UNIVERSITÉ MOHAMMED V
THÈSE DE DOCTORAT
Discipline
Spécialité
Mesure de la Qualité de la Vidéo
les Réseaux de Neurones
Soutenue le : 14 Juillet 2015
Devant le jury :
Président
: Driss ABOUTAJDINEExaminateurs :
Ahmed TAMTAOUI Ahmed HAMMOUCH Mostafa BELFKIH Mohammed RZIZA Mohamed EL HAZITIUNIVERSITÉ MOHAMMED V
FACULTÉ DES SCIENCES
Rabat
THÈSE DE DOCTORAT
Présentée par :
Hasnaa EL KHATTABI
Discipline : Sciences de l’ingénieur
Spécialité : Informatique et Télécommunications
Mesure de la Qualité de la Vidéo
Réseaux de Neurones
14 Juillet 2015
PES, Faculté des Sciences de Rabat, Maroc.
PES, Institut National des Postes et Télécommunications, Rabat, Maroc.
PES, Ecole Normale Supérieure de l'Enseignement de Rabat, Maroc.
PES, Ecole National Des Postes et Télécommunications,
Rabat, Maroc.
PH, Faculté des Sciences de Rabat, Maroc.
PH, Ecoles Supérieure de Technologie, Salé,
N° d’ordre : 2783
Informatique et Télécommunications
Mesure de la Qualité de la Vidéo par
Réseaux de Neurones
Faculté des Sciences de Rabat, Maroc.
National des Postes et Télécommunications, Ecole Normale Supérieure de l'Enseignement de
National Des Postes et Télécommunications,
PH, Faculté des Sciences de Rabat, Maroc.
Remerciements
Je remercie en premier lieu, Dieu tout puissant de m’avoir permis de mener à bien et d’achever ce modeste travail.
Notre travail est effectué au sein du Laboratoire de Recherche en Informatique et Télécommunications (LRIT, URAC 29) de la Faculté des Sciences de Rabat, Université Mohamed-V, Rabat, en collaboration avec le Laboratoire Systèmes des Télécommunications, Réseaux et Services à l’Institut National des Postes et Télécommunications de Rabat.
Cette thèse n’aurait pu être menée à bien sans l’aide des personnes à qui je voudrais adresser tout mes remerciements.
Je dois, des remerciements particuliers à mon directeur de thèse, Mr. Driss ABOUTAJDINE, Professeur à la Faculté des Sciences de Rabat pour son enseignement, pour m’avoir fait confiance, pour m’avoir donné la chance d’effectuer ce doctorat, pour m’avoir tant appris, et pour l’honneur qu’il me fait en présidant mon jury de thèse.
Aussi je dois des remerciements particuliers à mon co-encadrant de thèse, Mr. Ahmed TAMTAOUI, Professeur à l’Institut National des Postes et Télécommunications de Rabat pour son aide, ses conseils, son enseignement, nos innombrables discussions et son précieux soutien durant ces années.
J’adresse également mes remerciements à Mr. Ahmed HAMMOUCH, Professeur à l’Ecole Normale Supérieure de l’Enseignement Technique de Rabat d’avoir bien voulu être rapporteur et de faire partie de mon jury de thèse.
Je remercie également Mr. Mostafa BELFKIH, Professeur à l’Institut National des Postes et Télécommunications de Rabat d’avoir bien voulu être rapporteur et de faire partie de mon jury de thèse.
Je remercie également Mr. Mohammed RZIZA, Professeur à la Faculté des Sciences de Rabat d’avoir bien voulu être rapporteur et de faire partie de mon jury de thèse.
Je remercie également Mr. Mohamed EL HAZITI, Professeur à Ecoles Supérieure de Technologie Salé pour avoir accepté d’être membre de mon jury en tant qu’examinateur. Une pensée profonde comblée d’amour et d’affection à ma mère et feu mon père, lumière de ma vie, mes sœurs et mes frères pour leur soutien au cours de ces années et sans lesquels je n'en serais pas là aujourd'hui.
Mes remerciements vont enfin à toute personne qui a contribué de près ou de loin à l’élaboration de ce travail.
Dédicace
A la mémoire de mon père.
Résumé
Le but de notre recherche est de changer le jugement de la perception humaine, la qualité subjective, par l’évaluation de la machine. Nous avons opté d’estimer cette qualité par un réseau de neurones pour pouvoir espérer une mesure plus corrélée à la vision humaine. Pour se faire, nous avons commencé par identifier les paramètres les plus utilisés dans le domaine de traitement d’images. Par la suite nous avons optimisé l’architecture du réseau qui nous donne les meilleurs résultats, en changeant le nombre de paramètres fournit au réseau, le nombre des nœuds que contient chaque couche en commençant par la couche d’entrée, en passant par les couches cachées et la couche de sortie, et en essayant différentes fonctions d’apprentissage. Après plusieurs tentatives de test des modèles, nous avons pu trouver un réseau qui nous a fourni des résultats meilleurs par rapport aux résultats existants.
Notre réseau de neurones prévoit la différence moyenne des scores d’opinion (Difference Mean Opinion Scores (DMOS)) des observateurs, et le rapport signal sur bruit en crête (Peak Signal to Noise Ratio(PSNR)), en fournissant huit paramètres extraits de vidéos originales et codées à l’entrée. Les huit paramètres utilisés sont : La moyenne de la différence des coefficients de la transformée de Fourier (Discrete Fourier Transformation (DFT)), l’écart type de la différence des coefficients DFT, La moyenne de la différence des coefficients de la transformée en cosinus discrète ou TCD (Discrete Cosine Transform (DCT)), l’écart type de la différence des coefficients DCT, la variance de l’énergie de la couleur, la luminance Y, la chrominance U et la chrominance V. Les résultats qu’on a obtenu pour la corrélation entre la sortie calculée et la sortie estimée, on a un pourcentage de 99.58% pour l’apprentissage et 96.4% pour le teste, qui sont meilleurs par rapport aux résultats existants.
Mots clés :Vidéo, Réseau de neurones PMC, Qualité subjective, Qualité Objective, Rétro-propagation, Luminance, Chrominance.
Abstract
In order to change the human perception judgment, subjective quality, by the machine evaluation, in this paper, we present the video quality measure estimation via a neural network.
Several tests have been conducted to find the architecture of a neural network that would give us better results. And similarly several experiments have been tried to search the adequate number of parameters.
This latter predicts Difference Mean Opinion Scores (DMOS) and Peak Signal to Noise Ratio (PSNR) by providing height parameters extracted from original and coded videos. The eight parameters that are used are: the average of DFT differences, the standard deviation of DFT differences, the average of DCT differences, the standard deviation of DCT differences, the variance of energy of color, the luminance Y, the chrominance U and the chrominance V. The results we obtained for the correlation show a percentage of 99.58% on training sets and 96.4% on the testing sets. These results compare very favorably with the results obtained with other methods.
