical Models
by
Robert Morrison Seater
Submitted to the Department of Electrical Engineering and Computer Science on November 30, 2004, in partial fulfillment of the
requirements for the degree of
Masters of Science in Computer Science and Engineering
Abstract
Declarative models, in which conjunction and negation are freely used, are a pow-erful tool for software specification and verification. Unfortunately, tool support for developing and debugging such models is limited. The challenges to developing such tools are twofold: technical information must be extracted from the model, then that information must be presented to the user in way that is both meaningful and manageable. This document introduces two such techniques to help fill the gap.
Non-example generation allows the user to ask for the role of a particular subformula in a
model. A formula's role is explained in terms of how the set of satisfying solutions to the model would change were that subformula removed or altered. Core extraction helps detect and localize unintentional overconstraint, in which real counterexamples are masked by bugs in the model. It leverages recent advances in SAT solvers to identify irrelevant portions of an unsatisfiable model. Experiences are reported from applying these two techniques to a variety of existing models.
Thesis Supervisor: Daniel N. Jackson Title: Associate Professor
Acknowledgments
This research was supported by grant 0086154 (Design Conformant Software) from the ITR program of the National Science Foundation, by grant 6895566 (Safety
Mechanisms for Medical Software) from the ITR program of the National Science
Foundation, and by the High Dependability Computing Program from NASA Ames cooperative agreement NCC-2-1298.
The core extraction portion of this thesis (Chapter 3) is isomorphic to a paper co-authored with Ilya Shlyakhter, along with Manu Sridharan, Daniel Jackson, and Mana Taghdiri [19]. In addition, the author is grateful for the insight and feedback given by his advisor Dr. Daniel Jackson and colleagues Gregory Dennis, Emina Torlak, Derek Rayside, Dr. Robert Miller, and Dr. Michael Ernst.
This work was completed while the author was a member of the Software Design Group (SDG), a research group at the Computer Science and Artificial Intelligence Labratory (CSAIL) at the Massachusetts Institute of Technology (MIT).
Contents
1 Declarative Modeling: Benefits and Drawbacks 21
1.0.1 Benefits of Declarative Modeling ... 22
1.0.2 Under- and Over-constraint . . . . 24
1.0.3 Writing and Analyzing Declarative Models . . . . 26
1.1 The Alloy Language . . . . 27
1.2 Errors: Modeling Bugs vs. System Faults . . . . 27
2 Non-Example Generation: Explaining Subformulae 29 2.1 Motivating Non-Examples . . . . 30
2.1.1 Windows and Rain . . . . 30
2.1.2 Counterfactual Reasoning? . . . . 32
2.1.3 Events vs. Policies . . . . 36
2.1.4 What is the Role of a Formula? . . . . 37
2.2 Formalization and Representation: Conjunction Diagrams . . . 39
2.2.1 Deletion (and Sabotage) Formalized . . . . 39
2.2.2 Conjunction Diagrams . . . . 40
2.2.3 Representing Sabotage . . . . 42
2.2.4 Theorem s . . . . 43
2.3 Propositional Logic Examples . . . . 46
2.3.1 Trivial Examples . . . . 46
2.3.2 CNF Example . . . . 48
2.3.3 Using Expansion to Explore a Model . . . . 50
2.4 Handling Rich Logics . . . . 52
2.4.1 Non-Boolean Values . . . . 53
2.4.2 Defined Names and Other Syntactic Sugars . . . . 54
2.5 Alloy Examples . . . . 57
2.5.1 Ceilings and Floors . . . . 58
2.5.2 Sequence Library . . . . 64
2.5.3 The Firewire Network Protocol . . . . 66
2.6 Expansion and Refinement . . . . 80
2.7 Related Work . . . . 80
2.7.1 Understanding Counterexamples with explain . . . . 80
2.7.2 Mutation Testing . . . . 81
2.7.3 Logic Programming: Prolog . . . . 82
2.7.4 Near Miss Learning . . . . 84
3 Core Extraction: Identifying Overconstraint 87 3.1 Introduction . . . . 88
3.2 A Toy Example . . . . 90
3.3 The Core Extraction Algorithm . . . . 95
3.3.1 Constraint Language . . . . 96 3.3.2 Translation . . . . 96 3.3.3 Mapping Back . . . . 98 3.3.4 Complications . . . . 99 3.4 Experience . . . . 99 3.4.1 Common Mistakes . . . . 100
3.4.2 Locating Known Overconstraints . . . . 102
3.4.3 Blunders Discovered . . . . 105
3.4.4 Performance . . . . 106
3.5 Related work . . . . 107
3.6 Conclusions . . . . 108
B Proofs 121
B.1 Deletion and Sabotage are Sufficient to Compute Correctness . 121
B.2 Disjoint Entries . . . . 123
List of Figures
2-1 An Alloy model of the relation between the weather, the status of your
bedroom window, and whether or not you get wet. . . . . 31
2-2 There are only 6 pairs of entries in a conjunction diagram which are not always disjoint. . . . . 45
2-3 An Alloy model written by Daniel Jackson about Paul Simon's song "One Man's Ceiling Is Another Man's Floor". . . . . 58
2-4 A counterexample to the claim that one man's floor is another man's ceiling . . . . 59
2-5 The role of the PaulSimon constraint . . . . 60
2-6 A counterexample to the claim that the Geometry constraint is suffi-cient to force each man's floor to be some man's ceiling . . . . 61
2-7 The role of the Geometry constraint . . . . 62
2-8 The role of the presence of the NoSharing constraint . . . . 63
2-9 A simplified version of Alloy's sequence module . . . . 65
2-10 The role of part of the add predicate in the sequence module. An arc labeled next [seqO] from node widget1 to node widgetO means that, in the sequence [seqO], widget1 immediately preceeds widgetO. . . . 67
2-11 In state SO, the system is initialized and the nodes are waiting. Each link has a message queue which is initially empty. Node0 has only one incoming link, and thus it has only one incoming link which has not been classified as a parentLink. In state Si, Node0 becomes active and sends a request to Node1, declaring its willingness to be a child. . 71
2-12 In state S2, Node2 acknowledges NodeO's request, indicating that Node2 is willing to be NodeO's parent. NodeO thus declares that its outgoing link is a parentLink, making it a leaf in the tree being constructed. In state S3, Node2 becomes active and notices that it how has only one outgoing link which is not marked as being a parentLink. It thus sends a request to Nodel, indicating its willingness to be a parent. . . 72
2-13 In state S4, Nodel acknowledges Node2's request, indicating its
willing-ness to be a child. Node2 sees that only one of its incoming links is not a parentLink, so it sends a request to Nodel that the other incoming link be made a parentLink. In state S5, Node1 activates and sees that it can only be a leaf node. . . . . 73
