LifeCLEF 2016: Multimedia Life Species Identification Challenges
Texte intégral
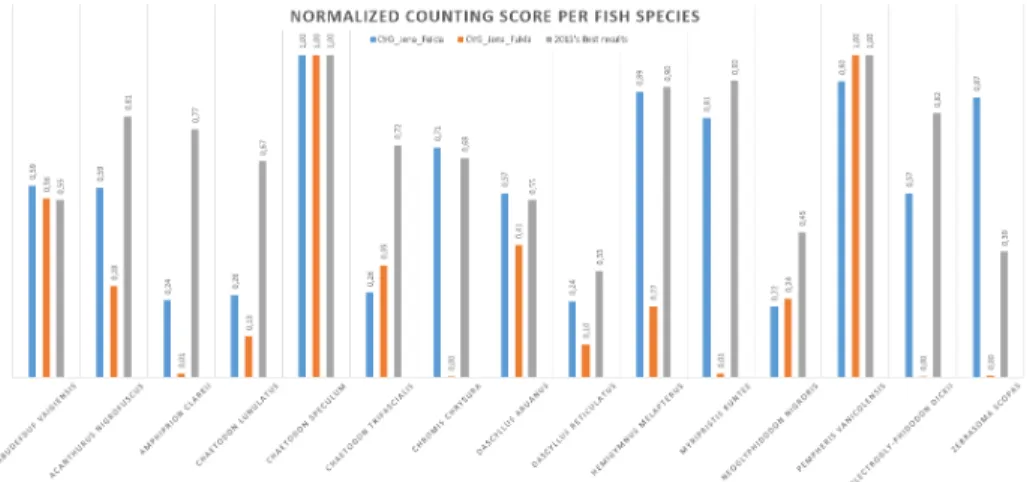
Figure
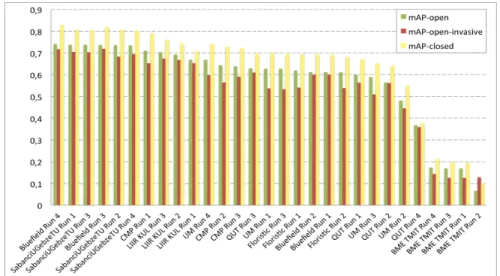
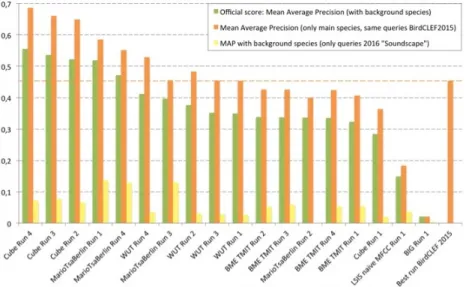
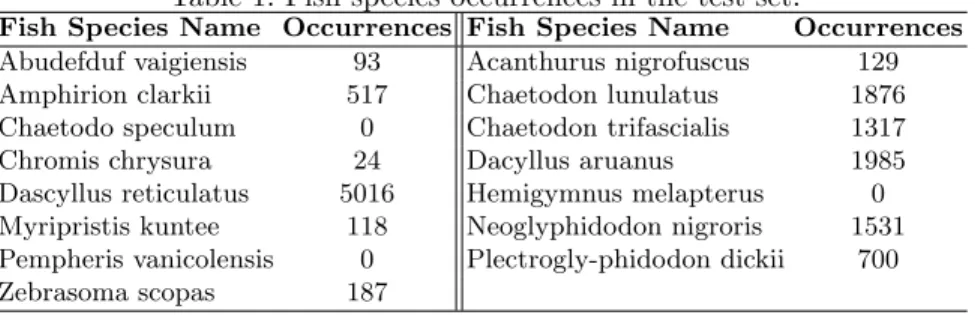
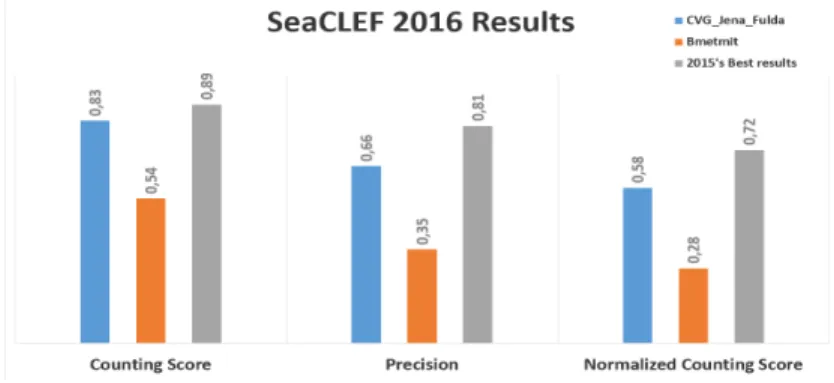



Documents relatifs
Central or peripheral blocks allow the delivery of selective subarachnoid anesthesia with local normobaric and/or hyperbaric anesthetics; lipophilic opioids may be used with due
Polyphenols and vascular health: Demonstration of the role of polyphenols in the vascular protective effects of citrus fruits Christine MORAND, Dragan MILENKOVIC INRA,
Inspired by [MT12], we provide an example of a pure group that does not have the indepen- dence property, whose Fitting subgroup is neither nilpotent nor definable and whose
As can be seen, in this partition of the 16 possible 4-tuples into 3 mutually exclusive subsets, L corresponds to the truth table of the analogy A, K gathers the 8 patterns including
The Board of Directors does not approve the proposed resolution A During its meeting held today, the Board of Directors reviewed the proposed resolution A submitted by a group
It however radically enlarges the evaluated challenge towards multimodal data by (i) considering birds and fish in addition to plants (ii) considering audio and video contents in
La mise en place de la synergologie peut alors être bénéfique à une entreprise, pas seulement lors des processus de recrutement, mais également à d’autres
Bluefin Tuna and the Yellowmouth Rockfish to the List of Wildlife Species at Risk ANNEXE Déclaration énonçant les motifs des décisions de ne pas inscrire le thon rouge de