Keywords :
Video, Neural Network MLP, Subjective Quality, Objective Quality, Retropropagation, Luminance, ChrominanceTable des matières
Introduction générale……… 11
Chapitre I : La mesure de la qualité de la vidéo………..15
I. Introduction ... 16
II.VISION HUMAINE ... 17
II.1. Physiologie de l'œil ... 17
II.1.1. Les cônes ... 18
II.1.2. Les bâtonnets ... 19
II.2. L’interprétation du Système Visuel Humain (SVH) ... 20
II.3. La perception de la luminance ... 23
III. Les méthodologies d’évaluation subjective ... 23
III.1. Les méthodes à stimulus simple... 25
III.2. Les méthodes à double stimulus ... 26
III.3. Les méthodes comparatives ... 28
IV. Les méthodologies d’évaluation objective ... 29
V. Conclusion ... 34
Chapitre II : Réseaux de neurones …………..……….….. 36
I. Introduction ... 37
II. Historique ... 38
III. Le neurone Biologique ... 40
III.1. La cellule nerveuse ... 40
III.2. Fonctionnement des neurones ... 41
III.3. Modélisation simplifiée d’un neurone ... 42
IV. caractéristiques d’un réseau ... 44
IV.1. Les architectures usuelles des réseaux des neurones ... 45
IV.2. Fonctions d’activation ... 47
IV.2.1. Fonction binaire à seuil ... 47
IV.2.2. Fonction linéaire... 49
IV.2.3. Fonction linéaire à seuil (ou multi-seuils) ... 49
IV.2.4. Fonction sigmoïde ... 50
V. Quelques réseaux célèbres ... 51
V.2. Les perceptrons multicouches (PMC) ... 51
V.3. Les réseaux de Hopfield ... 51
V.4. Les réseaux de Kohonen ... 52
VI. Les perceptrons multicouches (PMC)... 52
VI.1. Description ... 52
VI.2. Fonctionnement de multicouches ... 53
VI.3. Apprentissage (Training) ... 54
VI.3.1. Principe et définition de l’apprentissage des réseaux de neurones ... 54
VI.3.2. Types d’apprentissage ... 55
VI.4. Algorithme et règle d’apprentissage de la rétro-propagation (backpropagation) ... 56
VI.4.1. Procédure de rétro-propagation: ... 57
VI.4.2. Logiciel d’implémentation utilisé : ... 59
VII. Construction et procédure de développement de réseau de neurones... 60
VII.1. Collecte et analyse des données ... 60
VII.2. Choix d’un réseau de neurones... 61
VII.3. Base d’apprentissage et mise en forme des données pour un réseau de neurones ... 62
VII.3.1. Fichier d'apprentissage ... 62
VII.3.2. Algorithme et paramètres d’apprentissage ... 63
VII.3.3. L'efficacité d'apprentissage dépende des paramètres suivant ... 63
VII.3.4. Validation et résultats de simulation ... 64
VII.3.5. Test du réseau ... 64
VIII. Conclusion ... 65
Chapitre III : Algorithmes de la rétro-propagation du gradient avancée pour apprentissage des réseaux PMC ……….66
I. Introduction ... 67
II. Algorithme de la rétro-propagation du gradient non améliorée (GBP : Gradient Backpropagation) ... 67
II.1. Gradient stochastique (Pattern Mode) ... 69
II.2. Gradient total (Batch Mode) ... 69
III. La rétro-propagation du gradient améliorée ... 70
III.1. La rétro-propagation du gradient améliorée avec momentum ... 70
III.2. Algorithme de la rétro-propagation du gradient à convergence accélérée par l’adaptation du coefficient d’apprentissage ... 71
III.2.1. Algorithme du gradient conjugué CG ... 71
III.2.3. Algorithme du gradient Conjugué à l'échelle (Scaled Conjugate Gradient (SCG)) ... 71
III.2.4. Rétro-propagation du gradient "résistante" : RPROP ... 72
IV. Conclusion ... 72
Chapitre IV : Développement, réalisation, et tests de nouvelles architectures de réseau de neurones ……… 73
I. Introduction ... 74
II. Traitement de la vidéo ... 75
III. Méthode de la mesure de la Qualité Subjective utilisée ... 79
IV. Procédure utilisée pour l’évaluation de la qualité objective ... 79
IV.1. Extraction des paramètres ... 79
IV.2. Réseau de neurone multicouche développé ... 80
IV.2.1. Initialisation du PMC ... 80
IV.2.2. Architecture du PMC utilisé ... 80
IV.2.3. Apprentissage ... 82
V. Expérimentation et résultats... 82
V.1. Estimation de la mesure de la qualité de la vidéo par le réseau PMC à quatre paramètres et une seule sortie [1] ... 83
V.2. Estimation de la mesure de la qualité de la vidéo par le réseau PMC à huit paramètres et une seule sortie [53] ... 85
V.3. Estimation de la mesure de la qualité de la vidéo par le réseau PMC à huit paramètres et deux sorties ... 88
VI. Discussion et Conclusion ... 91
Conclusion générale ... 95
Références ... 97
Annexe A : Structure d’une vidéo ... 102
Annexe B : Normalisation des données par la méthode min-max ... 103
Annexe C : Technique d’encodage H263 ... 104
Annexe D : Les fonctions de reconstruction et d’apprentissage de réseaux de neurones en Matlab 107 Publications liées à la thèse ... 112
Liste des figures
Figure 1 : Coupe horizontale de l'œil droit ……….. 12
Figure 2 : Cellules réceptrices : cônes et bâtonnets ………..14
Figure 3 : Constituants du bâtonnet et du cône ………...………15
Figure 4 : Structure de la rétine ……….17
Figure 5 : Illustration de la méthode DSCQS. Les versions A et B sont présentées deux fois .…..21
Figure 6 : Exemple d’échelle de notation continue de la qualité pour évaluation DSCQS …….…..22
Figure 7 : Un exemple d’échelle de catégories de qualité visuelle ………23
Figure 8 : Une échelle comparative de qualité visuelle ..……….24
Figure 9 : Schéma d’un neurone biologique ………36
Figure 10 : Neurone Formel j ..………38
Figure 11 : Réseau totalement interconnecté ………..………..40
Figure 12 : Réseau à couches ………..……….40
Figure 13 : Réseau récurrent ………..……….41
Figure 14 : Perceptron Multicouche ……….……….…..47
Figure 15 : Démarche de la phase d’apprentissage ……….…………..….49
Figure 16 : Quelques images des séquences de la vidéo utilisées dans notre travail ………...….….72
Figure 17 : Architecture du Réseau PMC ……….….75
Figure 18 : Architecture du Réseau MLP pour la mesure de qualité ………..……….………78
Introduction
Nous vivons à l'heure du numérique et particulièrement de l'image numérique. Dans de nombreuses applications multimédia ou industrielles, il devient indispensable de juger la qualité de ces images couleurs traitées. La compression notamment, en fort développement avec l'explosion du multimédia, impose une garantie d'interprétation et de rendu des images après transfert ou stockage. De même, en synthèse d'image, se pose la question récurrente de savoir si les images produites sont suffisamment réalistes. Dans ce contexte, de nombreux travaux récents concernent l'utilisation optimale de la couleur en tant qu'information vectorielle, mais aussi psycho-visuelle, par la prise en compte des spécificités du Système Visuel Humain (SVH) pour l'appréciation de la qualité des traitements.
Au cours des dernières décennies, les méthodes et les algorithmes de traitement des images et de la vidéo (le multimédia) ont eu des avancées importantes. Parmi les applications possibles, on trouve la vidéoconférence, la vidéo sur Internet, la téléprésence, le stockage de données multimédia, etc. Ceci a donné cependant lieu à quelques problèmes importants qui doivent être abordés. Un des premiers problèmes à considérer est l’évaluation de la qualité de la vidéo, c’est un problème puisqu’aucune solution proposée jusqu’à présent n’est satisfaisante. Alors que de nos jours, les images et les vidéos numériques sont omniprésentes et la quantité de données associées est gigantesque. Ce qui rend l’évaluation de la qualité finale de la vidéo essentielle au vu des dégradations que subit la vidéo au cours de la compression nécessaire à sa transmission et au cours de sa transmission. On admet que la qualité finale est perçue par des spectateurs humains et que c’est la qualité visuelle de ce qu’ils perçoivent qui est en jeu. Il est donc nécessaire de mettre en œuvre des évaluations subjectives de qualité effectuées par des observateurs, qui de préférence n’ont pas de lien avec l’étude de la qualité vidéo. Il serait évidemment souhaitable de disposer d’une méthode objective pour mesurer cette qualité, utilisant un modèle mathématique pour stimuler le système humain. Cette méthode serait relativement plus rapide et moins chère que l’évaluation subjective.
