Digitized
by
the
Internet
Archive
in
2011
with
funding
from
Boston
Library
Consortium
Member
Libraries
I
Dewey
B31
^415
-21
Massachusetts
Institute
of
Technology
Department
of
Economics
Working
Paper
Series
CONDITIONAL
EXTREMES
AND
NEAR-EXTREMES
Victor
Chemozhukov,
MIT
Working
Paper
01
-21
July
2000
RoomE52-251
50
Memorial
Drive
Cambridge,
MA
02142
This
paper
can
be
downloaded
without
charge
from
the
Social
Science
Research Network
Paper
Collection
atMASSACHUSEHS
INSTITUTE OFTECHNOLOGY
AUG
1 5 2001
Massachusetts
Institute
of
Technology
Department
of
Economics
Working
Paper
Series
CONDITIONAL
EXTREMES
AND
NEAR-EXTREMES
Victor
Chemozhukov,
MIT
Working
Paper
01-21
July
2000
Room
E52-251
50
Memorial
Drive
Cambridge,
MA
02142
This
paper
can
be
downloaded
without
charge
from
the
Social
Science
Research
Network
Paper
Collection
atCONDITIONAL
EXTREMES
AND
NEAR-EXTREMES
Victor
Chernozhukov^
Dept. of
Economics,
MIT,
E52-262F,
Cambridge,
MA,
02142
email:
[email protected]
Version:
May
10, 2001 First Version: October, 1998Abstract
This
paper
develops a theory of highand
low (extremal) quantile regression: the linear models, estimation,and
inference. In particular, themodels
coherentlycom-bine theconvenient, flexible linearity with the extreme-value-theoretic restrictions
on
tails
and
the general heteroscedasticity forms.Within
these models, thelimit lawsforextremal quantile regression statistics are obtained
under
the rank conditions (exper-iments) constructed to reflect the extremal or rarenature oftail events.An
inferenceframework
is discussed.The
results apply to cross-section (and possibly dependent) data.The
applications, rangingfrom
the analysis of babies' very low birthweights, (5,s) models, tail analysis in heteroscedastic regression models, outlier-robust infer-ence in auction models,and
decision-makingunder extreme
uncertainty, provide the motivationand
applications ofthistheory.Key
Words: Quantile
Regression
'©July 2000 V. Chernozhukov. Rights Reserved. This paperisa partof
my
Ph.D. dissertation at Stanford, completed in 2000. Iam
very grateful to Takeshi Amemiya, Roger Koenker,Thomas
MaCurdy, Mordecai Kurz, and also to Anil Bera, Stephen Portnoy,
Thomas
Sargent for advise andhelp;Pat Bajari, JosephRomano,Keith Knight, and JanaJureckova, fordiscussionsand from
whom
I learned a great deal; and also friends: IgorMakarov, Stijn Van Nieuwerburgh, Leonardo Rezende, Michael Schwarz, and Lei Zhang, and especially Han Hong, Robert McMillan, Sergei Morozov, and Len Umancev. I thank also the seminar participants at Brown, Caltech, Chicago,
CIRANO,
Duke, Mannheim, MIT-Harvard, Northwestern, Stanford,UCLA, UCSD,
University ofIllinois, Yale, and NeuchatelMay
2000 Conference on Recent Developments in Regression,CEME
2001 Conference, Conference on Economic Applications ofQuantile Regression in Konstanz, 2000, especially J.An-grist, D.Andrews, J. Altonji, M. Buchinsky, P. Christophersen, F. Diebold, G. Elliot, R. Engle,
B.Fitzenberger, C. Granger, J. Hahn, J. Hamilton, L. Hansen, M. Hallin, J.Heckman, G. Imbens, D. Jorgenson, T.Bollerslev, C. Manski, R. Matzkin, P. Phillips,J. Rust, R. Sherman, D. Strook, G. Tauchen, R. Tsay,J. Jureckova, and H.White. 1 alsothank JerryHausman, GuidoKursteiner,Ziad
Nejmeldeen, and Whitney Newey for suggestions that drastically improved the presentation of the
material; and also
Bo
Honore and Charles Manski for suggesting to look into modeling questionscarefully.
I gratefullyacknowledge thefinancialsupport provided by the Alfred P. Sloan Dissertation
Contents
1
Introduction
12
Econometric
Applications
33
Extremal
Quantilesand
Rank
Sequences
63.1 Extremal Conditional Quantiles 6 3.2 Linear Quantile Regression
Model
7 3.3Sample
Regression Quantile Statistics 7 3.4 Extremes, Near-Extremes&
Data
Scarcity 8 3.5 TailTypes, Support Types,and Classical Limits 93.6 Limit DistributionsofOrdinary
Sample
Quantiles 94
The
Extremal
Regression Quantile
Models
114.1
Model
1; Tail Homogeneity 114.2
Model
2: Congenial TailHeterogeneity 135
Asymptotics
under
Extreme Ranks
15
6
Asymptotics under
Intermediate
Ranks
20
7 Inference 23
A
Useful
background
27
A.l Point processes 27
A.2
Convex
Semi-ContinuousObjectives 27B
Proofs
for section 5,extreme
ranks
28B.l Detailsand definitions 28 B.2 Basic conditionsfor nondegenerate asymptotics 29 B.3 Limits in Models 1 and2 32
C
Proofs
for section 6,intermediate
ranks
33
C.l Basic conditionsfor a normallimit 33 C.2 Limits in Models1 and2 34
D
Properties
ofModels
1and
236
1
Introduction
Regression quantiles,
Koenker and
Bassett[48], represent a flexibleand
informativemethod
of regression analysis as they describe the conditional distribution ofthere-sponsevariable
Y
givencovariateX
,withoutimposing
rigiddistributionalassumptions.The
goal ofthispaper
is tomodel
and
make
inferenceon
the extremal {near-extreme high or low) regression quantile functions. In essence, they represent themodels
of the extremal values ofY
conditionalupon X.
For example, the near-extreme 0.1-th conditional quantile function describes the valuesbelow
which
Y
fallswith probability10%
given values ofX.
Modeling
high orlow conditional quantiles is motivatedby
many
examples.Some
include: (i) in micro- economics: (5,s)models
ofinvestment, inventory,employment
shortages; auction models, reservation
wage
equations; (ii) in finance, micro-and
macro-
economics: decision-makingunder
extreme
uncertainty,where
good
riskmea-sures are vital for the purposesofinsurance, safety-first resource allocation,
and
man-agement
ofrisks;and
many
others.The
ordinaryextremalquantiles, themodels
and
thesample
analogs,have been
themain
subject ofclassicaland
modern
extreme
value theory,which
formsan important
field ofapplied
and
theoretical statistics.'^The
theorywas
developedby
Von
Mises,Prechet, Fisher,
Gnedenko,
Smirnov, deHaan, and
many
others.The
ordinarysample
quantiles
have
an
immense
inference role, providing the estimators of the tail indexand
othertailfunctionals (Pickands[57],Hill[40],Dekkers
and
de Haan[21]).Analogous
motivations underliethe present analysis aswell.
Inthis
paper
we
study theextremal (highand
low)conditional quantiles- thelinear modelsand
thesample
regression analogs. In particular,themodels
coherentlycombine
convenient, flexible linearity with the extreme-value-theoretic restrictions
on
tailsand
thegeneral heteroscedasticity forms.
