Entropic Optimal Transport between Unbalanced Gaussian Measures has a Closed Form
Texte intégral
Figure


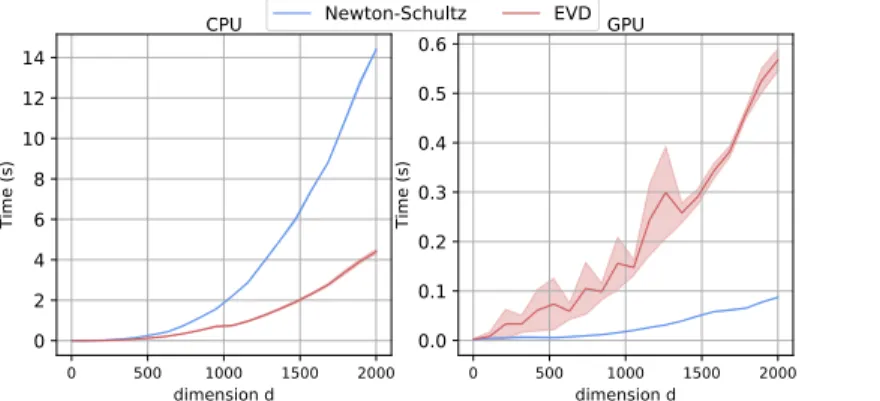
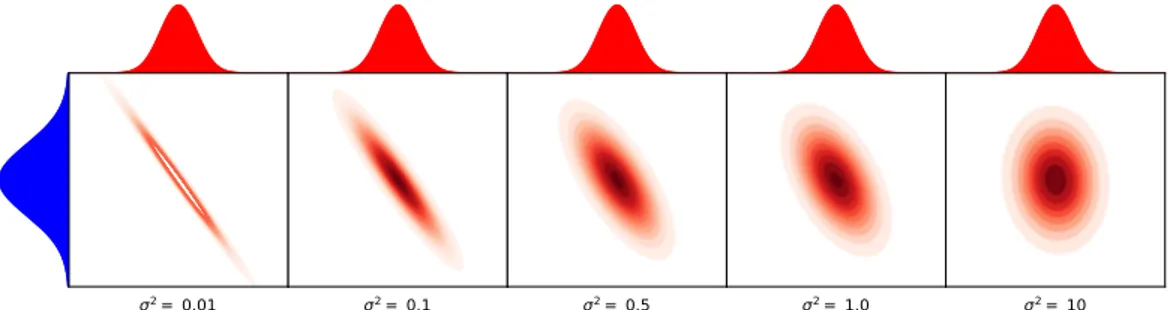

Documents relatifs
Keywords: Credit Risk, Intensity Model, Strutural Model, Blak-Cox Model, Hybrid.. Model, Parisian options,
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
The results of o -line calibration using [4] and the results of applying our self-calibration methods to eight stereo image pairs of the grid are compared in Table 1, for the left
Although the proposed closed-form method is more computationally complex than block- level precoding schemes, our results show that in return, it provides substantial gains over
In this paper, we derive a closed- form expression of the WWB for 3D source localization using an arbitrary planar antenna array in the case of a deterministic known signal..
We observe that the con- ventional FRC curve reaches the closed-form FRC for some values of the sampling step of the discrete rendered image, as well as the parameters of the
Observation of SEM pictures of the fluorine-altered substrates and comparison with bare Nitinol samples tend to confirm this erosive behavior: as well with
So for the simplex a different approach is needed and ours is based on the Laplace transform technique already used in our previous work in [6] for computing a certain class
