HAL Id: hal-00766255
https://hal.inria.fr/hal-00766255
Submitted on 8 Feb 2013
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of
sci-entific research documents, whether they are
pub-lished or not. The documents may come from
teaching and research institutions in France or
L’archive ouverte pluridisciplinaire HAL, est
destinée au dépôt et à la diffusion de documents
scientifiques de niveau recherche, publiés ou non,
émanant des établissements d’enseignement et de
recherche français ou étrangers, des laboratoires
Occlusion-free Camera Control for Multiple Targets
Marc Christie, Jean-Marie Normand, Patrick Olivier
To cite this version:
Marc Christie, Jean-Marie Normand, Patrick Olivier. Occlusion-free Camera Control for Multiple
Targets. ACM SIGGRAPH / Eurographics Symposium on Computer Animation, Jul 2012, Lausanne,
Switzerland. �hal-00766255�
Eurographics/ ACM SIGGRAPH Symposium on Computer Animation (2012) P. Kry and J. Lee (Editors)
Occlusion-free Camera Control for Multiple Targets
M. Christie1and J.-M. Normand2and P. Olivier3
1MIMETIC, INRIA Rennes Bretagne-Atlantique, France
2LUNAM Université, École Centrale de Nantes, CERMA UMR 1563, Nantes, France 3Culture Lab, School of Computing Science, Newcastle University, UK
Abstract
Maintaining the visibility of target objects is a fundamental problem in automatic camera control for 3D graphics applications. Practical real-time camera control algorithms generally only incorporate mechanisms for the eval-uation of the visibility of target objects from a single viewpoint, and idealize the geometric complexity of target objects. Drawing on work in soft shadow generation, we perform low resolution projections, from target objects to rapidly compute their visibility for a sample of locations around the current camera position. This computation is extended to aggregate visibility in a temporal window to improve camera stability in the face of partial and sudden onset occlusion. To capture the full spatial extent of target objects we use a stochastic approximation of their surface area. Our implementation is the first practical occlusion-free real-time camera control framework for multiple target objects. The result is a robust component that can be integrated to any virtual camera control system that requires the precise computation of visibility for multiple targets.
Categories and Subject Descriptors (according to ACM CCS): I.3.7 [Computer Graphics]: Three-Dimensional Graphics and Realism—Animation
1. Introduction
Camera control is a basic requirement for 3D computer graphics applications and in recent years a variety of tech-niques have been developed to automate camera control for tasks ranging from object inspection to assisted navigation. In most applications the aim of a camera control system is to maintain informational and aesthetic views of scene ele-ments, whilst at the same time freeing the user from having to exercise low-level control of the camera parameters.
In practice, a number of factors determine the sophisti-cation of the camera control framework required, including the nature of the user’s task, the visuospatial qualities of the graphical environment, and other application domain spe-cific constraints. Furthermore, the high dimensionality of the search space (a simple camera model has at least 7 degrees of freedom) and the intrinsic complexity of 3D environments constitute significant barriers to development of expressive real-time approaches.
An intrinsic property of any camera control system is the ability to compute and reason about the visibility of tar-get objects in dynamic environments. However, in contrast
to shadow computation and occlusion culling, the issue of visibility in camera control has received relatively little at-tention. Current real-time approaches to the computation of occlusion-free views of target objects (e.g. in computer games) rely almost exclusively on simple ray casting tech-niques.
In this paper we propose a new approach to real-time occlusion-free camera control, which addresses many of the limitations of existing approaches:
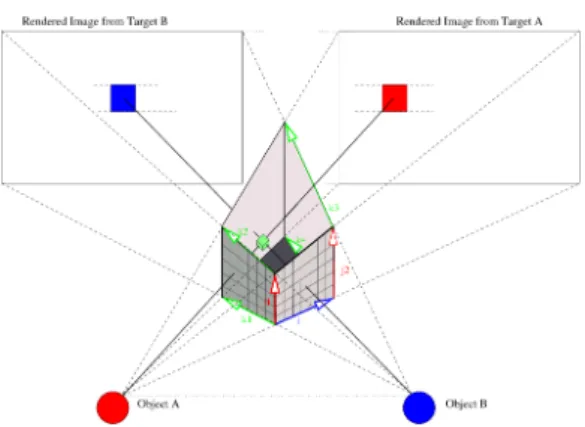
Multi-object visibility We have developed a technique that can sample the visibility of multiple targets from multiple viewpoints (see Figure1).