Within
these models, the limitlawsfor extremal quantile regression statistics are obtainedunder
the rank conditions constructed to reflectthe extremal or rare nature oftail events.The
goal is the practical,important
problem
ofmodelingand
making
inferenceon
the .3-thand
lowerand
.7-thand
higher regression quantiles, as well asconducting the tail inference, inthecommon
economic
data
sets.^{Our
target is not the "exotic" 0-th quantile.)The
rank conditionsapproximate
thedegreesof lack ofdataor extremality pertinent tothe inferenceabout
the quantiles ofinterest. Define rank r asthe quantile index r times thesample
size T.The
extreme
and
intermediaterank
conditions apply to the caseswhere
index t is extremal(e.g. .1, .2)and
is low(rissmall) or notlow {rislarge) relativetothesample
sizeT.^ Formally,the sequenceofthe quantileindex-samplesize pairs {tt,T) isan
extreme rank sequence if(i) Tr
\
0,TrT
-^k>
0,and an
intermediate rank sequenceif{ii) T-r
\
0,TtT
—
> GO.-Asoftoday, thousandsofpapers aredevotedto theextremevaluetheory.
Many
excellent booksgivesystematic treatments. Seee.g. [7], [64], [65], [52], [33], [34], [26], [73].
^Say with
T
<
3000, and typical number of regressors,5—10
and higher.Because
the principles (i)and
(ii) constructively exploit that the relevant data isformed
by the tail events and, oris scarce, they lead toa. asymptotic distributions that either fit the finite-sample distributions better or are
more
parsimonious than the conventional approximations,b.
important
tailinferences, basedon
the extremal regression quantiles.In evaluatingthese concepts, it is
important
to keep inmind
that these alternative sequences are designedto yield better approximations ingiven practicalproblems
with givensample
sizes,evenwhen
the quantile indexis not very low.And,
incase(a), it iscompletely irrelevant
whether
or notfuturesampling
will lead tosamples
conforming
tothese sequences or not.
The
concepts (i)and
(ii) are wellmotivated
by
theintellectualand
practical success oftheextreme
value theory,which
focusedon
theordinarysample
quantiles.The
con-cepts are also similar in spirittoother "alternative" asymptotics, e.g.,GMM
when
thenumber
ofmoment
conditionsislarge;weak
instrumentstheory,where
theinstrumentsare
weakly
correlatedwith the regressors; near-to-unit root theory; and, generally, the theory ofstatistical experiments.The
organizationand
contribution ofthispaper
is eis follows:1. Section 2
demonstrates
the relevanceoftheproblem
ineconomic
analysis.2. Section 3 introduces the principles ofextremality for the regression quantiles
-namely
that ofthe intermediateand extreme rank
sequences.3. Section 4 develops the
models
oftheextremal (low) conditional quantiles.They
coherently
combine
the linear functional forms with the extreme-value-theoreticre-strictions,
and
lead to non-degenerate,parsimonious
limit distributions.The
models
are distribution-free
and
flexible, allowingfor sophisticatedeffects ofcovariateson
theshape
oftheconditional distribution (the scale, kurtosis, skewness, etc.). Importantly, thesemodels
do not admitreductions to theclassicalone-sample
case (byremoving
the conditionalmean
and/or
scale).4.
Within
the formulated models, section 5 provides theasymptotic
limit theory for thesample
regression quantilesunder
theextreme rank
condition,tT
—
) fc>
0.^The
Hmit
is drivenby
a stochastic integral ofa "residual" function with respect to a Poisson pointprocess.5. Section6, using additionaltailrestrictions, providesthe
asymptotic
distributions of regression quantilesunder
the intermediaterank
condition,tT
—
>oo,r
-^ 0.The
limit is normal, with variance parsimoniously
determined
by
the tail indices. This enables a very practical inference. (In contrast, the conventional theory requires thenonparametric
estimatesofthe conditionaldensity functionsevaluated at the extremal quantiles). This provides aregressionanalogue
offairly recent results ofDekkers and
de Haan[21].
^This paper is not about t
=
0, the linear programming estimator (also called 'extremeregres-sion quantile'), considered in Feigin and Resnick[29], Portnoy and Jureckova[60], Chernozhukov[12],
Knight[47] within thelocation-shiftmodel(Covariatesonlyaffectthe locationbut not thescale,shape ortailofthe conditionaldistribution.) Theestimator, definedas
max
A''/3s.t. Yt<
Xtf),Vtand useful as aboundaryestimate, can't be used at all in the present context.We
look atdifferent estimators (high and lowregression quantiles) that have verydifferent asymptoticsand applications[t>
(Tisfinite); seeexamples 2.1-2.4,where thesupport is unbounded or "boundaries" depend on unobserved
6.
We
concludeby
discussingan
inference theoryand an
empiricalpaper
[15].Also relevant are the
works
of Smith[73], Tsay[75],and
references therein,who
develop themodels
of exceedances over high constant thresholds.The
parametric likelihoodof thePareto family is usedtodescribesuch data,and parameters
aremade
dependent on
regressors. It shouldbe
clear that the goals, models,and
methods
of this paper are quite different.Our
analysis should beviewed
ascomplementing
the studyofthe central rank regression quantiles, with the motivationstemming
from
thewide
use ofquantile regression in data analysis in econometricsand
statistics.2
Econometric
Applications
Quantileregression is a popular tool ineconometric applications. See
Abadie
et al.[l],Buchinsky[9], Chamberlain[ll],
Poterba
and
Rubin[61],and
thereviewofKoenker and
Hallock[50].
Our
results can beuseful inabout
any
such application,sinceourfocusisthe inference
about
highand
low conditional quantiles (say .7and
higherand
.3and
lower, in a typical data-set), recognizing the extremality
and/or
scarcity ofthe tailevents.
Important
inferencesabout
the tail shapes canbe
made
as well.There
aremany
examples,where
high or low quantiles are of particular interest. For example, Abreveya[2]and Koenker and
Hallock[50] characterize theeconomic
determinants of babies' verylow birth-weightsthrough
thenear-extremeconditional quantiles (.05and
below). Deaton[20]examines
food expenditure ofPakistanihouseholdsby
the.1-thand
.9 -th conditional quantiles.
The
following presents abriefdiscussion ofsome
others.Example
2.1(Determinants
of
Generalized
{S,s)Models.)
The
(5,s) theory is widely used in the firm-levelmicroeconomic
studies, including the analysis of durablegood
inventories,employment
shortages,and
investment in capitalgoods.Lumpiness
ofadjustments, amain
prediction, is welldocumented.
E.g.,Arrow
et al. [5], Scarf[71],Rust
and
Hall[37], Aguirregabiria[3], Caballero [10].Inthe (5,s) theory,afirm allowsastate variable Vj (capital stock,inventory) tofall
until itreaches a lower barrier, s{Xt), at
which
point the stock is replenished (jumps) toan
upper
barrier, S{Xt).Such
decisions are optimal in general settings (Halland
Rust[38]).
