General Strategy for the Design of DNA Coding Sequences Applied to Nanoparticle Assembly
Texte intégral
Figure
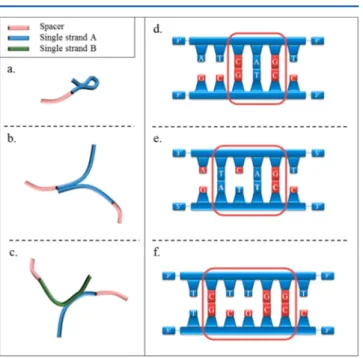
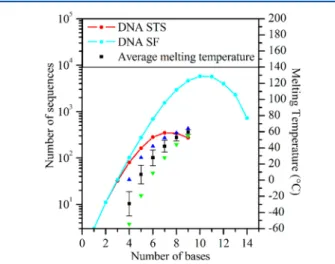
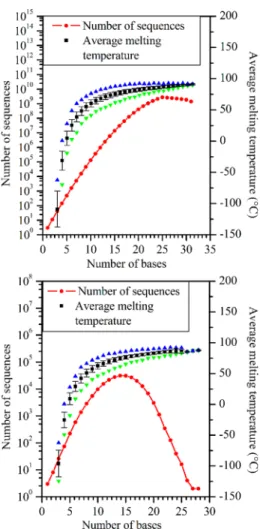
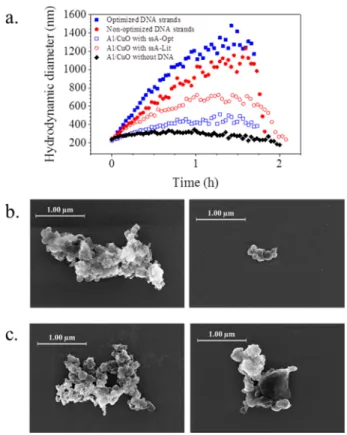
Documents relatifs
(A) Immunofluorescence analysis of U2OS cells transfected with siCT or siING3 and then subjected to laser micro-irradiation, treated with doxorubicin for 3 hours or
Réalisation d’une étude rétrospective analysant les complications materno-fœtales entre les patientes diabétiques de 2008 et de 2014 selon les anciennes (critères de Carpenter
We propose here to model the impact of replication fork polarity, gene orientation and transcription rate on substitution rates.. The model we propose is the simplest model that
Abstract Surgical plugging and resurfacing are well established treatments of superior semicircular canal dehiscence, while capping with hydroxyapatite cement has been little
Finally, collision between replication and transcription machineries in either head-on (converging) or co-directional orientations can directly generate DSBs in E. Possible
La tour Eiffel a été construite par Gustave Eiffel à l’occasion de l’Exposition Universelle de 1889 qui célébrait le premier centenaire de la Révolution française.. Sa
Lorsque tu reçois ta copie, tu dois corriger les erreurs (retourne voir le texte dans le classeur) en réécrivant le mot entier sur la ligne du dessous. Voici quelques conseils
Nevertheless, it seems worthwhile to publish the complete diagrams from Alpe Palii (M3), because the profile shows excep- tionally well the vegetation development