Stochastic estimation of visual extent We use a stochastic approximation to compute the visibility of a whole target. Dynamic qualities By accumulating visibility information over consecutive frames we implement the first quantita-tive parametrization of a camera’s dynamic behavior. 2. Visibility Methods in Camera Control
Only a small number of real-time approaches for occlusion-aware camera control have been proposed (for a
compre-M. Christie & J.-compre-M. Normand & P. Olivier / Occlusion-free Camera Control for Multiple Targets
Figure 1: Intersection of two renderings originating from
target objects A and B. In this intersection region (grey box), we compose the visibility information for both targets.
hensive survey of automated camera control see [CON08]). Crucially, existing techniques (e.g [HHS01]) cannot be eas-ily extended for multiple target objects, and fail to capture the full spatial extent of target objects (i.e. they model target objects as points). The computation of occlusion-free view-points is closely related to the well known problem of visi-bility determination [COCSD00,Dur00] which has a bearing on a range of sub-fields in computer graphics, from hidden surface removal and occlusion culling, to global illumination and image-based modelling and rendering.
Visibility methods aim to calculate either the regions of a space which can be seen from a point (from-point visibility computation), or those that can be seem from a region
(from-regionvisibility computation). In simple terms, visibility
de-termination uses visual events – the boundary configurations for which the visibility changes – to partition space. Such methods can be broadly categorized according to the space in which the partitioning is performed, that is, object space, image space, viewpoint space or line-space (for a detailed presentation see [Dur99]).
The efficiency and simplicity of ray casting make it the default choice for evaluating visibility in many real-time camera control applications, in particular, computer games [Gio04]. An alternative to ray casting is to use consistent
re-gionsof space through the representation of the visibility of
a target object in local spherical coordinates centered on the object [BL99,PBG92,DZ95].
Hardware-based approaches to real-time visibility for camera control [HO00] evaluate the degree and extent of oc-clusion by rendering a scene in stencil buffers using a color for each object. Such techniques have a number of attrac-tive properties including an independence from the inter-nal representation of the objects, and, by avoiding bound-ing volumes and other geometric approximations of the ob-ject, a more accurate calculation of occlusion. Approaches based on rendering also allow the use of low resolution
buffers where appropriate [PBG92,HHS01]. Although effi-cient, such techniques are not readily extended to more that one target object and the visual extent of most target objects is not well approximated by a point. Furthermore, truly ex-pressive approaches to camera control require the manage-ment of both partial and temporal occlusions.
3. Occlusion-free Camera Control
Our main contribution is the provision of a method for the efficient evaluation of the visibility of one or more targets for a limited region around the current camera location. The method is robust and efficient and can be integrated as a component in charge of handling visibility for many camera control systems. Real-time visibility evaluation is closely re-lated to the problem of computing shadows for complex light sources and receivers, and a number of shadow techniques can be employed. Our system uses the principle of shadow maps to evaluate the visibility of single or multiple targets within a restricted search space (a set of candidate camera locations) and composes the resulting visibility information. Furthermore, we use multiple penumbra maps per target ob-ject to better represent the visual extent of complex obob-jects in a manner similar to [ARHM00]. The process is divided in four steps that we present in the following sections. 3.1. Bound: computing the visibility volume
The dynamics of the camera (position, velocity and accelera-tion) bounds the movement of the camera within a plausible subset of space. Given the maximum possible acceleration
amax in any direction as determined by the application, the
current camera position ct at time t, and its velocity vt, it
is possible to compute a boundary volume within which the camera must reside at the next frame (we refer to this vol-ume as the predictive camera volvol-ume) as a sphere located at ct+ ∆tvtof radius ∆t2amax. Frustums can then be designed
to fully encompass this region.