Xt
may
include pricesand
other variables that affect the firm's beliefsabout
future salesand
costs (e.g. industrial productionand
commodity
price indices, interest rates).Assume
that {Yt,Xt) areobserved for a cross-section offirms.Absent
unobserved
heterogeneity, s{Xt)and S{Xt)
are exactly theminimal and
maximal
con-ditionalquantiles ofYt, given A''^. Otherwise, s{Xt)and S{Xt)
arestill strongly related to the extremalconditional quantiles.To
address the unobserved heterogeneity, Caballeroand
Engel[10] introduce the stochastic barriers [s{Xt)—
Vt,S{Xt)+
et] withunobserved
time-and
firm- specificrandom
components
et,Vi.They
propose probabilisticadjustment
models
(hazardfunctions) to describethe evolutionofYt across firms
and
or times. Insuch models, the highand
low conditional quantiles also describe the probabilistic rules. For example, the inventory variable Yt isbelow
the .1-th conditional quantileonly with probability10%,
given A'(. Inferenceabout
such functions is exactly our area of focus.More
generally,
we
canmap
quantile functions intohazard
functions,and
vice-versa.de-Figure 1: (S,s) model with stochastic bands [s(.Y)
—
v,S{x)+
e], where &and
v are the unobserved firmand timespecificrandom
components. Panel (A):Data
on asinglefirmmay
be generated by discrete sampling from the time path of (Yi,Xt). E.g. Rustand
Hall[37].Panel (B);
Data
{Yi,Xi)may
be generatedasa cross-section of plants. E.g. [3],[10],terminants ofthe {S{x),s{x)) functions. Specifically,
suppose
that[s{Xt)-vt,S(Xt)
+
et]constitute the
adjustment
barriers, with Vt,et>
0,s(A'j)<
S{Xt)
a.s., so that the interval is non-empty.The
timingis continuous. IfYj hits the lowerbound
s{Xt) —Vt,it is adjusted to the
upper
bound
S{Xt)
+
et- Pairs {Yt,Xt) are the observeddraws
of different firms (or apanel, stationarity assumed). For brevity, let's focuson
s{X).Suppose
Vtand
et areindependent
ofXt,^ then for c>
0:P{Yt
<
s{Xt)-
c\Xt)=
EPiXt
-
s{Xt)< -c\Xt,c<
Vt)P(c
<
vt)+
EP{Yt
-
s{Xt)< -c\Xt,c>
Vt)P{c
>
Vt).By
constructionP{Yt
—
s{Xt)<
—c\Xt,c
>
vt)=
0. Additionally,impose
thefollowingtail
homogeneity
condition: for all c>
sufficiently closeto Uj:^PiYt
-
s{Xt)<
-c\Xt,c<
Vt)=
a{vt-
c). (2.1)Thinking
ofYt—
[s{Xt)—
vt] as a positive "duration" variable, (2.1) statesan
"ac-celerated failure time"model
for the tail (which ismore
generalthan
in [10]). (2.1)imposes
no
restrictionson
the central features of the conditional distribution of Yt,which
is reasonable, since the (5, s) theory does not relate the central features to the adjustment barriers. Forexample,
thesymmetry
or homoscedasticityassumptions
are unreasonable. This implies that for—
c lowenough
and
some
low
constant (p{c)P{Yt
-
siXt)<
-c\Xt)=
(Pic),or, equivalently, that for small r
>
QY,{r\Xt
=
x)=
s{x)-
c{t)This isreasonable, since S{X),s(x) incorporate thebarriercomponentthat depends on X.
Nev-ertheless, wecan allow e,vto bedependent on A'.
A
noteisavailableupon request.istheT-th conditional quantile ofYt given Xt- Therefore,s{x) equalsthelow (extremal) conditional quantiles
up
toan
additive constant. Notably, it isnotpossible toestimate s(x) offthe central features ofthe conditional distribution ofYt-, as discussed above.The
inferenceabout
Qy{t\X)
for low values of r is exactly our area of focus.The
analyticalexamples
ofRust and
Hall suggest that linear/polynomial functions are excellent descriptions of(s(x),5(x)) functions.Example
2.2 (TailAnalysis
inRegression
Models)
The
tailshape
(index) ofthe conditional distributionisimportant
inthe regression analysis. Forexample, the thick-tailed distributions favor theLAD
and
other estimatorsmore
than
theOLS.
Thus,
knowing
the tail index helps determine betterestimators.On
the otherhand, the tailshapes are
important
in describing the large insurance claims ([26]), the analysis ofthe long
and
shortterm
survivaland
durations ([49], [42]),and
financial data (e.g.Mandelbrot[54], Fama[28],
Kearns
and
Pagan[45], Danielssonand
de Vries[17]). In the non-regression setting, the tail index estimators of Hilland
Pickandshave
been
countlessly used in the empiricalanalysis.
However,
estimation ofthetail index in the presence of the shape heteroscedasticity (scale, skewness, kurtosis,and
other forms) islargely
an
open, difficult problem.Our
results allowone
to construct the regression analogs ofthe Pickandsand
Hill tail indexestimators, basedon
theextremalregression quantiles,which
specifically adapt tothe shape-heteroscedastic setting,and
are simple in practice. Section 7 off'ers adiscussion,and
[15] providesan
empirical application.Example
2.3(Decision
Making
under
Extreme
Uncertainty)
Risk is a keysubject ofnon-financial
and
financial decisions, insurance,and
regulation.Both
the firmsand
the regulators are seriously concernedabout extreme
risks- the tail events that canwipe
out capital, hinderingliquidity or solvency.An
important
branch
ofeconomics
literatureis devotedtosafety-first decisionmak-ing. See Roy[68], Telser[74], Pyle
and
Turnovsky[63], Bertail et al[8]and
others. In this approach, the decision-makers (firms, investors, regulators) solveeither:1.
max
z, or 2.max
/^(q),where
If (a) is therandom
payoff (e.g. private or public benefitsand
profits) to the decisiona
(technology, portfolio composition, buffer stocks, quality/quantity offood control); z is the safetymargin
or disaster level of the payoff; r is the probability of the disaster or of exceeding the margin, set tobe
small; fi is themean
of ^''((q);(5y,(a)(T|Xi) is the conditional r-th quantilefunction ofYt{a) given .Y(, the vector of variablesrepresentingthe currentstate. QYt(a)iT\Xt)
<
i is the conditional (extremal) quantile constraint,requiring the disaster probability tobe
small:P{Yt{a)
<
z\Xt)<
T. This presents a
problem
of inference concerning the conditionalextremal quantiles.Our
models
are flexible (central features ofthe distributiondo
not determine the tailfeatures)
and
specifically exploit the extremalityand
scarcity ofthe tail events. InChernozhukov
and
Umantsev
[15],we
apply the present results.Safety-first decisions are very
important
in the finance industry,where
quantiles (value-at-risk) are the requiredmeasures
ofthe high level infrequent risk, used to de-termine the capital requirementsand
other externaland
internal purposes. See [25],[56], [27], [35],
among
others, for asample
ofilluminating research as well as reviews.1%
or5%
of the time (.01-thand
.05-th quantiles). Again, this isaproblem
concerningthe conditional extremal quantiles.