Les métriques de qualité sont classées en trois catégories en fonction de la nature des informations nécessaires pour effectuer l’évaluation. Ces trois catégories sont :
– Les métriques de qualité avec référence complète, notées FR (Full Reference) [30], qui comparent la version de l’image ou de la vidéo dégradée avec une version de référence.
Pour cette catégorie de métrique, la version originale (référence) et la version dégradée à évaluer doivent être disponibles.
– Les métriques de qualité avec référence réduite, notées RR (Reduced Reference) [32], qui comparent une description de l’image ou de la vidéo à évaluer avec une description d’une version de référence. Une description est un ensemble de paramètres mesurés sur l’image ou la vidéo. Pour cette catégorie de métrique, la version dégradée à évaluer et une description de la version originale doivent être disponibles.
– Les métriques sans référence, notées NR (No Reference) [31], qui caractérisent les distorsions de l’image ou de la vidéo degradée à évaluer uniquement à partir de celle-ci et, éventuellement, à partir de connaissances a priori sur celles-ci. Pour cette catégorie, seule la version à évaluer est requise.
Il existe une littérature très riche sur les critères de la qualité de la vidéo, car chaque concepteur de système de traitement de la vidéo, ou de sous-système (optique, détecteur, compression…), a besoin de ses propres critères pour mesurer la qualité de la vidéo de sortie, correspondant à une version dégradée de la scène d’entrée. Chaque système implique d’une part, un ensemble de dégradations spécifiques (repliement de spectre, faux contours, effet de blocs…) et d’autre part, toutes les combinaisons possibles de ces dégradations.
Dans le but de changer le jugement de la perception humaine par l’évaluation de la machine, plusieurs recherches ont été réalisées au cours des deux dernières décennies. Parmi les méthodes usuelles, l’erreur quadratique moyenne (Mean Squared Error (MSE)), le rapport signal sur bruit de crête (Peak Signal to Noise Ratio (PSNR)), qui mesure la qualité en faisant une différence entre les images originales et dégradée. Un autre axe de recherche dans ce domaine se base sur les caractéristiques du système visuel humain, telle que la fonction de sensibilité au contraste. Il faut observer que pour vérifier l’exactitude de ces mesures, elles doivent habituellement être corrélées avec les résultats obtenus en utilisant des évaluations subjectives de la qualité. Pour la mesure subjective de la qualité, il existe deux méthodes principales : Echelle continue de qualité sur stimulus double (Double Stimulus Continuous Quality Scale (DSCQS)) et Evaluation continue de la qualité sur stimulus unique (Single Stimulus Continuous Quality Evaluation(SSCQE)).
Le domaine de la mesure de la qualité est un domaine très complexe [51], ce qui rend la conception dune mesure objective corrélée au Système Visuel Humain (SVH) très difficile. De ce faite, il va falloir chercher et trouver une méthode qui est à la fois théoriquement convenable et pratiquement non complexe à mettre en œuvre.
Face à cette difficulté, et pour être le plus proche (corrélé) du SVH, nous avons opté à concevoir et à optimiser des méthodes de la mesure de la qualité de la vidéo dégradée par les codeurs basées sur les réseaux de neurones. Ces derniers ont généralement prouvé leur habilité (avantage) dans le domaine de la mesure de la qualité et d’autres domaines, comparé aux autres techniques classiques tellesque : HDR VDP (High Dynamic Range Visual Difference Predicator), UIQI (Universal Image Quality Index ) [21], SSIM (Structural SIMilarity) [19], MPQM (Moving Picture Quality Metric) [24], DVQ (Digital Video Quality) [16,17].
Dans ce contexte, nous cherchons dans cette thèse à améliorer et optimiser un modèle de réseau de neurones pour la mesure de la qualité de la vidéo dégradée par les codeurs. Nous adoptons dans notre travail la classe de la catégorie des métriques de qualité avec référence complète (FR).
Nous partons de l’idée qu’il faut obtenir une estimation de la mesure subjective de la qualité, à partir des paramètres calculés de la vidéo.
Le contenu de ce mémoire est organisé en quatre chapitres :
Dans le premier chapitre, nous avons présenté la physiologie de l’œil et détaillé quelques méthodologies d’évaluation subjective et objective de la qualité de la vidéo.
Par la suite, dans le second chapitre, nous nous sommes intéressés aux concepts des réseaux de neurones. Le troisième chapitre est consacré à la description de plusieurs algorithmes d’apprentissage.
Dans le chapitre quatre, nous avons traité et simulé trois architectures de réseaux de neurones qui sont comparés en terme de corrélation avec la mesure subjective. Nous terminons ce document de thèse par une conclusion générale.
Chapitre I
I.
Introduction
De nos jours, la vidéo numérique est présente pratiquement partout, c’est pourquoi la qualité visuelle est arrivée au centre des préoccupations des professionnels. L’évaluation de la qualité finale de la vidéo est un élément clé de la performance du codage et elle est essentielle vu les dégradations que subit la vidéo au cours de la compression nécessaire à sa transmission. Nous admettons que la qualité finale est perçue par des spectateurs humains et que c’est leur qualité de perception visuelle qui est en jeu. De ce fait les techniques de traitement d’images et de vidéos ont intérêt à prendre en compte et à exploiter la manière dont l’homme perçoit son environnement visuel. Il est donc nécessaire de mettre en œuvre des évaluations subjectives de qualité effectuées par des observateurs, qui de préférence n’ayant pas de lien avec l’étude de la qualité vidéo.
Dans ce domaine, nous distinguons deux catégories de méthodes : les méthodes subjectives et les méthodes objectives. Les méthodes subjectives sont les plus proches de la réalité, car elles consistent à faire évaluer la qualité par un groupe d’observateurs. Cependant, ces méthodes demandent beaucoup du temps et nécessitent des conditions expérimentales de visualisation bien précises. Par conséquent, elles représentent un coût trop important pour être utilisées de façon systématique dans l’industrie du traitement d’images ou de vidéos. D’autre part aucune solution proposée jusqu’à aujourd’hui n’est satisfaisante, d’où la nécessité de développer des méthodes objectives permettant d’évaluer la qualité visuelle de façon automatique.
Pour mesurer cette qualité, il serait donc souhaitable de disposer d’une méthode objective relativement plus rapide et moins chère que l’évaluation subjective.
Dans ce chapitre, nous expliquons d’abord brièvement le fonctionnement du Système Visuel Humain (SVH). Ensuite nous décrivons les méthodologies d’évaluations subjectives et objectives de la qualité de la vidéo.
II.VISION HUMAINE
II.1. Physiologie de l'œil
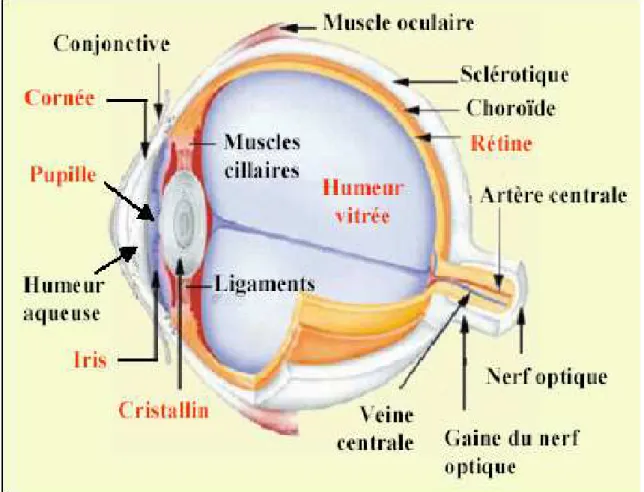
L’œil humain est constitué de :
-La conjonctive : c'est une solide membrane blanche, opaque aux rayons lumineux, servant à attacher l'œil dans son orbite.
-La cornée : il s'agit d'une membrane transparente et résistante située sur la face avant de l'œil. Son rôle est de protéger le globe oculaire sur la face avant.
-L'iris : il fonctionne comme un diaphragme en dosant la quantité de lumière qui pénètre dans l'œil. Son ouverture centrale est la pupille.
