House calls : building and maintaining a rule-base
Texte intégral
Figure
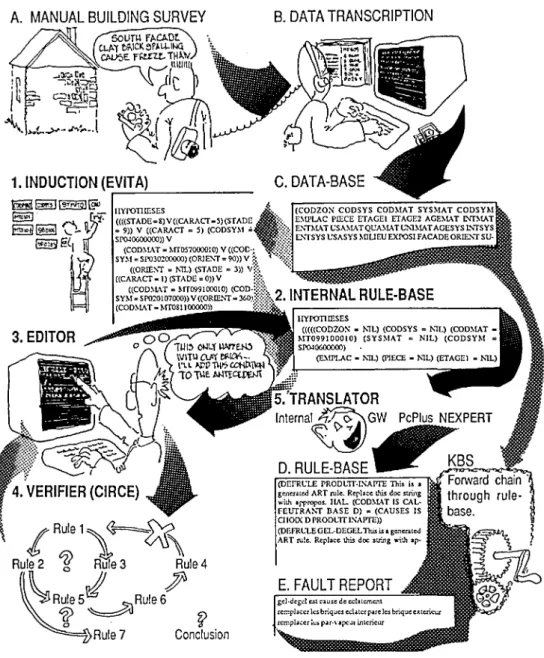



Documents relatifs
They live in a lovely cottage in Stratford-upon-Avon, England. The house is not very big but my grandmother keeps it clean and tidy. It has only got one floor and the attic. In
safekeeping. The pynabyte utility DYNASTAT displays your current system configuration. 'The steps described below will change the drive assignrnentsso that you will
Further, we define properties for the ontology, the set of is-a relations to repair and the domain expert, as well as preference criteria on solutions and dis- cuss the influences
They will take the child URGENTLY to the health facility, if the sick child has any of these danger signs (Picture 1):?. o Is unable to breastfeed or stops
To help bridge the knowledge gap on noma and to improve early diagnosis, detection and management of cases at primary health care level in countries contending with the disease,
non-existence: “a metaphysics of relations merely has to reject the second part of this claim: one can maintain that (a) relations require relata, that is, things which
Mais c’est enfin avec cette ultime saison, la huitième, qu’ils pourront assister à l’épilogue de cette saga qui aura marqué l’histoire des séries télévisées de par
This case involves a number of return-related problems that can be found elsewhere and put in a comparative perspective; it might also shed some light on the specific