Example
2.4(Simple
Robust
Inference
inBoundary-Dependent Models)
Parametric
boundary dependent
likelihoods, arising in themodels
ofjob searchand
auctions (see [16], [31], [23], [41], [36] for a
sample
ofremarkable works) take the form:L{Pn)
-
^in/(y<|A-,,7,/^)
• l(lt>
x[p),t
where
/(A','/3|.Y(,7,^)>
a.s.and
is finite. /?and
7
are theboundary and shape
parameters, respectively. Linearity ofthe
boundary
is not essential (seebelow). Likelihood procedures, e.g.ML,
estimate7
and
/? jointly.The
estimates$
are characterizedby
d
=
dim(A') constraints, Yt=
X[p,
where
Yt isamong
the extremal values ofYt, [23] and[41]. For example,mini^TYt
is theboundary
estimatein the no-regressor case. Therefore,having afew
outlierobservationsY°
(such thatY°
<
X[(i,) severely biasesand
rendersinconsistenttheestimatesofboth
P
and
7.The
outliersarise as misrecordingsofthe bidwith a lowprobability (notthe usual additivemeasurement
error) or bid mistakes. Bajari[6] offers a substantive analysis, suggesting outliers are responsiblefor drasticoverestimatesofthe
mark-ups
inprominent
auction studies.Suppose
thenumber
ofoutliersY°
isbounded
by
a constantK
,independent
ofT.Consider the r-th near-extreme regression quantile estimator x'/3(t) ofthe
boundary
x'P, with quantileindex r
= M/T,
M
~
InT. Asymptotically xi-> x'/?(r) passesabove
the outliers,
and
isT/
InT-rate-consistent. Substitute ^(t) intoL{P,^) and
estimate7
viaML.
The
resulting estimator of7
is efficient.Chernozhukov
and
Hong[14] offer an analysis.Although
we
focuson
thelinear boundaries, anon-linear extensionin thismodel
is straightforward. Regardlessly, the linearforms
include thepolynomial
and
piece-wise linear specifications,
approximating
thesmooth
parametricfunctions as wellas
we
like.3
Extremal
Quantiles
and
Rank
Sequences
This section defines the linear regression model, the
sample
regression quantiles, theextreme
and
intermediaterank
concepts forthese statistics,and
thetail types.3.1
Extremal
Conditional Quantiles
Suppose
Yt is the response variable in K,and Xt
are the conditioning variables inK^
.The
r-th conditional quantile functionQy{t\x)
is a function q{x) that satisfiesthe relationship
P{Y
<
q{X)\X)
=
r. For instance, (5y(.25|a:)and
Qy(.l|x) are the conditionalfirst quartileand
decile functions. Formally,Qy{T\x)=Fy\T\x),
where
Fy'(|x)
is the inverse of Fy-(|i).Our
focus is exclusivelyon
modeling
and
making
inferenceon
the extremal conditional quantile functions:Qy(t\x),
where r
is near 0.3.2
Linear Quantile
Regression
Model
In this paper
we
considerthe hnearmodel
for quantiles of interestI
Qy{T\x)=F-'{T\x)=x'^[T),
Vt€I,
(3.2)where
/?() isan
unknown
functionofr.Here
it is necessary that (3.2) holds for1=
[0,77],where??
>
0. (3.3)If T] is small, the linearity is
assumed
only for low quantiles,and
not necessarily for other quantiles.We
cissume thatX
has (oristrimmed
to) acompact
supportX.
The
model
(3.2)is implied, forinstance,by
theclassicallinear location-scalemodels
with
unknown
error distribution, butis considerablymore
flexible in thesensethattheshapeoftheconditional density
may
change
with the covariates.X
may
incorporate awide
array ofpolynomialand
other transformationsoftheobserved covariates.On
itsbasis, in section4,
we
develop themodels
with the extreme-value-theoretic restrictionson
the conditionaltails.Note
the approachestolinearmodeling.One
approach
assumes
linearityofasingle orfew quantiles (Buchinsky[9], Horowitz[43], Powell[62]).Another approach (Koenker
and Machado[51]) assumes
the linearity ofall quantile functions,I
=
[0, 1].The
"local inr
linearity"assumption
made
here is closer to thefirst approach.Despite convenience, having linearity for several r
may
posean
avoidable caveat (the curvesmay
cross). First,X
is often a transformation ofthe original covariates, sothe curvesare non-linearin theoriginalspace (see [49]). Second, givencompactness
of support
X,
the linearmodel
is always coherent.Take
a countable, possibly finite collection of non-crossing curves {x h^ x'P{Ti),iG J}
withdomain
X.
Definex
>-->x'/3(t) for other r
by
taking appropriateconvex
or linear combinations ofthese lines.By
construction, thefines crossonly outsideX.
This alsodefines theconditional c.d.f.3.3
Sample
Regression Quantile
Statistics
Suppose
we
have
T
observations {Yt,Xt}. In the no-covariates case thesample
r-th quantile P{t), is generatedby
solving theproblem
t=l
where
Pt{x)=
{t—
1{x<
0)) x.Koenker
and
Bassett[48]extended
theconcept tothe regression setting by solvingT
min
TpriVt-X^li).
(3.4)The
/?(r) that solves (3.4) has the equivarianceand
robustness properties oftheordi-nary sample
quantiles; inparticular, (i) regressionequivariance,(ii) scaleequivariance,(iii) equivarianceto (fullrank) lineartransformationsof
X,
(iv) invariancetopertur-bations ofy^t without crossingthe
hyperplane
x'${t).The
solutions x'${t) to (3.4) (if3.4
Extremes,
Near-Extremes
&
Data
Scarcity
We
view
thesample
regression quantiles as order statistics in regression settings. For a givensample
ofsize T, the r-thsample
regression quantile is seen here as therT-th
order statistic. Henceforth,
we
shall refertotT
as to the rankor order.Definition
3.1(Rank
Conditions)
The
sequenceofquantileindex-samplesizepairs {tt,T) is said to be:(i)
an extreme
rank sequence, ift-j-\
0,TtT
—
> A;>
0, (ii)an
intermediaterank
sequence, ifTt\
0,TrT
—
> oo,(ii) a central
rank
sequence, ifr is fixed,and
T
—
^ oo.Even
though
(i)and
(ii)make
rsample
size dependent, to simplifywe
write r instead of Tt-Because
principles (i)and
(ii) constructively exploit that the relevant data isformed
by the tailevents and, oris scarce, they lead toa. asymptotic distributions that either fit the finite-sample distribution better or, giA'en the
same
approximation
quality, aremore
parsimonious
relative to the conventionalcentralrank approximations (Koenker and
Bassett[48], Powell[62]) b. important tail inference procedures,based
on
thesample
regression quantiles.See
example
2.3and
section 7.Concepts
(i)and
(ii) are wellmotivated by
the intellectualand
practical success ofextreme
value theory,which
focusedon
the ordinarysample
quantiles.These
con-cepts are also similar in spirit to other types of "alternative" asymptotics, e.g.GMM
when
thenumber
ofmoment
conditions is large, or, generally, thetheory ofstatisticalexperiments.
In evaluating these concepts,it is
important
tokeep
inmind
that thesealternative sequencesare designedto yield practically betterapproximations
evenwhen
thequan-tileindex is not verylow.
And,
in case (a), it is completely irrelevantwhether
ornot futuresampling
will lead tosamples
conforming
tothese sequences.To
clarify (a), consider a simpleexample
withno
X.