-Le cristallin : il fonctionne comme une lentille à focale variable, grâce à sa capacité de modifier sa courbure.
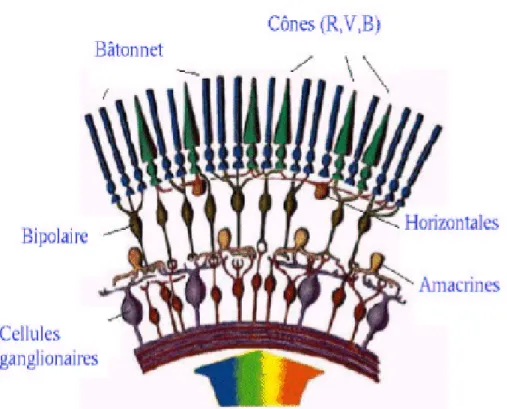
-La rétine : c'est sur elle que se forment les images provenant de l'extérieur. La rétine contient deux types de cellules photosensibles : les cônes et les bâtonnets.
-La macula : appelée également tache jaune, contient en son centre une petite dépression, la fovéa. Cette dernière est la zone d'acuité maximum de l'œil.
-Le nerf optique : il conduit les informations au cerveau, en passant par un relais très important, le corps genouillé latéral, chargé d'effectuer une première analyse des données. L'œil est l'organe de la vue mais la vision, c'est-à-dire la perception visuelle, nécessite l'intervention de zones spécialisées du cerveau (le cortex visuel) qui analysent et synthétisent les informations collectées en termes de forme, de couleur, de texture, de relief, etc.
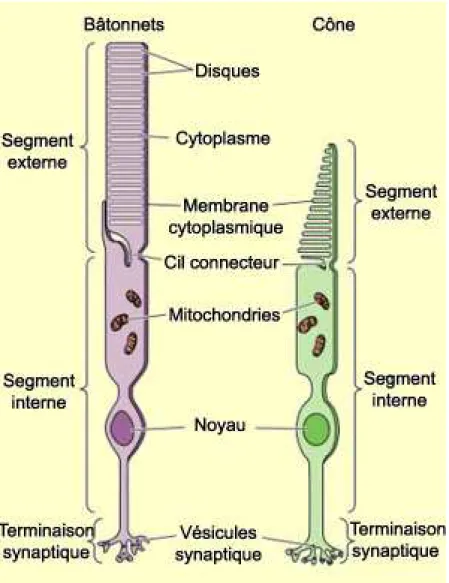
L’œil humain possède au niveau de la rétine des récepteurs photosensibles appelés : bâtonnets et cônes.
II.1.1. Les cônes
Au nombre de 6,4 millions dans la rétine, ils sont les constituants de la vision colorée et de la résolution spatiale de l’œil.
Il existe trois types de cônes selon leur sensibilité à la couleur (pour discerner les trois composantes RVB) :
-les cônes rouges ou cônes « L » (pour Large), représentent 64% du total des cônes. -Les cônes verts ou cônes « M » (pour Medium), représentent 32% du total des cônes. - Les cônes bleus ou cônes « S » (pour Small), représentent 4% du total des cônes.
II.1.2. Les bâtonnets
Au nombre de 120 millions, ils sont très sensibles à la lumière mais insensibles aux couleurs. Absents du centre de la fovéa ils sont les plus nombreux à environ 20° de l’axe optique. La figure 3 montre les composants de bâtonnet et du cône.
II.2. L’interprétation du Système Visuel Humain (SVH)
L’œil est un outil inégalé dans le monde de la vision en termes de performances. L’œil s’adapte à la quantité d’énergie qu’il reçoit, il ne répond pas de la même façon à une adaptation à la lumière et à l’obscurité. En effet, l’adaptation à la lumière se fait par une diminution de la concentration chimique dans les photorécepteurs. Par contre, pour une adaptation à l’obscurité le processus est plus long. L’œil utilise aussi un autre mécanisme, plus rapide et plus connu, qui est la variation du diamètre de la pupille. Le traitement de l’information captée par les yeux se fait par le cortex visuel. Actuellement, seul le fonctionnement de régions ou de zones du cortex visuel est compris. Il est pour l’instant impossible d’interpréter la fonction de chaque neurone.
Le cortex est séparé en deux parties : primaire et secondaire.
Le cortex visuel primaire est divisé en couches, qui ont chacune une tâche : - Orientation des contours ;
- Variation spatiale des fréquences ; - Variation temporelle des fréquences ; - Localisation spatiale particulière ; - Synthèse des tâches précédentes ;
Le cortex visuel secondaire réalise des traitements de plus hauts niveaux.
Le SVH est très sensible à la luminance d’une scène, il est préférable de ne pas modifier cette composante. Par contre, les composantes chromatiques bien que représentant la couleur, peuvent être sous-échantillonnées et ainsi obtenir une information plus dense sans dégradation perceptible. Il est important de bien connaître le SVH pour parfaire les algorithmes de compression. Ils permettraient de conserver un rapport qualité/compression correct et d’augmenter la compression par une pondération psychovisuelle.
Au début de la perception, nous avons donc un rayon lumineux. Ce dernier traversera les milieux transparents de l'œil, et à cause de leurs indices de réfraction différents, sera réfracté plusieurs fois, la cornée et le cristallin assurant l'accommodation de l'image. La lentille convergente formée par ces milieux transparents provoque aussi une "inversion" de l'image sur la rétine, qui sera corrigée par l'interprétation cérébrale. Puis le rayon traverse la rétine, pour arriver finalement aux segments externes des photorécepteurs, où il sera interprété dans le cortex cérébral dédié à la vision. Cette partie du cerveau appelée aussi "cerveau visuel". La rétine est constituée d'une couche fine de cellules nerveuses dont une grande partie est sensible à la lumière. Les cellules sensibles à la luminosité et au mouvement ce sont les bâtonnets (en anglais, « rods »). Les cellules sensibles à la couleur ce sont les cônes. Les bâtonnets sont responsables de la vision nocturne (vision scotopique). Leur sensibilité est liée à un colorant, la rhodopsine, qui blanchit à la lumière du jour, expliquant par là leur insensibilité la journée. Les bâtonnets ne fournissent qu'une réponse photométrique et ne permettent donc pas de déterminer les couleurs. Les cônes fournissent une réponse photométrique et chromatique, grâce à des pigments.
On peut synthétiser le rôle des cônes en disant qu'ils se chargent de mesurer, point par point, sur l'image oculaire, le contenu énergétique de la lumière qu'ils captent et de traduire ces mesures par une amplitude. Mais avant d'être transmise par les fibres du nerf optique, l'image est traitée par plusieurs autres cellules nerveuses. Les autres cellules rétiniennes se chargent ainsi de collecter et d'intégrer des signaux échantillonnés par un certain nombre de cônes, distribués sur des surfaces plus ou moins étendues de la mosaïque rétinienne. Ces surfaces et ces zones de collecte s'appellent des champs récepteurs. Ce qui est transmis au cerveau par le nerf optique est en fait le contraste de lumière entre le centre et le pourtour d'un champ récepteur. Etant donné que l'activité des trois catégories de cônes, S, M et L est restreinte à trois régions distinctes du spectre, le Bleu, le Vert, et le Rouge, le contraste mesuré pourra porter sur des comparaisons chromatiques entre des populations distinctes de cônes.
II.3. La perception de la luminance
Le système visuel humain est naturellement confronté à une dynamique importante de l’intensité lumineuse. Face à cette dynamique, des mécanismes d’adaptation se sont mis en place lui permettant de maintenir sa sensibilité aussi bien dans des conditions d’illumination importante, conditions photopiques, que dans des conditions d’illumination faibles, conditions stocopiques. Les trois principaux mécanismes d’adaptation à la luminance sont :
– La variation de l’ouverture de la pupille (entre 1,5 et 8 mm) qui laisse passer plus ou moins de lumière en fonction des conditions d’illumination. Le temps de réaction est de l’ordre de la seconde.