2-14 In state S6, all of Node2's incoming links are parentLinks, and those choices have been validated by its neighbors. Node2 thus declares itself to be the root, and the algorithm terminates . . . . . 74
2-15 One state from a trace in PCD from the entire constraint describing
of the stutter operation . . . . 75 2-16 PCD from the conjunction diagram for the role of the latter half of
the constraint s' .op = Stutter => SameState (s, s') . . . . 76 2-17 The formula n in s .active in the specification for the Elect operator
is crucial to disallowing the case where an inactive node is elected as the root. Shown, are states S5 and S6 (the final two states) of one such trace. This trace would appear in the PCD entry of the conjunction diagram . . . . 79
3-1 A toy Alloy model describing the behavior of a web cache . . . . 91
3-2 The corrected version of the web cache Alloy model, taking into account the information provided by core extraction . . . . 94
3-3 A Roadmap to Core Extraction. (1) A model is created in any
con-straint language which is reducible to SAT in a structure preserving fashion. (2) During translation to CNF, each clause generated is anno-tated with the AST node from which the clause was produced. (3) A
SAT solver (used as a black box) determines that the model is
unsat-isfiable and extracts an unsatunsat-isfiable core (a subset of the CNF clauses which is also unsatisfiable). (4) The core is mapped back to the orig-inal model by marking (as "relevant") any part of the AST indicated
by the annotation of any clause in the CNF core. The analysis is now
complete. The remaining steps concern guarantees made to the user about what the markings on the AST mean; they are not actually ex-ecuted during normal use of the tool. (5) The user is guaranteed that changing the unmarked (non-relevant) portions of the AST will leave the model unsatisfiable. (6) Specifically, the CNF corresponding to
the altered AST will be a superset of the unsatisfiable core previously extracted, and thus will itself be unsatisfiable. . . . . 109
3-4 Translation of AST to CNF, and mapping back of unsatisfiable core. The AST is for the (trivially unsatisfiable) Alloy formula of the form "(some p) && (no p) && ...". To each node, a sequence of Boolean variables (bi through b6) is allocated to represent the node's value. From each inner node, translation produces a set of clauses relating the node's Boolean variables to its childrens' Boolean variables. The highlighted clauses form an unsatisfiable core, which is mapped back to the highlighted AST nodes. . . . . 110
List of Tables
2.1 A generic conjunction diagram with column formulae Coll and Col2
2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.10 2.11 2.12
and row formulae Row1 and Row2 . . . . . . . . . . .
The generic conjunction diagram for deletion . . . . . The conjunction diagram for sabotage . . . .
The conjunction diagram for deletion and sabotage .
The role of the final clause of a CNF formula . . . . .
The role of B in A V B . . . . The role of B in A A B . . . .
Our intuition for the role of a CNF clause . . . .
Our intuition for the role of a term in a CNF clause . The role of a redundant CNF clause . . . . The role of a term in a redundant CNF clause . . . .
The role of -,Wif eLate in the dinner example . . . .
41 . . . . . 41 . . . . . 43 . . . . . 43 . . . . . 44 . . . . . 46 . . . . . 47 . . . . . 48 . . . . . 49 . . . . . 49 . . . . . 50 . . . . . 51
Introduction
Suppose you are a software developer and have formulated an important aspect of your program as a logical model. Now you want to make sure that your model is saying what you think it is saying and that you are correctly interpreting the results it gives you.
Consider this excerpt from an Alloy model which is discussed in depth later on.
pred Geometry O{no m: Man I m.floor = m.ceiling}
What role does this constraint play in the model? Is it necessary? What would have happened if it had been written it incorrectly? Is it allowing solutions which ought to be eliminated? Is it eliminating solutions that ought to be allowed?
The answers to these questions could probably be deduced through careful reason-ing but (a) it would be a lot of work, and (b) there would always remain a lreason-ingerreason-ing doubt that you missed something. Such concerns beg for automated tool support. We present two such tools to help the user answer these questions.
Explaining Roles
When looking at a logical model, it is natural to ask what role some particular constraint plays in that model. But what sort of an animal is the role of a subformula? Logicians and philosophers have addressed this issue in a number of ways that involve extending the logic to include special constructs. In Chapter 2, we propose
non-example generation as an appealing, lightweight alternative. This technique explains
were absent or altered. We introduce conjunction diagrams as a notation to present such information.
Determining the effect of deleting a suformula T is not as simple as removing T and re-analyzing the model. Suppose, after removing T, your checker produces a new solution. Was it a solution before you removed T? Are the old solution still solutions? What you really want to know is what new solutions were added and what old solutions have been inhibited. A more sophisticated approach is required, and we introduce non-example generation as one such approach.
Overconstraint
Logical models are susceptible to unintentional overconstraint in which real coun-terexamples are masked by bugs in the model. In Chapter 3, we introduce Core
extraction, a new analysis that mitigates this problem in the presence of a checker
which translated the model to CNF. It exploits a recently developed facility of SAT solvers to deduce an unsatisfiable subset of a CNF which is often much smaller than the clause set as a whole. This unsatisfiable "core" is mapped back into the syntax of the original model, showing the user irrelevant fragments of the model. This in-formation can be a great help in discovering and localizing overconstraint, sometimes pinpointing it immediately. The construction of the mapping between the model and an equivalent CNF is given for a generalized modeling language, along with a proof of the soundness of the claim that the marked portions of the model are irrelevant. Experiences in applying core extraction to a variety of existing models are discussed.
Summary
Chapter 1 provides background and puts the remaining chapters in context. We introduce declarative modeling and discuss its benefits and drawbacks.