Suppose, withan
i.i.d.sample
{Ut,t<
T =
200},we
wish to inferabout
the quantiles with indices r=
.025, r=
.1, r=
.2,r
=
.3.The
estimators are the order statistics (sample quantiles) [^(5),t/(20); t^(40)7 f^(60)-Suppose
the distribution F^. hasan
algebraic tailF^{x)
~
(—
a;)~^/^,^=
1 aisX
\
—00.
Figure 5compares
the conventional centralrank approximation
VT
{U^rT)-
F~^{t))-^
N
(0,r(l-
t)/f^{Fu(t))) , where fu=
F^,with the intermediate
rank
one: ariU^^r)—
F~^{t))—
>N{0,^^/{m~^
-
1)^),(4=
—
l,m
>
1), ot=
VrT/F'^irriT)—
F~^(t)),and
theextreme rank
approximation:T^^'^{U(rT)
—
F~^{t))—
> -fc~'/^—
r^'^^,where
Tk is agamma
random
variable with degree k(sum
ofk standard exponentials, section 3.6).Quality-wise, the extreme rank approximation,
which
exploits both the extremalityand
scarcity oftailevents, beatsthenormal
quiteconsiderably (displays A-C).Only
for a fairlynon-extreme
quantile, r=
.3, does thenormal approximation
achieve roughlythe
same
quality.At
thesame
time, the intermediate rank approximation,which
ex-ploits the extremalityofrelevant events, is very closetothecentralrank approximation
(displays D-F), but enjoys greater
parsimony
and
easeof inference.The
tail index^ is(seesection3.6). This
may
be preferred tothenonparametric
estimationof the density function evaluated at the low quantile (with the scarce tail data), as required in the central ranktheory. See [13] for aMonte-Carlo
regression example.3.5
Tail
Types,
Support
Types,
and
Classical
Limits
The
following definitions areimportant
in thesequel.Definition
3.2(Types
of
Support)
In viewoflinearity,we
say Fy{-\X) has:• finitesupport, if
Qy{0\X)
> —
oo,a.s.• infinite support, if
Qy{0\X)
=
—
oo, a.s.Definition
3.3 (TailTypes,
TailIndex,
Regular
variation)
Consider arandom
variable
U
with distribution function F^, with lower end-point Xf equal or—
oo.F^
hasthe tail of the extremal types 1, 2, or 3iffor [/
~
^ iff/g
—
> !]typel:(^
=
0)
: as «\
or-
oo, F„(f-|- x£(<))~
Fu(i)e"^,Vx
£ K, type 2: (^=
-)
:a.st\
-oo,
x'^Fuit)
~
Fu{tx),Vx
>
0,a
>
0, (35)type 3; (^
=
—
) : asi\
0,x"
Fu{t)~
F^itx),Vx
>
0,a
>
0.a
where
i{t)=
J
Fu{v)dv/Fu{t), fort>
x/, cf. [52].Enclosed
inthe brackets in (3.5)is the tail index(,,
which
determines thetail type.Equation
(3.5) defines type 2 distributions as regularly varying functions at-co
with index—1/^
=
—a,
(algebraicallyand
near- algebraically tailed at —00, inmore
intuitive terms). (3.5) also defines type 3 distributions as regularly varying functions at with index
—
1/^=
a
>
(algebraicallyand
near- algebraically tailed at a finiteend
point, takenas 0).The
type 1 classincludesexponentiallyand
near-exponentially taileddistributions. Forfuture reference, note these conditionsimply
thatthe quantile functionF^^{t)
is regularly varying at with index —(,. E.g. [26].Classes 1-3 contain
most
ofsmooth
distributions with rare exceptions. See [26].The
tail types determine the limiting distributions of order statisticsunder
extreme
and
intermediate ranks. In our setting, they willhave
asimilar role as well. Forlater comparisons, let us review the non-regression results.3.6
Limit
Distributions of
Ordinary
Sample
Quantiles
Extreme
Rank
Statistics. Consider the order statistics f/(i)<
...<
[/(jt)from
thei.i.d.
sample
Ui,...,Ut, distributed according to law Fu, with the lower end-point x/equal or —00.
The
extreme
value theory described the existenceand forms
of the non-degeneratelimitlaws for the properly normalized orderstatistics:A.tau=.025,T=200, rank=5 B.tau=.2,1=200, rank=40 C.tau=.3,T=200, rank=60 o /' O / o
^'-/
o to/
/ / o o/
• -100 -60 -20 20 -0.5 0.0 0.5D.tau=.1,T=200, rank=20 E.tau=.2,T=200,rank=40 F.tau=.3,T=200,
rank=60
-3
-10
12
3 -0.5 0.0 0.5Figure 2: Displays
A-C: QQ-plot
ofExtreme
and
Central
Rank
Approximations.
The
dashedline "- - -"isthecentralapproximation, andthe dottedline " " istheextreme
rankapproximation.
The
true quantilesofthe exactsamplingdistributionaredepictedbythe solidline" ".
The
centralrankapproximationvariesfromverybadtobad
forlowquantilesT
=
.025 and r=
.2 and becomes comparable to the extreme rank approximation only at T=
.3. DisplaysD-F: QQ-plot
ofIntermediate
and
Central
Rank
Approximations.
The
dotted line " "now
denotes the intermediate rank approximation.The
theoreticalcentral andintermediate rankapproximations have approximatelythe
same
performance forT
=
.1,.2,.3, (usingm
—
2,1.5,1.25).The
practical advantage of the intermediate rankapproximation is the parsimony
and
eaise ofestimating nuisance parameters. [Replications=
10,000.99%
range.]For fixed k, thelimit laws oftype 1- 3, wereidentiiied in the literature as:
InTk, for type 1 tails,
Jfc
=
<—
r,.", for type 2 tails,for type 3 tails,
(3.6)
k '
with the canonical scalings given by:
type 1: ar type2: aj-type3: ar
lli[F-'{^)l
bj-yF-'ir)
' 6^=
0, b-r=
0. (3.7)Note
thatwhen
k=
I, thetype 1 lawin (3.6) iscalledGumbell,
type2- Frechet,type 3- Weibull. Typically, the results statethedistributionfunctions ofJk,
but
more
recent treatments formulate the results in theabove
form
(e.g.Example
4.2.5 in [26]),which
helps explain our results.