– La modification des concentrations photochimiques des photorécepteurs qui permet de modifier leur sensibilité. Plus l’intensité lumineuse est importante, et plus la concentration diminue entraînant une réduction de la sensibilité, et vice versa. Le temps d’adaptation est plutôt lent puisqu’il faut compter une heure pour une complète adaptation à l’obscurité.
– La modification de la réponse neuronale de toutes les couches cellulaires de la rétine. Cette adaptation est moins efficace que la précédente, mais beaucoup plus rapide.
Outre la capacité d’adaptation, la relation entre la luminance perçue (brillance) et la luminance réelle (luminance physique) n’est pas linéaire. De nombreuses expérimentations ont été menées dans le but de déterminer la nature de cette relation. Ces expérimentations consistant le plus souvent à faire classer des nuances de gris par des observateurs. Les expérimentations les plus nombreuses sont celles associées au système de Munsell [27].
III. Les méthodologies d’évaluation subjective
Notre perception d’une scène visuelle est formée par une complexe interaction entre les différents composants du système visuel humain, l’œil et le cerveau, de nombreux efforts ont été entrepris ces dernières années dans la définition des méthodes d’évaluation pour mesurer la qualité subjective de la vidéo. Cependant, ces méthodes sont difficiles à mettre en œuvre, et de plus elles sont coûteuses en termes de temps. Ainsi, des mesures objectives (algorithmes mathématiques) sont couramment utilisées pour évaluer la qualité.
Etant donné que l’être humain est le dernier utilisateur pour beaucoup de systèmes de vidéo numérique, il semble naturel que les observateurs humains doivent être utilisés pour le jugement de la qualité de l’image numérique, mais l’opinion d’une personne sur la qualité est affectée par d’autres facteurs comme l’environnement de la perception, l’état de l’esprit de la personne et l’ampleur de l’interaction de la personne avec la scène.
Nous décrivons l’environnement de déroulement des tests subjectifs d’évaluation de qualité qui associe des notes de qualité à des vidéos (dégradées ou non). Ces notes de qualité représentent l’appréciation des observateurs sur la qualité de ces vidéos.
Les tests subjectifs nécessitent une normalisation des conditions de tests. Cette normalisation facilite l’appréciation et diminue l’influence de paramètres perturbateurs. L’I.T.U. (International Telecommunication Union) [15] propose plusieurs recommandations dont par exemple la recommandation BT.500-10[ITU-R Rec. BT.500-10 00]. Cette recommandation contient un certain nombre de règles pour normaliser l’environnement de test. Dans cette section, trois éléments définissant la structure d’un test sont présentés : l’espace de visualisation, les observateurs et le déroulement d’une séance.
Les éléments les plus importants de l’espace de visualisation à maîtriser sont la distance d’observation, la luminosité ambiante et les caractéristiques de l’écran. La distance de visualisation a une influence directe sur la perception ; de cette distance dépend la répartition des fréquences spatiales de la vidéo projetée sur la rétine. Le contrôle de luminosité ambiante est important car il n’y a qu’une faible partie du champ visuel qui est excité par la vidéo de test, le reste est excité par l’environnement. Celui-ci influence la perception en modifiant l’adaptation en luminance du système visuel. De plus, il est souhaitable d’adapter la luminosité ambiante afin de limiter la fatigue visuelle.
Pour les observateurs, parmi les critères influençant les résultats on peut citer : l’âge et le sexe des observateurs, la spécialisation professionnelle et les défauts de vision. En effet, les observateurs ne peuvent faire partie du panel qu’à condition qu’ils n’aient pas de défaut de vision, ou qu’alors leurs défauts optiques soient corrigés (lunettes, lentilles, etc.). L’I.T.U. recommande que le panel d’observateurs soit constitué d’au moins 15 observateurs non initiés, c’est-à-dire qui ne sont pas confrontés dans leur activité professionnelle aux problématiques d’évaluation de qualité. Il faut s'assurer que ces observateurs possèdent une vision normale des couleurs (test de Ishihara) et une acuité visuelle normale (test de Snellen).
L’organisation d’une séance de tests peut varier en fonction de la méthode de test utilisé. Cependant, une base commune existe pour les différentes méthodes. Une séance de test est composée d’un certain nombre de présentations, chaque présentation correspondant à l’évaluation d’une vidéo potentiellement dégradée. Les différentes présentations d’une séance doivent être effectuées dans un ordre pseudo-aléatoire. De plus, les séances ne doivent pas dépasser trente minutes afin d’éviter la déconcentration et la fatigue visuelle. Une séance doit aussi comprendre des explications et quelques présentations préliminaires. Les explications doivent porter sur le protocole utilisé et sur l’échelle de notations. Les présentations préliminaires doivent permettre aux observateurs de stabiliser leur jugement en leur montrant des cas représentatifs de la gamme de qualité sur laquelle porte le test. Bien évidemment, les notations lors de ces séances préliminaires ne sont pas prises en compte dans les résultats finaux.
Il y a trois méthodes pour l’évaluation subjective : 1-Les méthodes à stimulus simple
2-Les méthodes à stimulus double 3-Les méthodes comparatives
Les conditions de déroulement de ces différentes méthodes sont normalisées par les recommandations de l’I.T.U. [ITU-R Rec. BT.500-10 00].
III.1. Les méthodes à stimulus simple
Dans cette catégorie nous citons la méthode la plus utilisée, nommée la méthode d’évaluation continue de la qualité avec stimulus unique (SSCQE : Single Stimulus Continuous Quality Evaluation) [15].
Durant le visionnage, l’observateur déplace un curseur, en fonction de la qualité subjective de la vidéo, sur une échelle allant de 0 à 100. Cette note est échantillonnée à une fréquence de 2 Hz, et on obtient donc deux notes de qualité par seconde. Cette méthode convient aux cas où la séquence d’origine n’est pas disposée ce qui correspond à la situation de téléspectateur qui ne connaît pas l’image enregistrée en studio de référence.
Nous citons aussi, la méthode d’échelle de dégradation avec stimulus unique (SSIS : Single Stimulus Impairment Scale) et la méthode d’échelle continue de la qualité avec stimulus unique (SSCQS : Single Stimulus Continuous Quality Scale), mais qui sont peu utilisées.
III.2. Les méthodes à double stimulus
Ces méthodes consistent à présenter à l’observateur deux vidéos : une version de référence et une version à évaluer qui est potentiellement dégradée.
Les méthodes les plus utilisées dans cette catégorie sont : Méthode à double stimulus utilisant une échelle de qualité continue DSCQS (Double Stimulus Continuous Quality Scale) et méthode à double stimulus utilisant une échelle de dégradation DSIS (Double Stimulus Impairment Scale) [15].
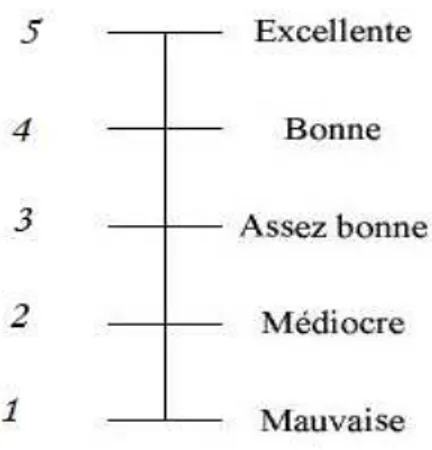
Dans la méthode DSCQS, les vidéos sont présentées par paire. On présente aux observateurs la séquence codée A et l’original B, sans savoir laquelle est la vidéo de référence, et ceci pour éviter le préjugement pour chacune des séquences. Une note de qualité est ensuite attribuée et chaque paire peut être présentée plusieurs fois avant que l’observateur donne la note de la qualité. L’observateur doit noter la qualité des deux présentations. Dans cette méthode, les observateurs notent la qualité de la vidéo présentée au moyen d’un dispositif coulissant qu’ils déplacent dans un sens, ou dans l’autre, en utilisant une échelle d’appréciation subjective (Excellente (Excellent), Bonne (Good), Assez Bonne (Fair), Médiocre (Poor), Mauvaise (Bad)) liée à une échelle de valeurs allant de 0 à 100.