In practical cases, to reduce the locality of our search, and thereby reduce the impact of failures (i.e. when the whole predictive camera volume is occluded), the radius of the sphere is multiplied by a factor n which can be dynamically controlled depending on the application.
3.2. Sample: rendering from both viewpoints
While the visibility of a single target object can be computed using a depth map and a standard symmetric frustum, for multiple target objects we propose the construction of non-symmetric frustums for each pair of target objects. The inter-section of these frustums defines a visibility volume inside the predictive camera volume, in which we can compose the visibility information for a selected set of candidate camera positions. By using the depth values for each projection we can obtain 3D information as to the visibility of the target
objects in the visibility volume and can address the visibil-ity information using a trilinear interpolation (see Figure1). Defining a common far plane for the frustums (behind the predictive visibility volume), guarantees that rays for corre-sponding scanlines of each frustum intersect. These inter-section define a set of sample points within the predictive camera volume for which the visibility of both target objects in known precisely (i.e. no interpolation of visibility infor-mation required).
The geometry of the projection and the resolution of the images determine the granularity of the sampling of the visi-bility volume. The resolution of the rendering, which defines the precision of the visibility computations, can be dynami-cally computed given a density parameter inside the feasible
camera volume(number of samples per unit of volume).
Furthermore, visibility volumes for successive frames can be aggregated to stabilize the camera (i.e. make the camera robust to momentary occlusion).
3.3. Aggregate: combining visibility information We evaluate the visibility status of each area as one value of {N, PA, PB,V } such that:
N Neither of the two objects are visible PA Partially visible (only object A is visible)
PB Partially visible (only object B is visible)
V Visible (both objects)
We thus define the composition operator ⊗ that computes the visibility state from two depth values zAand zBas:
zA⊗ zB= N i f (zA< zAI) ∧ (zB< zBI) PA i f (zA> zAI) ∧ (zB< zBI) PB i f (zB> zBI) ∧ (zA< zAI) V i f (zA> zAI) ∧ (zA> zAI)
and we can extend the composition operator ⊗ to vectors by building the matrix of visibility states:
zA⊗ zB= zA1⊗ zB1 · · · zA1⊗ zBm .. . . .. ... zAn⊗ zB1 · · · zAn⊗ zBm
Where there is no occluder, the z-buffer defaults to the maximum depth value which is always greater than the dis-tance to the intersection point I.
In order to efficiently compute and access the visibility states inside the visibility volume, we choose to express the intersection of the frustums as a 3D trilinear coordinate sys-tem as displayed in Figure1. Each point I inside the visibil-ity volume is represented in local coordinates, I = [uvw]T,
and expressed in global Cartesian coordinates as a linear combination of vectors i, j1, j2, k1, k2, k3, k4(where i, · · · , k4
are defined in Cartesian coordinates). We refer to IAB: R3→ R3as the trilinear interpolation function related to the visi-bility volume for target objects A and B, that expresses lo-cal coordinates [uvw]T in Cartesian coordinates I′= [xyz]T,
where:
I′= IAB([uvw]T)
= u.i + v((1 − u)j1+ uj2) +
w((1 − u)((1 − v)k1+ vk2) + u((1 − v)k4+ vk3)) We can now very conveniently use the local coordinates [uvw]T to address the depth values of each rendered im-age. Indeed, a pixel (u, v) in image B, together with a pixel (1 − w, v) in image A (the second component is identical as only rays in corresponding scanlines are intersected) inter-sect exactly at local coordinates [uvw]T inside the visibility
volume. This enables both the efficient computation of all the intersection points inside the volume (only through vec-tor algebra, at a cost of one sum per point if computed in-crementally), as well as direct access to the visibility states in the corresponding 3D matrix given a pair of 2D coordi-nates in the image. Furthermore, it is possible to compute the inverse function (IAB)−1to obtain the local coordinates of any point inside the visibility volume, and thus establish its visibility status (see Section3.3).
By utilizing standard graphics hardware, this model en-ables the efficient computation of a sampling of the visibil-ity volume. Knowledge of the visibilvisibil-ity of the target objects, for viewpoints at and around the current camera location, is used as the basis for choosing whether to move the camera, and where to move it to (see Section3.4). The granularity of the visibility volume is directly dependent on the resolution of the 2D renderings and is easily controlled according to the characteristics of the environment and the resource demands of the application.