Intermediate
Rank
Statistics.One
ofmost
generaland
fairly recenttreatmentsoftheintermediate orderstatisticsisthe
work
ofDekkers
and
de Haan[21].Using
slightly stronger restrictions on the tails, discussed below, theyfound
that the limit laws are normal, but the limiting variance dependson
the extremal tail typesthrough
the tailindex ^, as A;
=
[tT] -^ oo(Theorem
3.1):/tT
Fu'{2t)-F-\t)
[/,(IrT}} F,\:\r))
N
0,e
(2-«-l)2
(3.8)The
scalinga-p can convenientlybe
replacedby
VtT/{U^2[tT])~
U^^rT]) without affect-ing the result,and
operationalizing the inference.4
The
Extremal
Regression Quantile
Models
Here
we
construct thelinearmodels
oflow (extremal)conditional quantiles,which
allow flexiblecovariateeffectson
thedistribution,and
coherentlycombine
thetailconditions leading to (i) non-degenerate asymptotic distributionsand
congenial inference proce-dures, (ii)good
approximations to thesampling
distributions,and
(iii) aframework
suitablefor inference
about
tails in shape-heteroscedasticmodels.4.1
Model
1:Tail
Homogeneity
Consider aprobabilityspace(fJ,
T,
P),possiblyindexedby
T.To
impose
aconstructivetail condition, define a reference error
term
asU = Y
-X'Pr,
(4.9)where
x i-> x'l3r is the reference line chosenso thatthe errorU
satisfiesthetailhomo-geneity condition (i) in
assumption
1.The
existence ofsuch a lineisan
assumption; theexamples below
highlight its constructive role.Inthe
bounded
support case, it is convenient to choose the referenceHne
asPr
=
,5(0), (4.10)sothat [/
=
y
—
X'P{0)
>
has the end-pointby
construction. (In theunbounded
support case, x'P{0)
=
—
ooand
is not suitable as areference line).Assumption
1(Model
1: TailHomogeneity)
In addition to linearity (3.2):(i) thereis areal-valued
U
and
referenceline x'Pr oftheform
(4.9)-(4.10)s.t.asz
\
—
oo (infinite support) or as z\
(finite support), uniformlyinx
€X.
Fu
is adistribution function with type 1,2, or3 tails.(ii) the support of
X
is (ortrimmed
to) acompact
subsetX
ofIR'*.(Hi) the distribution function
ofXt,
Fx
, with supportX
and
mean
px,
isnondegen-eratein W^.
The
firstcomponent
ofX
is 1.px
=
(1,0,...) w.l.o.g.Assumption
l-(ii), compactness, is essential; otherwise, thelimitsmay
change
de-pending on
the tail behaviorofX
. l-(iii) precludes non-degeneracies.Assumption
l-(i) requiresthetailsofthesuitablydefined errorterm
U
tobe
inthedomain
oftheminimum
attractionwhich
is fairlybroad
with rareexceptions (section3.5.) In this sense the
model
is distribution-free. l-(i) also requires the tail of the conditional distribution function ofU
tobe approximately independent
ofX.
This incorporates the case ofindependent
U
and
X
as strictly aspecial case. Indeed, l-(i)requires only that there is a reference error
U
in (4.9) such that the extremal (small) values of[/areapproximatelyindependent
ofA'. Thisallowsgeneralglobaldependence
of
U
on
X
, such asshape
heteroscedasticity.Example
4.1 (Classical linearmodel)
Suppose
the quantilefunction isQAr\X)=X'a-i-F~\T),
(4.11)which
corresponds to themodel
Y
=
X'a
-\-U, where
U
isindependent
ofX
and
e.g.EU
=
0. This clearly is a special case ofModel
1 with the reference linex'a. Yet thisexample
isnarrow and
"trivial" inthe sense that the extremalfeaturesaredetermined
by
the centralfeatures ofthe distribution,and
thereis "nothing toestimate" (allslope coefficients ^_i(r) equal a_i.)To
defend the "trivial" model, note it underliesmuch
ofthe (central) quantile regression inference,Koenker
and
Bassett[48],because
itoften plausiblyapproximates
the exact distribution ofregression quantiles, eventhough
themodel
itselfis unrealistic(Koenker
and
Hallock[50]).Example
4.2 Consider thebounded
support case.The
0-th quantile function isQy{0\X)
=
X'j3{0),which
is ourreference line X'(3r.By
assumption
l(i),P(Y
-
X'/?(0)<
l\X)~
Fu{l)=
Ti,asl\0,
which
implies that the paths of the extremal quantile functionsx
h^ x'P{ri) are ap-proximately parallel to that of a; i-> x'/3(0). Thismodel
is not "trivial" in the senseof
Example
4.1, because the extremal quantilesand
the reference line are determined only by the extremal features ofthe conditional distribution.The
model
does not re-strict other quantiles, allowing for general shape- heteroscedasticity. For example, a collection of quantilecurves {x !-> Qyiqlx),<? £C}
with the centralindicesC
may
have
complicated non-parallel paths, allowing for complicated effects of covariates
on
the conditional densityshape
(kurtosis, skewness,and
other effects), as in Figure 3.Con-sequently, this
model
does notadmit
reductions to non-regressionmodels
byremoving
a conditional location
and
scalefrom
Y.Quantiles ..••6C(3/^|x) "~
--
l^--^—
-^
'^
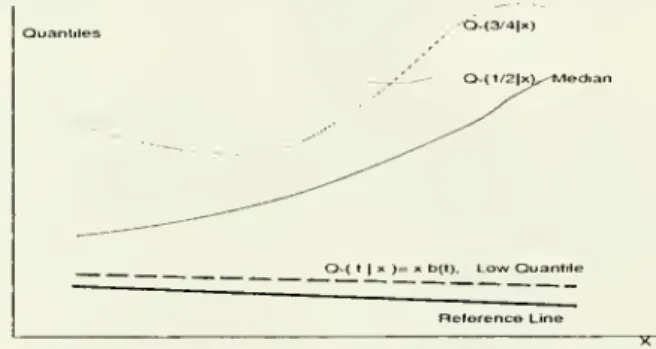
0,(11X )= X b(t). LowOuanttle ReferenceLineFigure3:
Example
4.2: Extremalconditional quantilefunctionxi->x P{t) is approximately paralleltothereference linex >->x pr (equal tothemini-m£ilquantilex'P{0)in the
bounded
supportcase). Otherquantilefunctions are unrestricted, allowing for complicated forms ofglobalheteroscedastic-ity.
The
model does not admit the reduction to a non-regression model by removing the conditionalmedian
(ormean)
and/or scale fromY
variable.Example
4.3 Consider theunbounded
support. Forsome
referencelinex i->x'pr,by
assumption
l(i),P{Y
-
X'pr
<
l\X)~
Fu{l)=
Ti,a.sl\
-DO,which
implies that the paths of the extremal quantile functionsx
M- x'I3{ti) are ap-proximately parallel to that oix
i-^ x'Pr- Thismodel
is also not "trivial" in thesense ofexample
4.1, because the extremal quantiles aredetermined
onlyby
the extremal features ofthe conditional distribution.As
inexample
4.2, themodel
does notrestrictany
other features ofthedistribution,allowingforgeneralforms
of globalheteroscedcis-ticity.
Thus
it is irreducible to a non-regression model.Note
thatexamples
4.2and
4.3demonstrate
that the linear location-scalemodels
are neither implied
by
Model
1 nor implyModel
1.Thus Model
1 is ofitsown
nature, crafted to yield non-degenerate,parsimonious limits. Unlike thelocation-scalemodels,Model
1admitsgeneral global heteroscedasticity,allowingcovariatestoaffecttheshape
ofthe conditional distribution.