Les figures suivantes montrent l’échelle, le dispositif utilisé pour la mesure de la qualité et l’illustration de la méthode DSCQS.
Figure 5 : Illustration de la méthode DSCQS. Les versions A et B sont présentées deux fois
Figure 6 : Exemple d’échelle de notation continue de la qualité pour évaluation DSCQS
La méthode DSIS consiste, à présenter aux observateurs les vidéos dans un ordre particulier : d’abord la référence (clairement identifiée), puis seulement après la version dont la qualité est à évaluer. Ensuite l’observateur doit noter la qualité de la deuxième version par rapport à la première version (la référence).
Les laboratoires utilisent des échelles des notes entre un (1) et cent (100), pour quantifier la
Figure 7 : Un exemple d’échelle de catégories de qualité visuelle
III.3. Les méthodes comparatives
Les images de référence et dégradée sont présentées en même temps sur des écrans similaires et sont jugées soit en donnant une note à chaque image soit en faisant une comparaison entre les deux.
La popularité de méthodes comparatives a baissé, principalement en raison de son échec dans l’information de distance significative fournie entre deux stimulus.
Figure 8 : Une échelle comparative de qualité visuelle
IV. Les méthodologies d’évaluation objective
Les méthodologies d’évaluation subjectives étant trop longues, chères et difficile à appliquer d’où l’idée apparue depuis plus de 20 ans de trouver une mesure objective pour la qualité fidèle à la mesure subjective.
Différentes métriques objectives ont été proposées, nous citons ici les plus connus :
Dans [22], Daly et al. proposent un critère objectif de qualité d’images intégrant quelques propriétés du SVH. En réalité, ce critère est une extension du “Visual Difference Predicator” de Daly (proposé en 1993) pour les images à grande échelle dynamique (High Dynamic Range : HDR). Les images HDR se distinguent des images numériques classiques par leur reproduction précise de la quasi-totalité des couleurs présentes dans une image de scène naturelle (de l’ordre des millions). Le principe du critère de Daly et al. (appelé HDR VDP) est présenté ci-dessous.
Le HDR VDP modélise tout d’abord l’œil humain et la rétine à l’aide de l’OTF (Optical Transfer Function), d’une fonction non linéaire de l’amplitude des réponses du SVH aux stimuli et la CSF. Le filtrage de l’image par l’OTF représente la diffusion de la lumière dans la cornée, le cristallin et la rétine. La compression non linéaire de l’amplitude des réponses du SVH simule la réponse non linéaire des photorécepteurs à leur stimulation par la lumière. Finalement, l’image est filtrée par la CSF.
Ensuite, le HDR VDP modélise le cortex visuel et l’effet de masquage. Durant cette phase, les deux images sont décomposées en canaux spatio-directionnels et comparées. Enfin, une série de traitements subis par les deux images résulte en une “carte de probabilités d’erreur” qui génère une note de qualité. Ces traitements sont : la décorrélation entre l’effet de masquage et la phase du signal, l’application d’une fonction psychométrique et la combinaison pondérée des probabilités d’erreur à travers tous les canaux.
Dans [22], des tests d’évaluation de la qualité visuelle sont menés pour calibrer le HDR VDP et non pas pour évaluer ses performances : nous ne disposons donc pas de matière suffisante pour juger si les notes fournies par le HDR VDP corrèlent bien avec les notes subjectives de qualité.
Gunawan et Ghanbari [23], présentent un critère objectif de qualité d’images et de vidéos avec référence réduite. Ce critère analyse les effets de blocs et le flou dans l’image (ou vidéo) de référence et dans l’image (ou vidéo) dégradée et attribue à cette dernière une note de qualité. Cette analyse, basée sur l’amplitude des harmoniques fréquentielles, permet la détection et la localisation de ces deux types de dégradations. En effet, les effets de blocs produisent un signal pseudo-périodique qui génère des harmoniques dans le domaine fréquentiel : l’importance de ces harmoniques est proportionnelle à celle des effets de blocs. Le critère commence par chercher le gradient de l’image qui est calculé par le filtrage de l’image par un filtre de Sobel 3x3. Ensuite, ce gradient est décomposé en blocs de 32x32 pixels. Une transformée rapide de Fourier (Fast Fourier Transform : FFT) appliquée aux deux images (ou vidéos) permet l’extraction des harmoniques locales. Cette référence réduite peut être interprétée comme une forme d’activité spatiale constituée des contours verticaux et horizontaux de l’image. L’indicateur de qualité est une “carte” (matrice) représentant la différence entre l’intensité et la position des harmoniques locales dans chacune des deux versions de l’image (ou vidéo). La différence peut être positive c’est-à-dire qu’il y a eu une
augmentation de l’activité spatiale (due notamment à l’apparition des effets de blocs) ou négative c’est-à-dire qu’il y a eu une diminution de l’activité spatiale (due à la perte de détails causée par le flou). Finalement, la note de qualité est obtenue en moyennant les gains et les pertes calculés séparément.
Les tests effectués par Gunawan et Ghanbari ont montré une bonne corrélation entre les notes de leur critère et les notes subjectives. Le critère s’est montré efficace en détectant les effets de blocs et le flou dans la partie uniforme de l’image et en les négligeant dans la partie fortement texturée. En effet, la présence de texture dissimule ce type de dégradations et les rend moins gênantes. Mais l’application de ce critère sur un nombre limité d’images n’est pas suffisante pour évaluer ses performances.
Le critère de Wang et Bovik appelé UIQI (Universal Image Quality Index ) fait partie des critères généralistes de qualité. En effet, l’UIQI est indépendant des conditions d’observation des images et de leur contenu. De plus, son implémentation est facile et il peut être appliqué à différents types d’images (d’où l’appellation “universal”). L’UIQI mesure la décorrélation entre l’image originale et l’image dégradée et la dégradation de la composante de luminance et du contraste entre les deux versions de l’image. Le produit de ces trois mesures donne la note finale de qualité. Les mesures sont faites de la manière suivante : une “fenêtre glissante” est appliquée au coin supérieur gauche de l’image puis cette fenêtre est déplacée d’un pixel horizontal et vertical jusqu’`a atteindre le coin inférieur droit de l’image. La note de qualité du contenu de la fenêtre est calculée à chaque étape et la moyenne de toutes ces notes donne la note de qualité finale de toute l’image.
Une autre approche est celle de Wang et al. se nome la SSIM (Structural SIMilarity) [19]. L’idée principale de la SSIM est de mesurer la similarité de structure entre deux images, plutôt qu’une différence pixel à pixel. L’hypothèse sous-jacente est que l’œil humain est plus sensible aux changements dans la structure de l’image. Cette approche ne repose pas sur une modélisation du système visuel humain, mais elle prend en compte des spécificités des images auxquelles il est sensible. Les images sont fortement structurées, c’est-à-dire que les pixels d’une image sont très dépendants les uns des autres, et en particulier lorsqu’ils sont proches les uns des autres. Ces structures jouent un rôle important dans la perception de la scène. Par conséquent, une modification de la structure de l’image impacte la perception que l’on a de cette image. Toutefois, le calcul de similarité ne se limite pas seulement à la comparaison des
structures entre les images, mais aussi les différences de luminance et de contraste entre les deux images sont également évaluées. La luminance et le contraste jouent effectivement un rôle important dans la perception.