Chapter 2 introduces non-example generation, a technique which explains the role of a subformula by computing solutions it is responsible for allowing or disallowing. We begin by motivating our approach as a lightweight alternative to counterfactual
reasoning, formalize it, and introduce conjunction diagrams as a convenient notation. We expand the technique to account for quantifiers and named predicates, then use it to examine and explain several Alloy models.
Chapter 3 introduces core extraction, a technique for detecting unintentional over-constraint by showing the user unused portion of the model. We introduce the tech-nique in the context of a general constraint language, and discuss its implementation. We prove the correctness of the algorithm, and report on our experience in applying to several Alloy models.
Chapter 1
Declarative Modeling: Benefits
and Drawbacks
"There is nothing so annoying as a good example!"
Mark Twain
Roughly speaking, there are two ways to model a transition system 1 2. In the operational idiom, transitions are expressed using assignment statements, either with
the control flow of a conventional imperative program (as in Promela, the language of the Spin model checker [16]), or using a variant of Dijkstra's guarded commands (as in Murphi [11] and SMV [7]). In the declarative idiom, transitions are expressed with constraints, either on whole executions, or, more often, on individual steps. This idea is rooted in the early work on program verification; the operation specifications of the declarative languages VDM, Larch and Z are essentially the pre- and post-conditions of Hoare triples.
For readers unfamiliar with these idioms, it may help to think of an operational specification as one that gives a recipe for constructing new states from old ones, and a declarative specification as one that gives a fact that can be observed about the
'This introduction is largely lifted from Daniel Jackson's description of declarative modeling, as given in [19]. It has been altered to suite this document, but it retains much of his content, organization, and elements of his style.
2
A transition system is a model which specifies states and actions which cause the system to
relationship between old and new states. An operational modeler asks "How would I make X happen?"; a declarative modeler asks "How would I recognize that X has happened?".
The advantage of the operational idiom is its executability. A simulation, either random or guided by inputs from the user, can give useful feedback to a designer. In model checking, the ability to generate a state's successor in a single computational step makes it possible to explore the reachable state space by depth-first search (as in Spin [7]). In contrast, declarative models have been viewed as not executable, and less amenable to automatic analysis in general, since even generating successors requires search. Recently, however, we have developed an analysis based on SAT that allows both simulation and systematic exploration of declarative models [22]. A common form of analysis that we perform is similar to bounded model checking [4]: the SAT solver is used to find traces that violate specified properties. In fact, earlier symbolic methods could also handle models with declarative elements. The earliest versions
of SMV, for example, provided a construct for expressing transitions implicitly. Its
analysis, being symbolic, was not hindered by the inability to generate successors of a state constructively.
The advantage of the declarative idiom is its expressibility. For some kinds of problem, especially the control-intensive aspects of a system, the operational idiom can be more natural and direct. But in many cases, especially for software systems, the declarative idiom is more flexible, more natural, and sometimes, surprisingly, more amenable to analysis. In many contexts, it is more natural and concise to use a declarative description; often one need only to describe the rules of the game and what it means to have won, and not ever think about what moves will be needed (and which must be avoided) in order to win.
1.0.1
Benefits of Declarative Modeling
Partial Descriptions. The declarative idiom better supports partial descriptions.
Sometimes, only one operation is of interest. In a study of a name server [27], for example, only the lookup operation was modeled and analyzed, since the operations
for storing and distributing name records were straightforward. An explicit invariant on the structure of the name database took the place of the operations that in an operational model would define the reachable states implicitly. Even if the lookup operation were not written declaratively, the need to account for the invariant in
generating initial states makes the description essentially declarative.
Underspecification. The need to constrain a model's behavior only loosely arises
in many ways. It arises when implementation issues are to be postponed or ignored; analysis of a cache protocol, for example, can establish its correctness irrespective of the eviction policy. It arises when analyzing a family of systems: an analysis can check that a collection of design or style rules implies certain desirable properties, and thus that any system built in conformance with the rules will have those properties too. And it arises when accounting for an unpredictable environment: checking a railway signaling protocol, for example, for all possible train motions. In these cases, a declarative description is often succinct and natural, where an operational idiom would, in contrast, require an explicit enumeration of possibilities. Cache eviction, for example, might be specified by saying that the resulting cache, viewed as a set of address/value pairs, is a subset of the original cache. The motion of trains on a network might be specified by saying that the new track segment occupied by a train is either its old one, or one connected to it.
Analyzing Specifications. Specifications can be used not only as yardsticks of
analysis, but also as subjects in their own right. It is easy to make mistakes writing specifications, so it helps to analyze their properties directly: to check that one fol-lows from another, for example, or to generate executions over which specifications differ. If the model and specification are written in the same declarative language, 'masking' is possible. If the model M fails to have properties P and Q, we might want to know whether the problems are correlated. By checking the conjunction of P and M against Q, we can find out whether fixing M so that it satisfies P would also fix M with respect to Q. A declarative analyzer also helps refactoring; any fragment of a model or specification can be compared to a candidate replacement by conjecturing the equivalence of the two.
Non-Operational Problems. Some problems are simply not operational in nature,
and demand a logical rather than a programmatic description. Alloy has been used, for example, to check the soundness of a refinement rule: this involved modeling state machines and their trace semantics, and checking that the rule related only machines with appropriately related semantics. Many subjects are well described in a rule-based manner: ontology models, security policies, and software architectural styles, for example.
Topology Constraints. Sometimes one particular aspect of a system has a
declar-ative flavor. For example, many distributed algorithms are designed to work only if the network's topology takes some form, such as a ring or tree. A declarative model can be constructed that constrains the network appropriately, but does not limit it to a single topology. The analysis will then account for all executions over all acceptable topologies (for a network of some bounded size). The Firewire example described in Sections 2.5.3 and 3.4 exploits this benefit.
Avoiding Initialization. In some systems, normal operation is preceded by an
initialization phase in which the system is configured. An operational description of such a system will suffer from traces that are made longer than necessary by their initialization prefixes. A declarative description can bypass the initialization phase with an invariant that captures its possible results, thus shortening the traces. The result is not only simpler description, uncluttered by the details of initialization, but also more efficient analysis, since a bounded model checking analysis can use a lower bound on trace length and still reach all states.