4.2
Model
2:Congenial
Tail
Heterogeneity
We
suggest amodel
that, while flexibly accounting for thedependence
ofthe tailon
covariates, exhibits simplicity, enabling an explicit, practical limit theory for
both
theextreme
and
intermediate ranksample
regression quantiles. 13Assumption
2
(Model
2:Congenial
TailHetrogeneity)
Suppose assumption
1holds, except l-(i) is replaced
by
the followingtail condition:Fy{z\x)
~
K{x)
Fu{z),asz\-ooorz\0,
(4.12)uniformlyin
x
£X,
Fy, has type 1-3 tails, K{-) isassumed
to be apositive continuous function onX, bounded
above
and
away
from
zero,normalized
so thatK{fix)
=
1 (or atany
otherreferencepoint x^ 6 X).Just like
Model
1,Model
2 is distribution-free, sinceF^
is notassumed
tobe
para-metric,
and
it allows the general (shape) forms of global heteroscedasticity. UnlikeModel
1,Model
2 allows for richer effects ofcovariateson
tails.The
imposed
tail conditionmay
seem
an
unconventionalway
to introduce het-eroscedasticity. Yet, inmany
regards, itismore
flexibleand
constructivethan
the con-ventional location-scalemodeling,asexplained below.The
proposed
modeling
strategyis
motivated by
the closure of thedomains
ofminimum
attractionunder
tail equiva-lence,and
is fully consistent withlinearity.Indeed,
Lemma
10,characterizes thismodel
in detail: (i) implicationsforthequan-tile coefficients ofthe linear model, (ii) limits of ratios ofspacings
between
the con-ditional quantile functions,and
(iii)many
other propertiesneeded
for inference.Im-portantly,
we
deduced
that the linearityassumption
and
(4.12)jointlyimply
that A'(-) canbe
represented as{e~^
"^ for type 1 tails,{x'c)°' for type 2 tails, (4.13) {x'c)~°' for type 3 tails,
where
fi'^c=
1 for type 2and
3 tails,and
/z'^c=
for type 1 tails. InModel
1,c
=
for type 1 tails,and
c=
(1,0,...)'=
e'j for type 2and
3 tails.We
call c thetailheterogeneity index. It
measures
the strength withwhich
X
shift the tails of error terms U.Note
that x'c>
uniformlyon
X
fortypes 2and
3by
assumption.It is plausible that (potentially) the non-parametric function K{-) in (4.12) is in fact a transformation ofthe linear index x'c
determined by
the tail index ^. Recall(,
=
(for type 1 tails)and
£,=
1/a
and
—
1/q
fortype 2and
3 tails,respectively. Thisassumption
leads to parsimonious, convenientlimits for regression quantiles.The
followingexamples
illustrate the model's flexibility.Example
4.4(Linear
Location-Scale
Model)
Assume
forX'j
>
a.s.Qy(r|x)
=
x'Q+
x'7-F-'(r),
(4.14) corresponding to the locationmodel
Y
=
X'a
-\-X'-yV, where
V
isindependent
ofA'^ and, say, has
mean
and
variance 1.Assume
F^
has the extremal tail type with ^^
0.Then
forthe reference linex'aand
U =
Y
—
X'a
=
X'-y-V
P{X'-f
V
<
l\X)~
(X'7)-^/^ -F^il), as /\
-co,
so the conditions of
Model
1 are satisfied withF^
=
Fy.The
location-scalemodel
imposes two
stringent restrictions: (i) the extremal features of the distribution arelargely
determined
by
the (central)locationand
scaleparameters: /3(t)=
a+7-F~^
(r),and
(ii) thecovariatesare limited toaffectonly the locationand
scaleofthe conditional distribution, precluding theshape
effects likeskewness
or kurtosis.Example
4.5Model
2 requires that forsome
reference line x'/J^P{Y
-
X'pr
<
l\X)~
K{x)
Fu{l), as/\
or-
cx),which
implies that the paths of the extremal quantile functionsx
M- x'P{ti) areno
longer parallel to that of x h-)- x'Pr-
(The
crossing of lines is precluded because theassumption
is consistent with linearity,Lemma
10). Thismodel
is not as restrictive asexample
4.4. First, the extremal quantiles (and the reference line) aredetermined
only
by
theextremal features ofthe conditional distribution. Second, themodel
allows for general global heteroscedasticity- the entireshape
ofthe conditional densitymay
change
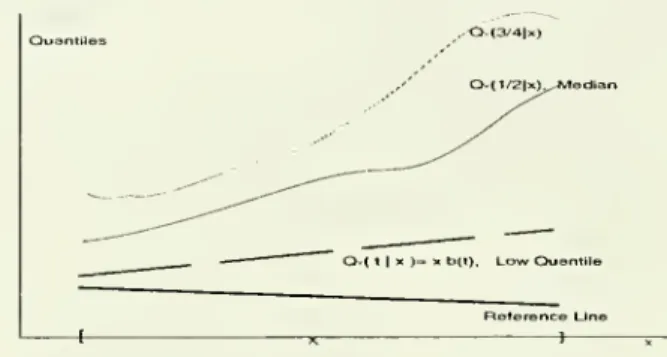
with covariates (scale, skewness, etc), including thetails.Figure 4:
Example
4.5. Extremal quantile functions x i-> x'/3{t) are no longerapproximatelyparEilleltothereferencelinex>->x'fir, over X, allow-ing the tail heteroscedasticity. Other quantile functions are unrestricted, allowing for complicated forms of global heteroscedasticity as well.The
extremalfeatures ofthemodel, including thereferencelines, arenot
deter-mined
bythecentral features.Thisdiscussion concludes the constructionofour models. In principle, itshould
be
possible to further relaxthe
modeling
assumptions, particularlyin thenonparametric
direction, but a
good
deal of caution isneeded
to assure the joint coherency of thetail conditions, functional
dependence
of the quantile curveson
regressors,and
non-degeneracy ofthe limit distributions.Note
that the obtainedmodels
are coherent, flexible,distribution-free, leadtonon-degenerate,parsimoniouslimit distributions,and
provide a convenient
framework
for inferenceabout
the tails.5
Asymptotics
under
Extreme Ranks
Recall that the
approximation
concept ofextreme
ranks requirestT —
> fc>
0.Here
we
state the distribution results forModels
1and
2and
explain their barest essence, while leaving proofsand
some
generalizations to the appendix.5.1.
A
Sketch.
First, obtain a finite-dimensional {fidi)weak
limitQco()
of the finite-sample, suitably scaled, objective functions {Qt{-)}-Qoo
is definedby
a pointprocessthat "counts" the "extremalevents."
Then,
the normalizedregression quantile statistic,Zx, an argmin
ofQt,
will convergein distribution toarandom
variable Zoo, theargmin
ofQoo,by
convexity of{Qt]
and
Qoo-For brevity,
we
confine our discussion to type 3 tails. Consider the statisticZr
=
ar{P{T)-l3{0)),
where
Ct- is the canonicalscaling in section 3.6, defined in terms ofthe function F,, inassumption
1 or 2.Zt
optimizes therescaledby
a^ objectivefunction in (3.4):T
Qt{z)
=
J2
('rPr[Ut-
X^z/a-r)-
a^rUt),
(5.15)where
Ut=
Yt-
A'j'/?(0)>
Q a.T\d z=
ar{l3-
I3r)-We
subtracted the"smoother"
X^j rUtCiT,
which
brings a key continuity propertyand
stabilizesQt-
Clearlythis does notaffect theargmin
Zr- [The"smoother"
fortype 1-2 tails ismore
involved;Lemma
1. Incidentally, theconventional central
rank
stabilizationby ^jPr(t/tar)
is bad, forit sends the objective to
+00,
let alone continuity.]Hence
T
Qt[z)
=
-TtX'z -
J2l{Utar <
X[z)
{Utar-
X'^z). (5.16)t=i
This function is convex. Notably, it is constructed as a continuous functional of the point process defined next.