Dans la continuité de la SSIM, d’autres méthodes basées sur les erreurs structurelles ont été proposées. On peut citer la SSIM multi-échelle (MS-SSIM multi-scale SSIM) également proposée par Wang et al. Dans [20]. Cette méthode reprend les concepts de la SSIM mais les applique à une approche multi-résolution. Les niveaux de résolutions sont calculés à partir des images de départ par filtrage passe-bas et sous-échantillonnage.
Teo et Heeger proposent une modélisation prenant en compte la PSF (Point Spread
Function), l’effet de masquage de luminance (ou adaptation à la luminance), la décomposition
multi-canal, la normalisation du contraste. La décomposition est effectuée selon une pyramide hexagonale avec des filtres QMF (Quadrature Mirror Filter) selon quatre résolutions spatiales et six orientations. L’effet de masquage est modélisé par une normalisation du contraste et une saturation de la réponse.
Watson a proposé un modèle dans le domaine DCT (Discrete Cosine Transform) [18]. Même si ce modèle ne permet pas de sortir directement des cartes de distorsions, une simple modification de l’ordre des cumuls d’erreurs permet d’obtenir une carte de distorsions au niveau bloc. Ce modèle repose sur la transformée DCT 8 × 8 couramment utilisée en traitement d’image et en compression vidéo. Contrairement aux autres méthodes citées, cette méthode décompose le spectre en 64 sous-bandes uniformes. Après la transformée DCT par bloc, des valeurs de contraste sont calculées par sous-bande, un seuil de visibilité est construit pour chaque coefficient de chaque sous-bande et cela dans chaque bloc en utilisant la sensibilité de base de la sous-bande.
Les sensibilités de base de chaque sous-bande sont déduites empiriquement. Les seuils sont corrigés en fonction du masquage de luminance et du masquage de texture. Les erreurs dans chaque sous-bande sont pondérées par les seuils de visibilité correspondants, puis cumulées par des sommations de Minkowski.
Plusieurs auteurs ont développé des métriques de qualité reposant sur une modélisation du système visuel humain, On peut citer :
Van den Branden Lambrecht a proposé plusieurs métriques de qualité. Ces métriques sont basées sur des modèles multi-canaux du SVH [33]. La métrique, appelée MPQM (Moving Picture Quality Metric) [24], est basée sur :
une définition locale du contraste,
une décomposition spatiale utilisant des filtres de Gabor, deux canaux liés à l’aspect temporel (transient et sustained), une CSF spatio-temporelle,
un modèle de masquage de contraste intra-canal.
Une version couleur du MPQM utilisant un espace couleur basé sur la théorie des signaux antagonistes a été proposée dans [25]. Une méthode moins complexe a aussi été proposée sous le nom NVFM (Normalization Video Fidelity Metric), cette méthode utilise, entre autres, une décomposition pyramidale orientée plutôt que des filtres de Gabor pour la décomposition spatiale et qui exploite le masquage inter-canal. Ces métriques ont l’avantage de reposer sur une modélisation avancée du système visuel.
Outre la complexité, un inconvénient réside dans l’application de la CSF spatio-temporel qui est une simple pondération des sous-bandes spatio-temporelles. De plus, des questions se posent sur la séparabilité des domaines spatial et temporel de la CSF utilisée. Par ailleurs, le fait que la littérature ne s’accorde pas sur le nombre de canaux temporels est aussi problématique.
La métrique DVQ (Digital Video Quality) de Watson [16,17] est une méthode d’évaluation des vidéos couleurs qui opère dans le domaine transformé (DCT). Le domaine DCT présente un avantage certain du point de vue calculatoire, parce que la DCT est implantée de façon efficace et que la plupart des codeurs vidéo sont basés sur la DCT. Une modélisation en trois dimensions des seuils différentiels de visibilité pour les sous-bandes DCT spatio-temporelles est proposée. Son principe est le suivant : calcul de la DCT de l’image originale et de l’image dégradée, calcul d’un contraste local, application une CSF temporelle, normalisation des résultats par les seuils différentiels de visibilité, enfin calcul du signal d’erreur. La méthode est appliquée à chaque composante après une transformation de l’espace colorimétrique. Dans
cette métrique, un seul canal temporel est considéré. De plus, la question de la séparabilité espace-temps est de nouveau posée.
Miyahara, Kotami et Algazi [26], ont proposé le PQS, Il incorpore les non-linéarités d’entrée, la pondération en fréquences spatiales, et détermine 5 facteurs (F1 à F5) faisant intervenir différents aspects visuels (seuillage visuel, corrélation des distorsions, effets de masquage) qui servent à construire linéairement la mesure de qualité Q. On ne peut pas dire qu’il y ait vraiment une construction basée sur une modélisation systématique et logique du Système Visuel Humain dans la formation de la qualité. En particulier l’aspect, maintenant bien établi, d’une décomposition multibande du signal d’image par le SVH n’est pas pris en compte.
V. Conclusion
Dans ce chapitre nous avons cité les méthodes subjectives et objectives les plus connues dans le domaine de traitement d’image et vidéo. Ces méthodes présentent des avantages et des inconvénients, nous allons citer quelques unes selon les catégories.
Parmi les avantages des méthodes subjectives, nous pourrons citer :
Les résultats obtenus sont valides pour des vidéos compressées ou non ;
Une moyenne des mesures de plusieurs observateurs est un indicateur valide à la qualité globale des vidéos ou images ;
Et comme inconvénients, nous pourrons citer :
Les méthodes et critères de tests sont nombreux ;
De nombreux observateurs doivent être sélectionnés et surveillés ; Exige des conditions de visualisation particulières ;
La complexité générale est énorme et pose surtout des problèmes de temps ;
Ne sont pas appropriées aux applications temps réel et sont très difficiles à mettre en œuvre.
Et pour les méthodes objectives qui sont assez largement utilisés car leur complexité algorithmique est très faible nous citons comme avantage majeur, la facilité de calcul. Et
comme inconvénient, ils reflètent en général assez mal la qualité réelle de la vidéo ou de l’image c'est-à-dire qu’elles ne s'ajustent toujours pas bien avec la perception humaine.
Chapitre II
I. Introduction
Les réseaux de neurones formels sont devenus en quelques années des outils précieux dans des domaines très divers.
Nous expliquerons les principes fondamentaux qui justifient l'intérêt pratique des réseaux de neurones, et nous situerons ces derniers dans la perspective des méthodes classiques de traitement statistique de données.
Il y a des centaines d'exemples nous montrant à la fois combien on peut espérer de la modélisation du système nerveux mais aussi combien il sera difficile d'imaginer et de comprendre les divers aspects des problèmes de perception. Il paraît donc naturel d'essayer de comprendre comment les systèmes biologiques sont capables de telles performances, et si possible, de s'inspirer de leurs principes pour imaginer de nouveaux algorithmes ou de nouvelles machines plus efficaces que ceux dont nous disposons actuellement. D'un point de vue technique, il est clair que seuls les principes seront importants. Il ne sera généralement pas nécessaire, pour modéliser telle ou telle fonction, de simuler toutes les molécules chimiques et les enzymes qu'elle implique.
Les caractéristiques essentielles des réseaux de neurones réels que nous conserverons dans les modèles mathématiques étudiés, concernent le grand nombre de connexions, la non-linéarité des relations entrée-sortie. Ces caractéristiques, même simplifiées, leur confèrent déjà de multiples possibilités en traitement des signaux et des informations.
Premièrement, nous effectuons un survol historique de l’évolution des réseaux de neurones. Ensuite, nous décrivons formellement comment, à partir d’une série de variables explicatives, un réseau de neurones calcule la valeur prédite du processus que l’on tente de modéliser. Nous expliquons le processus d’optimisation des paramètres et la méthodologie liée au choix de la complexité du réseau de neurones.
L’objectif de ce chapitre est multiple : Il s’agit tout d’abord de rappeler les notions fondamentales relatives aux réseaux de neurones ainsi que leurs propriétés mathématiques, puis nous décrivons en détails les concepts fondamentaux (neurone biologique, modélisation simplifiée d’un neurone, type de réseaux, algorithmes d’apprentissage …….).