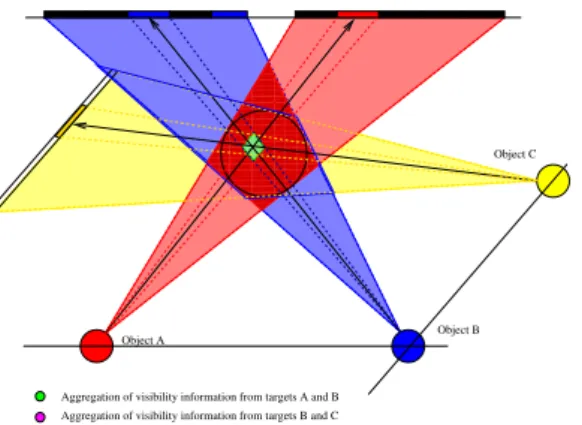
Moreover, by using visibility volumes, our approach can be seamlessly extended to more than two target objects, cf. Figure2.
3.4. Move: choosing the next camera position
Choosing the best next camera position within the
predic-tive camera volume is application-dependent. Our task is
therefore to provide parameters that capture the camera’s behavior in common situations, including its responsive-ness (speed of change in occluded configurations), coher-ence (maintenance of visual properties), and its predictive power (its ability to look-ahead and avoid occluded configu-rations).
Currently, we compute four different sets of camera re-gions: SN(where both A and B are not visible), SPA(only A
is visible), SPB(only B is visible), and SV (both A and B are
visible). Responsiveness is enforced by choosing camera lo-cations that try to always ensure the visibility of the targets (i.e. in SV), generally at the cost of jumpiness and sudden
M. Christie & J.-M. Normand & P. Olivier / Occlusion-free Camera Control for Multiple Targets 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 00000000000 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 11111111111 Object B Aggregation of visibility information from targets A and B
Aggregation of visibility information from targets B and C
Object C
Object A
Figure 2: Visibility computation for three targets A, B and
C. Two visibility volumes VAB and VBC are computed and
each configuration of VABis expressed in the basis of VBCto
evaluate its visibility status. The rendering from object B is performed only once and resampled for use by both visibility volumes.
accelerations (although still within the acceleration bounds). Coherence is enforced by choosing areas where the visual properties on the screen are maintained over time, such as camera angles with respect to targets, camera heights, cam-era shots. Finally, the predictive power of the camcam-era is achieved by selecting locations in SV for which promixal
neighboring regions are also unoccluded. 4. Stochastic Model of Visual Extent
In a pragmatic way to approximate the visual extent of ob-jects (and thus approximate the visibility of the entire object, rather than a point on the object), we propose a tessellation independent stochastic method that automates the choice of target points on the surface of an object for different view-points and distances. We cycle between these target view-points in a round robin manner, selecting one point per frame, and the accumulation of this visibility information over different frames provides an improved estimate of the overall visibil-ity of the target.
In a two-step process, we off-line distribute camera con-figurations evenly around the object and perform basic ren-derings. A random distribution of points is projected onto each rendered image, and points inside the projected extent of the object are retained. For each point, its 3D position on the surface of the object is computed by inverse projection. The density of the sampling on the rendered image is kept uniform, whatever the distance to the camera, so that objects that are larger (or closer to the camera) present more samples on their surface. These points approximate the visual extent of the target object and are stored in a view indexed sam-ple table. In the second step, in the course of computing the real-time visibility, we use the relative orientation of the tar-get, the visibility volume, and the distance between them, to
look up the points in the sample table from which we select the particular point to be used for the projection (in a round robin manner).
5. Temporal Visibility Volume
Another important problem for real-time camera control, and one that is related to visibility, is the maintenance of shot coherency (i.e. avoiding abrupt and visually incongru-ous changes in viewpoint). If a camera only reacts to fea-tures that are ‘in shot’, then a sudden onset of occlusion that occurs in dynamic and complex environments will result in equivalently abrupt responses by the camera. To mitigate this we need incorporate mechanisms that stabilize the camera movements according to the spatial and temporal evolution of visibility. By monitoring the accumulation of the visibil-ity information over the successive frames we can explicitly control the degree to which the camera is sensitive to partial and short-lived occlusions.