The
fi-di distribution ofQt
is definedby
that of{Qt{zj),J
<
l] forany
finite (z_/,j<
/). Since A'—
>• /xx,and
tT —
> k (forj<
I) :T
Qt{zj)
=
-kn'xZj
-
^
l{UtaT
<
XtZj)[Utar
-
X[zj)+
Op(l). (5-17) t=iThe
limit behaviorofQt
is determinedby
the pointprocessN
that assignsmass
tomeasurable
setsA
by:r
N(^)
=
Y^
\{{arUt,Xt}
e A), forAcE=
[0,oo)x
X.
(=1
The
point processN
is ameasure
definedby
itsrandom
points (atoms) {aT.Ut,Xt,t<
T)
(See Definition A.l, B.l).We
find that Qt{-) isan
integralofa residual function with respect to the point process,which seems
tobe
special tothis problem.Point process theory is the bread-and-butter of
extreme
value theory,^ [26],and
isuseful here. Indeed, a Lebesgue-Stieltjes integral
f
gdN
ofN
with points{Xj}
is :j
9{x)dN{x)
=
Y^g[X,).
®Point process theorywasdevelopedbyKallenberg[44], Resnick(65] andothersinconsiderable
gen-erality. Applicationsare numerousin statistics. For example,Feigin and Resnick[29] approximatethe
constraintsofthelinearprogrammingestimators; alsoKnight[46] ;Emrechtset al.[26] andResnick[65]
show howpoint processes
may
be used inrelated applications, particularlytheexceedance processes,extremal processes,and record values.
Convergence
of such integrals, for continuousmaps
x M- g{x} that vanish outsidecompact
sets, metrizesweak
convergence of point processes (Definition A.2.)So
we
represent {Qt{zj),J
<
I) as an integralQt{zj)
=
-kn'xZj
+
[{I-
x'zj^dNil,!)
+
Op(l), (5.18)where
(/—
x'z)"" is the "residual" function.Lemma
2 proves {Qt{z),J<
l) \s a.continuous
map
of the point processN,
so itsweak
limit isdetermined
by
that ofN.
Notably, to obtain continuity for various tail types, the construction of point processN
requiresacarefulchoice oftheunderlyingtopologicalspaceE
(andadditional transformationsofQt
fortypes 1and
2).The
weak
hmit
(Def. A.2) ofN
inModel
2 is a Poisson processN,
Lemma
6: ooi=l
where
{Ji,Xi] arerandom
points defined as(j„
Xi,i>l)
^(A^'cLf
, Xi,z>l),
Vi=£i
+...+
£i, i>1,
(5.19)
where
{£i} are i.i.d. exponentialrandom
variables withmean
1, {Xi} are i.i.d. with lawFx
, distributed independently of {£i},and
c is the tail heterogeneity parameter.In
Model
1, becausec=
(1,0,...), a naturalsimplification occurs:A;'c=l,Vi.
(5.20)The
firstresult,explainedinLemma
6, isnotself-evident,while (5.20)isfairlyintuitive.Note
that N(.4)=
J2i<T ^iWTU(i),X^iy} € A),where
[/(,) is i-thrank
error,and
Xu\
isthe corresponding covariate. Vector [arU^i),!
<
q)—
> {t\''^,i<
q) (Section 3.6),and
is asymptotically independent oi
Xi
by Assumption
l-(i) inModel
1,which
explainsthe
form
of(5.19)and
(5.20) forModel
1. (This is nota proof).Lemmas
5-6 provide the proofforModel
2 (and 1by
implication) using the Kalenberg's theorem, Meyer's conditions,and
a series of compositionsand
transformations of a canonical Poisson process (Def. A.4 provides a background).We
concludethat thefidiweak
limit of{Qt}
is/CX)
(jf
-
x'z)~dN{j,x)
=
-kfjLxZ+
^(Ji
-
X[z)~
.
Therefore,
we
obtainby convexityLemma
1 intheappendix
(Theorem
5inKnight[46]) thelimit distribution forZt,
provided(5oo() has a uniqueargmin
a.s.and
is finiteon
an open non-empty
set (verified inLemma
2and
11).Hence
Or(/?(r)
-
/3(0))-^
Zoo=
argmin
Qoo(2)- (5.21)Finally,
Lemma
10shows
that ax(/3(0) -/?(r)) -> fc»c inModel
2 ( c=
ej=
(1,0,...)'in
Model
1) so thata^(4(r)-/3(r))
-k°C+
Zn
5.2.
Results
forModels
1and
2.The
above
discussion hopefully providedan
intuitive explanation ofthe foregoingformal results for
Models
1and
2(Theorems
1and
2).The
proofs areintheappendix.To
statetheresult,suppose
we
have
/sequences{Ti,i
<
1} such that t,T—
> ki, sowe
index thenormalizedregression quantile statistic as Zriki), forboth
T
<
ooand
T
=
oo. DefineZrik)
=
ar (/3(t)—
Pt—
br^i) , fortype 1 tails,Zrik)
=
ar (/3(r)-
Pr) , fortype 2&
3tails.Also define the centered statistic
Z^{k)=ar[p{r)-P{T)).
The
canonical constants {a-j-jbr) are defined in (3.7) interms
offunctions F^,which
are definedin
Assumptions
1and
2 along with the errorterm
Utand
Pr-The
key point process,N()
=
5I(<t ^{{ariUt-
6t),^Y(} € )weakly
converges (Def. A.2) toN(
)=
^i>i
l{{Ji,Xt} € •)by
Lemma
4-6, with points {Ji,Xi} defined as:(j„
Xi, i>
l)=
<(ln(rO
+
A'/c, Xi) fortype 1,(r7^/"A7c,
Xi) for type 2,i>l
(5.22) (rJ/^-Y/c, a;) fortype 3,where
{Ti,i>
1}=
{X!,<i^j'*—
1}! l^j) i^^^
i.i.d.sequence
of unit-exponential variables;{Xi}
isan
i.i.dsequence
withlaw Fx-
InModel
1, thedependence between
Ji
and
Xi naturally disappearsinview
ofassumption
l-(i):X-c
=
for type 1 tails,Vz,(5.23) -Y/c
=
1 fortype 2&
3 tails, Vi.Theorem
1(Extreme
Rank
Asymptotics
inModel
1)Suppose
Assumption
1and
that (a) {Yt,Xt} is
an
i.i.d. or stationary sequence, satisfying theMeyer
conditions,Lemma
6; (b) at leastone
component
ofX
is absolutely continuous, ifd
>
2.Then
as
tT
-^k,T
-^ oo, (k=
ki,...,ki), fora.e. k>
Zrik)
—
> Zoo{k)=
arginf—
kpi'^z+
I l{u,x'z)dN{u,x)\,
where
l{u,v)=
l(u<
v){v—
u),and
the distribution of points {Ji,Xi]
ofN
isdefined in (5.22)-(5.23). Furthermore, {ZT{ki),i<
l)-^
[Z^{ki),i<
l),Z^{k)
^
Z'^ik)=
Z^{k)
-
c{k),and
[Zj-{ki),i<
I)—
> [Z^{ki),i<
I),where
c{k)=
Ink
ei, for type 1,—k^~ei,
fortype2,