1.0.2
Under- and Over-constraint
"Example is the school of mankind, and [we] will learn at no other"
Edmund Burke
The very mechanisms that give declarative modeling its power - conjunction and negation - also bring a curse. Any modeler faces the dual risks of underconstraint and overconstraint. In a declarative setting, underconstraint turns out to be easy to
notice and correct, while overconstraint is both difficult to recognize and dangerous when it goes undetected.
Underconstraint An underconstrained model does not eliminate all the situa-tions which the user intended to eliminate. The consequence of underconstraint is the discovery of bogus or absurd counterexamples. When the user encounters such a counterexample, it is obvious that the model is underconstrained and usually straight-forward to add a constraint to the model to eliminate the extraneous solution. Fur-thermore, if the user does not discover the underconstraint there is no harm done: If a valid counterexample is generated despite the underconstraint, the user still has found a fault in the system. If there are no counterexamples despite the underconstraint, then the user has inadvertently proven a stronger claim than intended.
Overconstraint It is unfortunately easy to write a model that has fewer behaviors than intended. An overconstrained model does not allow some or all behaviors that the user intended to investigate. A check of a safety property may then pass only because the offending behavior has been accidentally ruled out (probably along with many other behaviors). In the extreme, an overconstrained model may have no so-lutions at all. As a result, there will be no counterexamples to any assertion! Such situations are easily detected simply by analyzing the model - effectively a liveness check'. The much more worrisome case is when the model is satisfiable, but bugs in the constraints have accidentally eliminated those cases which violate the asser-tion. The analyzer will (correctly) report that there are no counterexamples to the model the user actually wrote, and the user will (erroneously) interpret this to mean that there are no counterexamples to the model she intended to write; unlike with underconstraint, undetected overconstrained is a serious problem.
The risk can be mitigated by working carefully. One can exploit the ability to build and analyze a model incrementally, adding as few (and as weak) constraints as possible to establish the required safety properties. One can simulate the model
3
1f your analyzer can only check an asserted property, then one can perform a liveness check by
extensively, adding conditions to force execution of interesting cases. And of course one can formulate and check liveness properties, at least ruling out the most egregious overconstraints, such as those that lead to deadlock.
None of these approaches, however, counter the risk of overconstraint that is relevant to a particular safety property. The worst overconstraints are not the ones that rule out most behaviors, since they are usually easy to detect, but the ones that rule out exactly those behaviors that would violate the safety property. Since the purpose of checking a safety property is precisely to find behaviors that violate it, we are hardly likely to be able to formulate a liveness constraint to ensure that those behaviors are possible! And of course a liveness check can itself be confounded by an overconstraint that rules out those traces that would be counterexamples to the liveness check itself. A property-specific detection of overconstraint is thus required, and core extraction, introduced in Chapter 3, is exactly such an analysis.
1.0.3
Writing and Analyzing Declarative Models
Let's consider what the world looks like from the eyes of a modeler developing a declarative description about a subject system. The modeler begins with an empty set of constraints, allowing all possible worlds and behaviors. Each constraint added to the model eliminates some class of situations, and a complete model reduces the
set of possibilities to a meaningful subset. Typically, the model eliminates those which cannot occur in the subject system. That set of solutions is searched for a solution which violates a user-defined property - thus finding solutions which should not occur in the subject system. Solutions are reported to the user as counterexamples
- situations which are possible but undesirable.
For example, one could write a model M with constraints that restrict the world to those cases where trains obey traffic signals. One might then write a safety property
P which states that trains never collide. Solutions to the equation M A -,P are
counterexamples to the claim that traffic signals are sufficient to prevent collision. In order to enumerate all the worlds satisfying the model, it is necessary to bound the size of the universe. Such a bound is known as the scope of the model. The
implication is that counterexamples are sound but not complete (although they are "complete up to scope"). The role of model checking is to find bugs, not to prove properties, and the assumption is that many bugs can be revealed by small examples [2]. However, by giving up the ability to prove a property for any bound (such as a theorem prover does), the search process is made completely automatic.
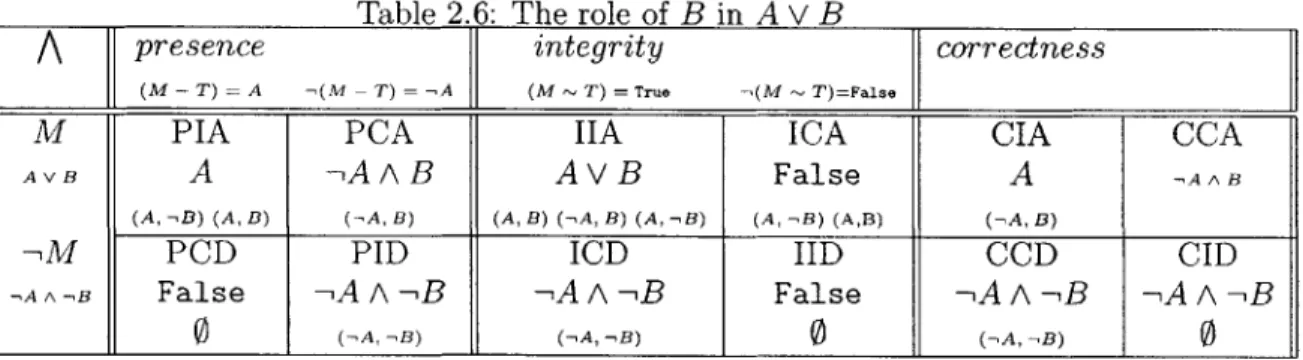
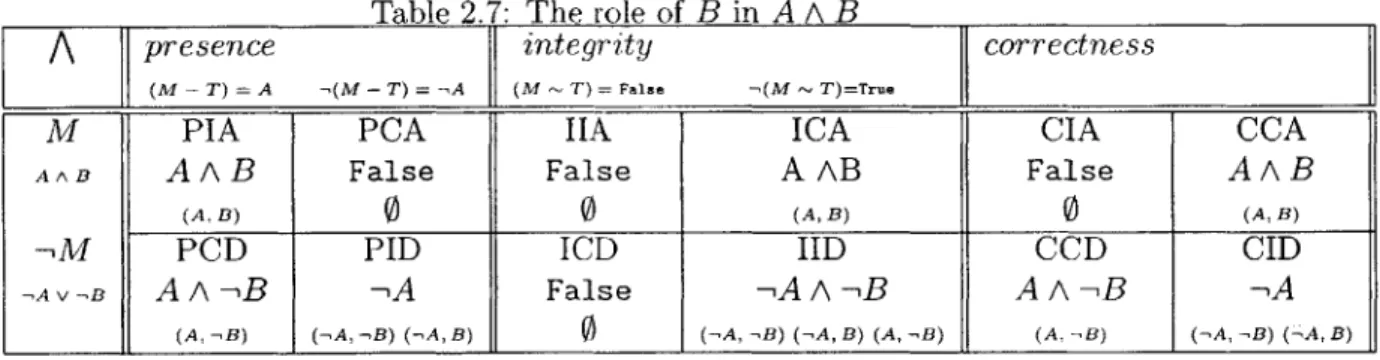
Each new conjunct serves to eliminate some set of solutions, but a subformula of one of those conjuncts may actually relax the model and increase the number of solutions. For example, a top-level constraint of the form "A or B" excludes solutions but the subformula "B" within that constraint allows solutions. In Chapter 2, we introduce non-example generation, which explains the role played by a subformula of a model by classifying it as either relaxing or restraining, and by computing solutions it is responsible for including or excluding.