We define the aggregation operator Lα as a
low-pass filter which, applied over a set of visibility states {· · · vt, · · · , vt−i, · · · vt−n}, retains a visibility state v if xv
n ≥
α, where xvrepresents the number of occurrences of state
v, n is the number of frames and 0 ≤ α ≤ 1. We treat cases
where no state meets this condition pessimistically by con-sidering them as occluded (value N).
As the visibility volumes evolve in space, some boundary configurations cannot be expressed in previous bases. Rather than adopting a pessimistic approach, declaring the status of out-of-bounds positions as occluded (value N), we count the occurrences of visibility states on all but out-of-bounds con-figurations. This temporal visibility volume, with which we accumulate the visibility states of past frames, can be cou-pled with an estimation of visual extent to provide meaning-ful control of the desired degree of visibility of a target.
Experimental results, as well as example camera behav-ior in the accompanying video, demonstrate the improved temporal stability situations that involve partial occlusion and encounters with short-lived occluders (see Section6). The complexity of this process is bounded by O(ng3) as we only aggregate for points inside the feasible camera volume. In our implementation, the complexity is readily reduced to
O(g3) by locally storing frame indices for each component visibility state.
6. Evaluation and Discussion
We have conducted a number of experiments on our proto-type implementation of occlusion-aware camera control with a view to evaluating the different aspects so far described. All evaluations were run on an Intel Core 2 T7600 at 2.33 Ghz, 2GBytes of RAM and with a NVidia FX 3500 graphics card running the Ubuntu Linux system.
For each experiment, we have measured and reported the following properties:
• tcthe average time in milliseconds required to compute an
occlusion-free view (this includes the hardware rendering, the computation of the intersections, and the choice of the new camera configuration).
• dcthe total distance covered by the camera during the
ex-periment (used as a proxy for camera stability).
• dsthe distance covered in 2D by the projected centers of
the target objects (used as a proxy for coherence). • rNthe proportion of fully occluded frames (as a
percent-age).
• rP the proportion of partially occluded frames (as a
per-centage).
The costs related to the different steps of the visibility computation process, for a number of different resolutions, are provided in Table1. The size of the accumulation win-dow has very little impact on the results. The extraction of the depth buffer information uses the OpenGL glRead-Pixels()function over the depth buffer which could be further improved by using Frame Buffer Objects.
An initial performance evaluation of our camera control scheme, for a moderately complex scene in Ogre3D (280K triangles), over 5000 frames, confirms that the computation of the intersections is the performance bottleneck (see Ta-ble1). It should be noted that the expensive step of com-posing depth information can be entirely hardware acceler-ated by using vertex and fragment shaders. However, with a low resolution buffer (7 × 7), we can evaluate more than 300 possible camera configurations (and select the best one) in less than 3ms. Both visibility evaluation and viewpoint se-lection are exclusively performed on the CPU. However, in addition to the computational cost, we need to evaluate other aspects of camera behavior that our approach to occlusion-aware camera control seeks to facilitate. These include re-sponsiveness, coherence, predictive power and temporal sta-bility, as well as the simultaneous visibility of more than two target objects and the incorporation of supplementary prop-erties.
Table 1: Performance (ms) of the visibility computation for
different resolutions r for (i) hardware rendering; (ii) inter-section calculation; and (iii) next configuration selection.
