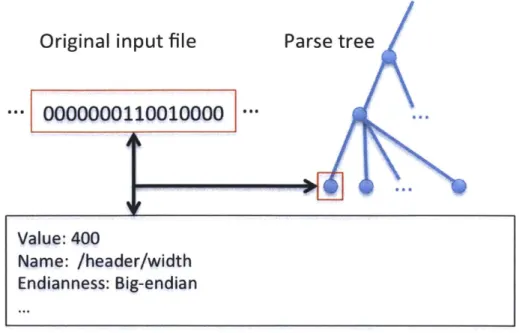
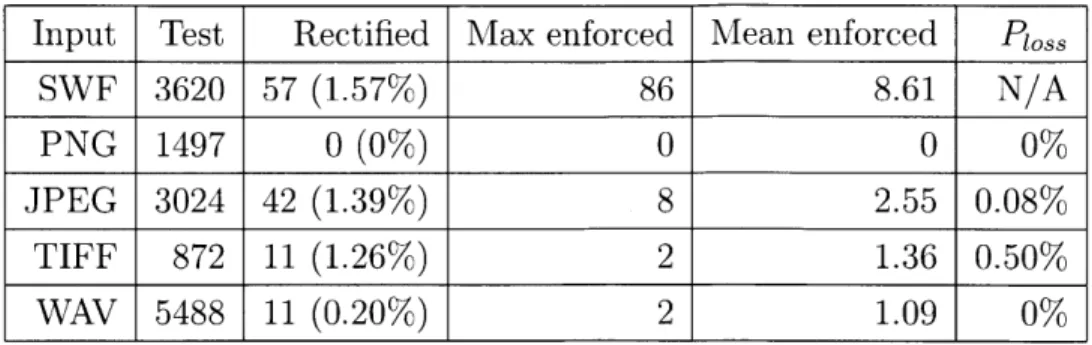
Automatic input rectification
Texte intégral
Figure








Documents relatifs
La plénitude dans le ciel, ou cercle de Gwenved ; et sans ces trois nécessités, nul ne peut être excepté Dieu. îS Trois sortes de nécessités dans
Moreover also the visualization modalities chosen to present the user model can have an impact on the comprehensibility of the user model itself. We hypothesized that vi-
A second scheme is associated with a decentered shock-capturing–type space discretization: the II scheme for the viscous linearized Euler–Poisson (LVEP) system (see section 3.3)..
Ne croyez pas que le simple fait d'afficher un livre sur Google Recherche de Livres signifie que celui-ci peut etre utilise de quelque facon que ce soit dans le monde entier..
The harmonics caused by the switching of the power conversion devices are the main factor-causing problems to sensitive equipment or the connected loads,
Thus, for type A dynamic secure zones, zone transfer security is not automatically provided for dynamically added RRs, where they could be omitted, and authentication is
At the conclusion of the InterNIC Directory and Database Services project, our backend database contained about 2.9 million records built from data that could be retrieved via
The software at UCLA required that each terminal be allotted 2k (2048 S/360 bytes) core for each connection that is open at any one time. Now, since each terminal could have