1.1
The Alloy Language
In developing the process of non-example generation, we will start with symbolic logic and build up to more sophisticated logical languages, such as first order logic, relational logic, and eventually the Alloy modeling language [9, 21, 8] . The techniques described in this paper are not particular to the Alloy language. Rather, they are particular to logical, declarative modeling languages of which Alloy is an example.
1.2
Errors: Modeling Bugs vs. System Faults
One of the chief benefits of writing a model about a piece of software or other system is the discovery of faults in that system. This goal is reflected in the division of a model into a description of the system and a property (which typically asserts the absence of a particular class of faults). Of course, the model may iself contain errors. Bugs are a risk of any language, although certain kinds of bugs (such as overconstraint) are especially problematic for declarative models. It is important to distinguish bugs in the model from faults in the system being modeled. The techniques in this thesis
help the user resolve the tension and interaction between these two types of errors.
Chapter 2: non-example generation
Whether or not there are solutions to the model, we wish to understand the role that particular portions of the system play in preventing (or failing to prevent) faults. By understanding the role that a constraint actually plays, and contrasting it to the role we think it should play, we not only discover bugs in the model, but we also gain insight into why there are or no faults in the system.
Chapter 3: core extraction
The absence of counterexamples indicates that either there are no faults in the system or that bugs in the model are masking all of the system's faults. Unintentional overconstraint can often be found by identifying which parts of the model played a role in making it unsatisfiable (and which were irrelevant).
Chapter 2
Non-Example Generation:
Explaining Subformulae
"Give me a fruitful error anytime,
full of seeds, bursting with its own corrections." Vilfredo Pareto
When looking at a logical model, it is natural to ask what role some particular constraint plays in that model. But what sort of an animal is the role of a subformula? In this chapter we discuss some of the ways logicians and philosophers have addressed this issue, and we propose non-example generation as a lightweight alternative. This technique explains the role of a formula by calculating what would happen differently if that formula were absent or altered.
This chapter begins by motivating non-example generation as a lightweight al-ternative to counterfactual reasoning for explaining models. Conjunction diagrams
are introduced as an effective notation both for presenting non-example information to the user and for proving handy properties about the technique. Equipped with a good notation, the technique can be extended beyond propositional logic to include first order logics, relational logics, and logics with declarations and named predicates. Non-example generation is applied to several existing models and experiences are reported.
2.1
Motivating Non-Examples
"A life spent making mistakes is not only more honorable,
but more useful than a life spent doing nothing."
George Bernard Shaw
One often wishes to know what would be the case if the world were slightly different than the way it currently is. When asked to explain a phenomenon, a common answer is to describe how that phenomenon would have differed had the world been slightly different. Understanding a situation means understanding the influence that small changes to the initial conditions of that situation have on its the outcome. Let's consider an example.
2.1.1
Windows and Rain
One morning, you notice that you left your bedroom window open overnight. Ex-plaining to your child why this is a problem, you say something along the lines of "Had it rained, then I would have gotten wet.". One can also present the situation the other way around: having woken up, you notice that it rained last night. You explain why it is a good thing your window was closed by saying "Had I left the window open, then I would have gotten wet.". This example is deceptively simple. Figure 2-1 shows a formalization of it in the Alloy language.
The model begins by defining the set State and 8 subsets. The following fact ensures that opposite pairs of those subsets partition the set of states. E.g. every state is either in Rain or Sunny but not both. The Physics constraint describes the conditions under which you get wet. If the window is broken, then you get wet whenever it rains. If the window is intact, then you get wet whenever it rains while the window is open. The Diligent constraint ensures that you close the window whenever it rains.
At the end of the model, we ask to analyzer to show us an example of the system. We also check the StayDry assertion, which states that you're always dry if the window is intact. No such cases are found, and the assertion passes.
module rain sig State {}
sig Rain, Sunny, Wet, Dry, Open, Closed, Broken, Intact in State {} /* In any given state, the weather is either rainy or sunny, the
* window is either open or closed, the window is either broken or
* intact, and you are either wet or dry. */ fact Partitions {
//the weather outside
Rain + Sunny = State
no Rain & Sunny //your bedroom window
Open + Closed = State
no Open & Closed
Intact + Broken = State
no Intact & Broken //your status
Wet + Dry = State
no Wet & Dry
}
/* If the window is intact, you get wet when the window is open and it
* rain. If the window is broken, you get wet when it rains. */ fact Physics {
all S: State I S in Intact =>
(S in Rain and S in Open <=> S in Wet) all
S:
StateI
S in Broken =>(S in Rain <=> S in Wet)
}
/* You always close the window when it rains. */
fact Diligent {all S: State I S in Raining => S in Closed}
pred example() {}
run example for exactly 1 State expect 1
assert StayDry {all S: State
I
S in Intact => S in Dry} check StayDry for exactly 1 State expect 0Figure 2-1: An Alloy model of the relation between the weather, the status of your bedroom window, and whether or not you get wet.