r Samples Render Intersect Select Total
5 75 0.70 0.91 0.16 1.77
7 343 0.80 2.10 0.72 3.62
10 1000 0.80 5.20 1.81 7.83
15 3375 1.00 19.30 4.28 24.63
6.1. Predictive power
Our occlusion-aware technique detects and tries to main-tain visibility within a camera’s dynamic limits. Indeed, in both computer graphics applications and real-life camera motion, it is highly desirable to avoid sudden occlusion by
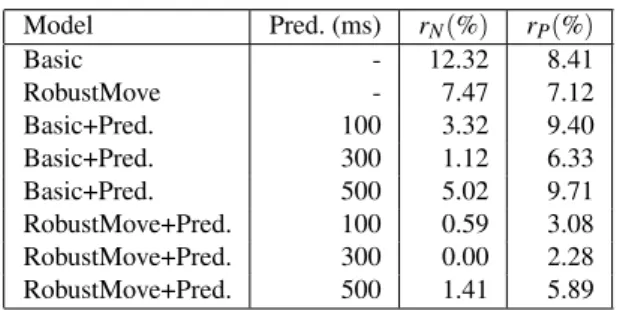
using early anticipation. A partial solution simply involves making better choices between the candidates within the occlusion-free configurations, for example, by favoring con-figurations located away from occluded areas. To achieve this we gather free configurations together using their unoc-cluded neighbors in the visibility volume. The camera then moves towards the center of the largest connected group. In this benchmark we refer to this strategy as RobustMove. Our results (see Table2) demonstrate improvements in the over-all visibility during the shot. However, in the case of sharp turns and sudden occlusions, this strategy is insufficient. We use a simple prediction model (referred to as Prediction) that builds upon the past translational and rotational accel-erations of target objects to estimate the future location.
Table2shows the results of our evaluation of the
Robust-Moveand Prediction strategies, both separately and together,
against the basic move strategy that selects the closest vis-ible neighbor. For each run we computed the rate of full occlusions and the rate of partial occlusions (i.e. when at least one pixel is occluded) in the shot. The average ratio of occlusion (proportion of occluded pixels on the surface of the targets) is also computed. Both properties are mea-sured in a post-process by re-rendering the shot with stored traces in medium-resolution buffers (512 × 512) to study pixel overlapping. The combination of Prediction and
Ro-bustMoveprovided the best results. The prediction time has
to be carefully selected; in our example prediction times over 300ms yielded high occlusion rates due to significant differ-ences between predicted and actual positions.
Table 2: Comparison of occlusion models in combination
with a prediction strategy as to the motion of the targets. rN
is the percentage of fully occluded frames, rPis the
percent-age of partially occluded frames.
Model Pred. (ms) rN(%) rP(%) Basic - 12.32 8.41 RobustMove - 7.47 7.12 Basic+Pred. 100 3.32 9.40 Basic+Pred. 300 1.12 6.33 Basic+Pred. 500 5.02 9.71 RobustMove+Pred. 100 0.59 3.08 RobustMove+Pred. 300 0.00 2.28 RobustMove+Pred. 500 1.41 5.89 6.2. Coherence
Coherence refers to a camera’s ability to maintain the visual properties of a shot over time and can be measured in terms of the rate at which visual properties of a shot change. We en-force coherence by selecting cells that offer minimal change in visibility, camera orientation and the distance to the tar-get. In evaluating camera coherence we measured the mean deviation of property satisfaction together with the sum of the camera accelerations over a time interval.
M. Christie & J.-M. Normand & P. Olivier / Occlusion-free Camera Control for Multiple Targets
Figure 3: Stability evaluation: a sparse occluder moves back
and forth in front of two targets. Accumulating the visibility states reduces the jerkiness in the camera paths (left frame is without stability, right frame is with stability).
6.2.1. Evaluation of temporal coherence
Temporal stability measures the responsiveness of the cam-era to sparse and/or fast moving occluders. In our experiment we used two target objects (characters) and a sparse occluder (fence) that moves back and forth in front of the targets for 10 seconds (see Figure3). Table3shows the quantitative results.
Table 3: Quantitative comparison of the stability of visual
estimates by considering3 parameters: tcaverage time (ms),
dcdistance covered by the camera, dsthe distance covered
by the projected centers of the target objects. A stability of
6/10 denotes that a configuration will be assigned a
visibil-ity value that has occurred at least6 times in the past 10
frames. Experiment a/n tc(ms) dc ds No stability 0/0 2.69 157.0 1.7 Stability 3/5 2.75 38.4 1.2 Stability 6/10 2.87 4.1 0.1 Stability 8/15 2.91 0.4 0.1 7. Conclusion
Our proposed approach to maintaining occlusion free views addresses a number of fundamental problems of camera con-trol for 3D graphics applications. The ability to track one, two or more target objects without the imposition of sig-nificant computational cost is an important advance over both existing proposals from the research community and ray casting approaches widely deployed as ‘best practice’ in commercial applications. The stochastic modelling of vi-sual extent means that objects are no longer treated as simple points or bounfing volumes.
