When Textual Information Becomes Spatial Information Compatible with Satellite Images
Texte intégral
Figure



Documents relatifs
The use of the k-means classification for deriving mangrove classes based on vegetation fractions appears to be a valuable approach for analyzing and comparing vegetation
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
As desalination generally produces quantities of brine on par with quantities of potable water produced with the brine going to disposal, using desalination brine for
sur l’énergie d’adhésion en fonction de la vitesse de propagation de fissure. Les essais de pelage ont été effectués le même jour sur des hydrogels synthétisés le même jour.
Cropping systems’ classification Identification of agricultural land-use systems. through
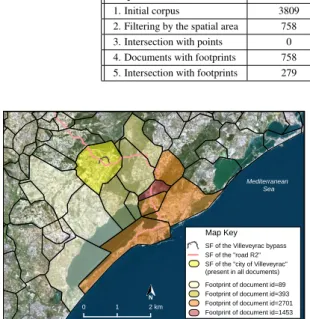
We note that footprints are spatially closer to event previously identified in the representation of the treated spatial object (extracted from satellite images and related to
réactivé la faible densité du parcellaire et du bâti dans le secteur victorin. Ce collège forme un vaste enclos situé entre Saint-Nicolas-du-Chardonnet et Saint-Victor, dans
Here, we present a complete Focused Ion Beam - Scanning Electron Microscopy (FIB-SEM) workflow (from sample preparation to image processing) to generate nanometric 3D