Intuitively, the Diligence policy has something to do with why we manage to stay dry as long as the window is intact. How can we ask the model to verify and elaborate on that intuition?
2.1.2
Counterfactual Reasoning?
"If I had only known, I would have been a locksmith."
Albert Einstein
At first, this looks like a task for counterfactual reasoning. Counterfactual reason-ing asks how the world would be different if some variable had taken on a different value. For example, we might counterfactually inquire "What would have happened had the window been left open last night?" and expect an answer along the lines of "I would have gotten wet.". Philosophers and logicians have worked on formal-izing counterfactual reasoning in a number of ways. However, we will see that each solution either produces undesirable results or requires significant extensions to the logic in which the model is written. The task at hand is to answer questions about propositional logic, so requiring the user to rewrite her model in a different logic is unacceptable.
Adding to the World
Consider a model M from which you can draw some conclusion C. If we add a new
fact N, stating our counterfactual supposition, we can draw some new conclusion Cil.
MFC
(M A N) I- C'
Unfortunately, this approach tends to produce one of two useless results for C': 'Astute readers may object to the use of the proof symbol I- when we are talking about model checkers whose finite limitations prevent them from producing proofs. For the purposes of this discussion, imagine that our analyzer can examine infinitely many possible worlds. The finite bound put on a model is an issue of analysis not of semantics; the model is written as if the world were arbitrarily large (or even infinite), and the bound is only enforced when we actually analyze the model. In principle, conclusions can be proven from models. In practice our method of analysis does not consitute proof.
1. Contradiction: Suppose the new constraint N contradicts the previous model M. For example, N might be "It rained last night and I left the window open."?
This constraint contradicts the Diligent constraint already in M, so the new model, M A N, is inconsistent. We would conclude that there are no possible worlds in which it rains and the window is open.
2. Odd Causality: Even in the case where N does not contradict M, C' may be a very odd conclusion. If we instead added the weaker constraint N = "I
left the window open last night.", then analysis of the model M A N will tell us that it could not have rained. We have learned that opening our window prevents rain!
Entailment vs. Causality
In the second case, had we instead added the constraint "It rained last night", then the analyzer would tell us that we couldn't have opened the window. While this is not quite what we want (since we were hoping to learn that we might have gotten wet), it is at least consistent with our intuition about causality. Why does asking about changing the state of the window ("What if I had left the window open?") produce an unintuitive result yet asking about changing the state of the weather ("What if it had rained?") produce a sensivle result? Where does the asymmetry come from.
The problem is that Diligent is written in propositional logic, and thus uses
logi-cal implication not causal implication. In Diligent, we wrote that (Rain -> Closed).
From that formula, the law of the contrapositive lets us conclude that (,Closed
-,Rain). However, the law of the contrapositive does not apply to causal implication;
the formula (Rain causes Closed) does not imply that (,Closed causes ,Rain). Unfortunately, without adding a "causes" operator to the language, we cannot accurately represent causality, as discussed by Avi Sion [40] and John Stuart Mill [34].
Changing the World
To avoid producing the contradictions we saw in Section 2.1.2 when we added con-straints to the model, we might consider instead changing part of the model. In this approach, an old fact N in replaced with a new fact N', thus producing a new
(hopefully meaningful) conclusion C'.
M _ C
M[N +- N'] I C'
The complication here is that you cannot just change part of the state without vio-lating constraints in the model. As before, we cannot force the window to be open when it it raining without violating the Diligent constraint.
We are faced with a serious dilemma: Changing part of the world requires one of two approaches:
1. Constraint Violation One solution is to allow constraints to be violated if
neces-sary. Unfortunately, we will end up with situations which violate fundamental aspects of the model. For example, we might generate the situation in which it is sunny and I close the window, yet I get wet (violates Physics). That is hardly an explanation of how the model works!
2. Variable Alteration The other solution is to update other variables until all constraints are satisfied. However, there may be several different ways to change the world, all of which satisfy the constraints. Offhand, it is unclear which one to choose.
Fixing Constraint Violation: Laws vs. Policies
One might try to avoid the problems with constraint violation by classifying facts into "fundamental laws", such as Physics, versus "preferred policies", such as Diligent. When making a counterfactual inquiry, one only allows policies to be violated. In our simple model, such a distinction would indeed avoid the problem - the diligence constraint may be violated but the physics constraint may not.
Such a distinction would require that the user annotate the model. Besides being
extra work for the user, it might not even be feasible - the user is asking about the model in order to understand it better and may not feel qualified to make such distinctions.
Furthermore, imposing such a distinction limits the questions one can ask - why not allow the user to ask why a funamental law is necessary? For example, what roles
does the Physics constraint play in our toy model?
Even worse, this solution does not always avoid our previous dilemma. If our supposition violates a fundamental law then we will have to either change the value of some of the other variables or accept that one of the fundamental law is violated. We are back where we started.
Fixing Variable Alteration: Closest Possible World
Since constraint violation seemes irreparable, let's look at how variable alteration can be improved. David Lewis [31] developed an approach to change the world to satisfy all the constraints, but to do so in a deterministic and sensible manner. In order to determine what would have happened if some event E had occurred, consider the closest possible world in which E holds. In this manner, we only consider worlds in which all the constraints are satisfied, but use a distance metric do decide which other variables should be changed. See Section 2.7.4 for his exact words on the matter.
In our simple example, this seems to work. Given that last night we observed the state
Rain, Closed, Intact, Dry
we ask "What if the window had been open?". By the Closest Possible World defini-tion, we want the state which is closest to the state
Rain, Open, Intact, Dry
but which satisfies the model. If we use a simple bit-comparison metric (the distance between two states is the number of variables on which those states differ), then
closest such state is
Rain, Open, Intact, Wet
which is exactly what we want to see; if we had left the window open in the rain, then we would have gotten wet.