The ability to accumulate visibility information over time also provides parameterized control over the dynamic behav-ior of the camera, both in terms of the tolerance of the cam-era to partial (and temporary occlusion) and spatial scope to which the search is extended in the event that none of the targets are visible (the escape strategy).
Although our occlusion-aware framework constitutes a
significant advance over the state of the art, it has a number of noteworthy limitations. Firstly, our approach is based on a local exploration around the current camera configuration. This process could be interleaved with a visibility computa-tion for a secondary camera posicomputa-tion (eg. one frame on five) but this is a poor substitute for a global evaluation of cam-era locations which would better support the incorporation of jump cuts.
However, our proposed technique has significant poten-tial to enhance applications that require assisted interactive or automated camera control in complex environments. The technique is lightweight, utilizes ubiquitous graphics hard-ware, and can be readily incorporated into the rendering pro-cess of any real-time graphics application.
References
[ARHM00] AGRAWALAM., RAMAMOORTHIR., HEIRICHA., MOLL L.: Efficient image-based methods for rendering soft shadows. In SIGGRAPH ’00: Proceedings of the 27th annual
conference on Computer graphics and interactive techniques
(New York, NY, USA, 2000), ACM Press/Addison-Wesley Pub-lishing Co., pp. 375–384.doi:http://doi.acm.org/10.
1145/344779.344954.2
[BL99] BARESW. H., LESTERJ. C.: Intelligent multi-shot vi-sualization interfaces for dynamic 3D worlds. In Proceedings
of the 4th international conference on Intelligent user interfaces (IUI 99) (New York, NY, USA, 1999), ACM Press, pp. 119–
126. doi:http://doi.acm.org/10.1145/291080.
291101.2
[COCSD00] COHEN-OR D., CHRYSANTHOU Y. L., SILVA
C. T., DURANDF.: A survey of visibility for walkthrough ap-plications. IEEE Transactions on Visualization and Computer
Graphics 9, 3 (2000), 412Ð431.2
[CON08] CHRISTIEM., OLIVERP., NORMANDJ.-M.: Camera control in computer graphics. Computer Graphics Forum 27, 8 (2008), 2197–2218.2
[Dur99] DURANDF.: 3D Visibility: Analytical Study and
Appli-cation. PhD thesis, Université Joseph Fourier, Grenoble,
Greno-ble, France, July 1999.2
[Dur00] DURANDF.: ACM SIGGRAPH Course Notes: Visibility,
Problems, Techniques, and Applications. ACM Press, New York,
NY, 2000, ch. A multidisciplinary survey of visibility.2
[DZ95] DRUCKERS. M., ZELTZERD.: Camdroid: A System for Implementing Intelligent Camera Control. In Symposium on
In-teractive 3D Graphics(1995), pp. 139–144. URL:citeseer.
ist.psu.edu/drucker95camdroid.html.2
[Gio04] GIORSJ.: The full spectrum warrior camera system. In
GDC ’04 : Game Developers Conference 2004(2004).2
[HHS01] HALPERN., HELBINGR., STROTHOTTET.: A cam-era engine for computer games: Managing the trade-off between constraint satisfaction and frame coherence. In Proceedings of
the Eurographics Conference (EG 2001)(2001), vol. 20,
Com-puter Graphics Forum, pp. 174–183.2
[HO00] HALPERN., OLIVIERP.: CAMPLAN: A Camera Plan-ning Agent. In Smart Graphics 2000 AAAI Spring Symposium (March 2000), pp. 92–100.2
[PBG92] PHILLIPSC. B., BADLERN. I., GRANIERIJ.: Auto-matic viewing control for 3d direct manipulation. In Proceedings
of the 1992 symposium on Interactive 3D graphics(1992), ACM