The chief objections to this approach are the oddities which develop in very de-tailed models. The traditional example of an unintuitive result is the so called Nixon
Paradox, originally pointed by Kit Fine in 1975 [12]: "What would have happened
if Nixon had pushed the button to launch nuclear weapons at Russia?". We expect an answer along the lines of "Russia would have retaliated, reducing both nations to radioactive ash.". However, if we look at the closest possible world to our own in which nixon pushed the button, we instead conclude "There would have been an electrical failure so that the button did nothing, after which Nixon would have come to his senses.".
Problems such as the Nixon Paradox arise when the model becomes very detailed and models unlikely events and corner cases. The model analyzer has no notion of probability and so it will happily make rare events occur if doing so will produce a solution which has a shorter distance. To correct this shortcoming, the model needs a notion of probability - when selecting the "closest possible world" the possibilities need to be weighted by likelihood as well as similarity. Extending traditional logic to include such a notion is an interesting avenue, but it is not the task at hand.
2.1.3
Events vs. Policies
So far, the only ways we've seen to do counterfactual reasoning involve making non-trivial additions to our logic. In fact, there is a solution to this problem which does not involve counterfactual reasoning and all the complexities that go along with it. Rather than asking the role of a bit of the state (e.g. whether or not the window was open), consider asking about the role a constraint plays (e.g. the diligence policy).
What you really want to know is not the role of closing the window on that one occasion, but the role of the constraint which makes you always close the window in
such situations. Instead of "If I left the window open, then ..." you would say "If
I were not diligent, then ..."; we will examine explaining the policy that lead to the action, not the action itself. In order do do this, we will need to develop a notion of the role of a constraint. In fact, the formalism we develop will not only let us ask for the role of a constraint, but also about the role of an arbitrary subformula of a constraint.
2.1.4
What is the Role of a Formula?
What kind of an animal is the role of a formula? I appeal to the intuition of what a human would say to another human to explain such a thing; its role is what it allows or what is disallows, or how it interacts with another part of the model. For now, we will focus on non-example generation, which addresses the first view. Core extraction, described in Chapter 3, addresses the second.
Note that this approach lends itself to a model-theoretic view of the world rather than a logical view of the world. That is, it looks at enumerating the solutions (within some bound) and looking at how that set changes, rather than using syntactic manipulations to produce a proof.
Naive Role Computation
The naive approach is to just check the StayDry assertion once with Diligent present and once with it absent. This might get us what we want, if we get either of the following results:
(a) if neither check finds any counterexamples, then we know that Diligent is redundant; we stay dry either way.
(b) if the first check passes but the second finds a counterexample, then we have
an example of a circumstance where Diligent is necessary to ensure StayDry. The role of Diligent is to eliminate that case (and others like it).
As the model stands, we expect the second result. However, we might not be so fortunate; consider the situation in which the window is broken. In that case, there's
nothing you can do to stay dry if it happens to rain, be you diligent or not. The two possible results of the naive approach are the following:
(a) if both checks return the same counterexample (e.g. where the window is bro-ken), you now know one case where Diligent is irrelevant since you will get wet anyway. However, you don't know if there are cases where Diligent does matter.
(b) if both checks return different counterexamples, you have learned even less.
Perhaps each counterexample is actually a solution to both checks, or perhaps not.
What we really want is to solve for a counterexample which is only valid because Diligent was not enforced. We want an assignment which is not a solution to the model with Diligent enforced, but which is a solution when it is removed. This can be expressed as a solution to
-M A (M - D)
where M is the model, and (M - D) is the model with the Diligent constraint
removed. Solutions to this formula are cases which are disallowed by the presence of Diligent. We now get the desired solution <Intact, Open, Raining, Wet>. We term this approach non-example generation, since we are generating assignments which are almost solutions to the model, but not quite. In particular, we gener-ate assignments which would be solutions except that they fail to satisfy the target subformulae.
In the next section, we will formalize this notion of role in terms of non-examples, develop a convenient notation (conjunction diagrams), and prove some handy lemmas. Later, we will extend the technique beyond propositional logic.
2.2
Formalization and Representation:
Conjunction Diagrams
"In a few minutes a computer can make a mistake
so great that it would have taken many men many months to equal it."
Unknown
In the last section, we concluded that to determine the role of the presence of T in M, we should examine solutions to the formula M A -,(M - T); such solutions
satisfy the original model but not the altered model, thus indicating what has been
disallowed by including T in the model. First, we need to formalize what it means
to delete a subformula from a model. Then we will look at other formulae which produce useful information for the user.
2.2.1
Deletion (and Sabotage) Formalized
We need to be precise when we say "delete the subformula T from the model M", denoted (M - T). Here is what it shall mean:
" M is the simple AST of the user's model model. A simple AST is one in which
all logical operations have been desugared into -,, binary A, and binary V.
* T is a node in M, at the root of the target subformula. We assume that T is
not the root of M and that T's parent node is not a negation (although T itself may be a negation). To ask about the role of a subformula which is directly negated, one must instead ask the role of the negation plus that subformulae.
A well formed tree results when the subtree rooted at T is removed from the AST
M, except that the old parent of T will now be either a unary A or a unary V. That
node is interpreted using the following semantics, making (M - T) a simple AST:
unary and A (x) = x unary or V (x) = x
Constant Replacement
It will be convenient to talk about deletion in terms of replacing T with a Boolean constant. To that end, we prove the following result:
Theorem 1:
(M - T) is either equivalent to M[T <- True] (the formula obtained by replacing
T with the constant True), or it is equivalent to M[T <- False] (the formula obtained
by replacing T with the constant False). Proof:
Since M is simple and we have discounted the case were T's parent is a negation
(,), we know that T's parent is either an A or an V. If T's parent is an A, then (M - T) - M[T <- True]. If T's parent is an V, then (M - T) = M[T <- False].
This property of deletion leads us to define the complementary notion of sabotage, which will prove useful later on when we define a notion of correctness (Setion 2.2.4).
Definition:
Let C be the constant for which (M - T) = M[T <- C]. The result of sabotaging
T within M, denoted (M ~ T), is M[T <- -,C].
One way of thinking about sabotage is as follows: Where deleting T from M leaves the rest of M as intact as possible, sabotaging T in M simplifies the rest of M as much as possible, to the extend that altering T can. For example,
(AAB)-B = AATrue =-A
(AAB)~B _ AAFalse =-False
Sabotaging a subformula produces the maximum possible effect that the subformula could have on the entire model.
2.2.2
Conjunction Diagrams
It is now clear exactly what we mean when we write M A ,(M - T). It will also prove
fruitful to consider the other 3 possible combinations of negating and conjoining those two formulae: -M A (M - T), M A (M - T), and ,M A -,(M - T). A convenient
form for representing these combinations is a conjunction diagram. Definition:
A conjunction diagram is a table constructed from two sets of logical formulae:
one set is written as labels on the columns of a table and the other as labels on the rows. An entry in the table contains a formula (the conjunction of the row and column formulae) and/or a set of assignments (solutions to that formula).
Table 2.1: A generic conjunction diagram with column formulae Coll and C012 and row formulae Row, and Row2
A
Col1
Col2Row1 Col1 A Row1 0012 A Row1
Row2 Col1 A Row2 Col2 A Row2
In our case, the row formulae will be always be M and -,M. When we draw the conjunction diagram for deletion, the column formulae are (M - T) and -,(M - T).
Later we will add additional column formulae.
Table 2.2: The generic conjunction diagram for deletion
A
(M - T) (M - T)M PIA PCA
Presence Irrelevant to Allowing Presence Crucial to Allowing
MA(M-T) M A -,(M - T)
,M PCD PID
Presence Crucial to Disallowing Presence Irrelevant to Disallowing ,-M A (M - T) -,M A -,(M - T)
Conjunction diagrams are both useful for performing proofs and for presenting the information to the user. However, it is probably unreasonable to expect to teach the user the precise semantics of conjunction diagrams just to be able to answer simple questions. To that end, each entry is also given a name which indicates the meaning to the user of the solutions in that cell.
* M A (M - T) produces solutions to the original model, M, which are still
solu-tions if T is deleted. We abbreviate this category of solusolu-tions PIA, pronounced
" Al A -(M - T) produces solutions to the original model, M, which cease to
be solutions if T is deleted. We abbreviate this category of solutions PCA, pronounced "Presence Crucial to Allowing".
* -1M A (M - T) produces assignments which are not solutions of the original
model, M, but which become solutions if T is deleted. We abbreviate this category of solutions PCD, pronounced "Presence Crucial to Disallowing".
* ,M A -(M - T) produces assignments which are not solutions of the original
model, M, and are still not solutions if T is deleted. We abbreviate this category of solutions PID, pronounced "Presence Irrelevant to Disallowing".
Each cell of the conjunction diagram contails all solutions satisfying the equation written there. To avoid an overwhelming amount of data, when displaying a conjunc-tion diagram to the user, only one (arbitrarily chosen) soluconjunc-tion is shown in each cell. As we will see in Section 2.5, one solution is often enough to learn interesting things about a model.
Observation: Each possible assignment to variables of M appears somewhere in the conjunction diagram for deletion; for any assignment A,
A E PIAU PCAu PCDU PID
2.2.3
Representing Sabotage
We construct an analogous conjunction diagram for sabotage by setting the column formulae to (M ~ T) and -,(M ~ T). The interpretation of solutions in the con-junction diagram for sabotage are similar to that of deletion. However, instead of referring to the role of T's presence (failure to delete), they refer to the role of T's
integrity 2 (failure to sabotage).
Sabotage represents the maximum extent to which the target formula can influence the structure of the model as a whole. This information is far less valuable to the
2
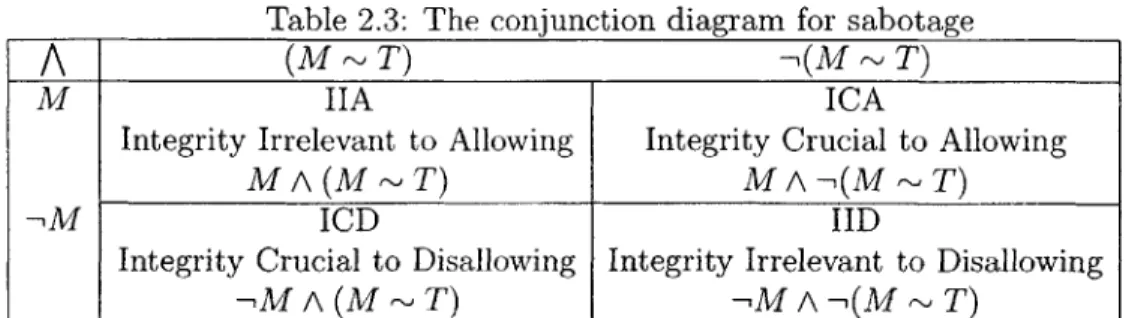
Table 2.3: The conjunction diagram for sabotage
A
(M~
T) -,(M T)M IIA ICA
Integrity Irrelevant to Allowing Integrity Crucial to Allowing
MA(M~T) M A -,(M T)
ICD IID
Integrity Crucial to Disallowing Integrity Irrelevant to Disallowing
,M A (M ~ T) ,-M A ,(M ~ T)
user than is deletion; its real value comes from combining it with information about deletion to compute a notion of correctness (see Section 2.2.4. To that end, it will prove convenient to display the two tables together.
Table 2.4: The conjunction diagram for deletion and sabotage
A
(M-T) -,(M-T) (M~T) -,(M~T)M PIA PCA IIA ICA
MA(M-T) MA-,(M -T) MA(M~T) MA-,(M~T)
,M PCD PID ICD IID
-,M A(M -T) -,MA -,(M -T) -,M A(M~,T) -,M A-,(M~T)
2.2.4
Theorems
"An expert is a person who has made all the mistakes that can be made in a very narrow field."
Niels Bohr
One can consider other mutations of T, besides replacing it with True or False, and construct comparable conjunction diagrams for them 3. However, it turns out that the 8 formulae represented in the conjunction diagram for deletion and sabotage are sufficient to compute (or bound) the effect of making an arbitrary change to T.
Definition:
Let CIA, pronounced "correctness irrelevant to allowing", denote the set of all assignments which are solutions to M and which remain solutions regardless of how
3
The column formulae will be M[T <- T'] (M with T mutated) and -(M[T <- T']) (the negation of that formula)