Nous décrivons les principaux types des réseaux de neurones. Finalement nous détaillerons le type de réseaux de neurones utilisé dans notre thèse les perceptrons multicouches (PMC), et plus particulièrement ces propriétés et sa mise en œuvre. Au long de la première partie de ce chapitre nous avons cherché à éclairer les concepts généraux des réseaux de neurones et détailler d’avantage les notions auxquels nous fait appel pour élaborer notre travail.
L'emploi des réseaux de neurones plutôt que des techniques classiques peut se justifier par les arguments suivants:
Simplicité de mise en œuvre (peu d'analyse mathématique préliminaire) ; Capacité d'approximation universelle prouvée ;
Robustesse par rapport à des défaillances internes du réseau ;
Capacité d'adaptation aux conditions imposées par un environnement quelconque ; Facilité de changer ses paramètres (poids, nombre de neurones cachés, nombre de couches cachées, …) ;
II. Historique
Les premiers à proposer un modèle sont deux bio-physiciens de Chicago, McCulloch et Pitts, qui inventent en 1943 le premier neurone formel qui portera leurs noms (neurone de McCulloch-Pitts). Quelques années plus tard, en 1949, Hebb propose une formulation du mécanisme d'apprentissage, sous la forme d'une règle de modification des connexions synaptiques (règle de Hebb). Cette règle, basée sur des données biologiques, modélise le fait que si des neurones, de part et d'autre d'une synapse, sont activés de façon synchrone et répétée, la force de la connexion synaptique va aller croissant.
De nombreux modèles de réseaux aujourd’hui s’inspirent encore de la règle de Hebb. En 1958, Rosenblatt propose le premier algorithme d’apprentissage, qui permet d’ajuster les paramètres d’un neurone, c’est un réseau de neurones inspiré du système visuel. Il possède deux couches de neurones : une couche de perception et une couche liée à la prise de décision.
C’est le premier système artificiel capable d’apprendre par expérience. Dans la même période, le modèle de l’Adaline (Adaptive Linar Element) a été présenté par B. Widrow et Hoff. Ce modèle sera par la suite le modèle de base des réseaux multicouches. En 1969, Minsky et Papert publient le livre « Perceptrons » dans lequel ils utilisent une solide argumentation mathématique pour démontrer les limitations des réseaux de neurones à une seule couche. Ce livre aura une influence telle que la plupart des chercheurs quitteront le champ de recherche sur les réseaux de neurones. Jusqu’en 1972, où T. Kohonen présente ses travaux sur les mémoires associatives et propose des applications à la reconnaissance de formes. En 1982, Hopfield propose des réseaux de neurones associatifs et l’intérêt pour les réseaux de neurones renaît chez les scientifiques. En 1986, Rumelhart, Hinton et Williams publient, l’algorithme de la rétro-propagation de l’erreur qui permet d’optimiser les paramètres d’un réseau de neurones à plusieurs couches. À partir de ce moment, la recherche sur les réseaux de neurones connaît un essor fulgurant et les applications commerciales de ce succès académique suivent au cours des années 90.
Aujourd’hui, on retrouve les réseaux de neurones solidement implantés dans diverses industries, dans les milieux financiers pour la prédiction des fluctuations de marché, en pharmaceutique pour analyser le « QSAR » (Quantitative Structure-Activity Relationship) de diverses molécules organiques, dans le domaine bancaire pour la détection de fraudes sur les cartes de crédit et le calcul de cotes de crédit, dans les départements de marketing de compagnies de diverses industries pour prévoir le comportement des consommateurs, en aéronautique pour la programmation de pilotes automatiques, etc. Les applications sont nombreuses et partagent toutes un point commun essentiel à l’utilité des réseaux de neurones , les processus pour lesquels on désire émettre des prédictions comportent de nombreuses variables explicatives et surtout, il existe possiblement des dépendances non-linéaires de haut niveau entre ces variables qui, si elles sont découvertes et exploitées, peuvent servir à l’amélioration de la prédiction du processus.
L’avantage fondamental des réseaux de neurones par rapport aux modèles statistiques traditionnels réside dans le fait qu’ils permettent d’automatiser la découverte des dépendances les plus importantes du point de vue de la prédiction du processus.
III. Le neurone Biologique
III.1. La cellule nerveuse
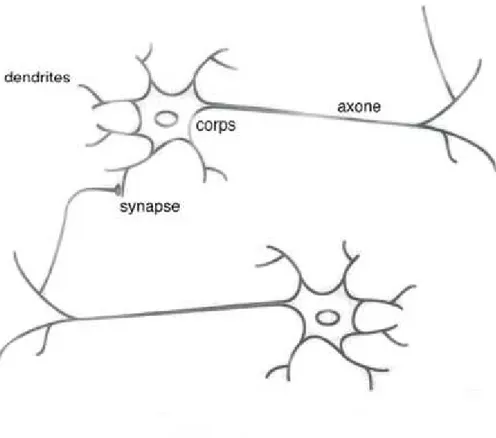
Le neurone biologique (Figure 9) est une cellule vivante spécialisée dans le traitement des signaux électriques. Les neurones sont reliés entre eux par des liaisons appelées axones. Ces axones vont eux mêmes jouer un rôle important dans le comportement logique de l'ensemble. Ces axones conduisent les signaux électriques de la sortie d'un neurone vers l'entrée (synapse) d'un autre neurone. Les neurones font une sommation des signaux reçus en entrée et en fonction du résultat obtenu vont fournir un courant en sortie.
Le type le plus commun de neurone biologique se présente comme une cellule dont le corps est doté de deux types de prolongements :
- Des ramifications courtes et buissonnantes: les dendrites. - Une longue fibre qui se termine par une arborisation: l’axone.
Ces prolongements permettent au neurone d’établir des connexions avec d’autres cellules nerveuses. L’élément le plus frappant à l’observation microscopique du tissu nerveux est la densité de connexions: Chaque neurone communique, en moyenne, avec 104 autres neurones. C’est cette densité de connexion, cette importance des communications, qui fait toute la puissance du système nerveux. Le cerveau humain comporte de l’ordre de 1011 neurones, soit environ 1015 connexions.
Les dendrites constituent en quelque sorte les points d’entrée du neurone: c’est par les dendrites qu’il reçoit de l’information provenant d’autres neurones. Après traitement, l’information est propagée vers les neurones suivants, via l’axone. Les terminaisons de l’axone forment des connexions (synapses) avec d’autres neurones. Le fonctionnement du neurone met en jeu des phénomènes chimiques et électriques. La figure suivante présente un neurone biologique.
III.2. Fonctionnement des neurones
Les réseaux de neurones formels sont à l'origine d’une tentative de modélisation mathématique du cerveau humain. Du point de vu fonctionnel, il faut considérer, pour simplifier le neurone comme une entité polarisée, c'est-à-dire que l'information ne se transmet que dans un seul sens, des dendrites vers l'axone. Pour rentrer un peu dans le détail, le neurone va donc recevoir des informations, venant d'autres neurones, grâce à ses dendrites. Il va ensuite y avoir sommation, au niveau du corps cellulaire, de toutes ces informations, via un potentiel d'action (un signal électrique). Le résultat de l'analyse va transiter le long de l'axone jusqu'aux terminaisons synaptiques. A cet endroit, lors de l'arrivée du signal, des vésicules synaptiques vont venir fusionner avec la membrane cellulaire, ce qui va permettre la libération des neurotransmetteurs (médiateurs chimiques) dans la fente synaptique. Le signal
électrique ne pouvant pas passer la synapse, les neurotransmetteurs permettent donc le passage des informations, d'un neurone à un autre.
Au niveau post-synaptique, sur la membrane dendritique, se trouvent des neurorécepteurs pour les neurotransmetteurs. Suivant leurs type, l'excitabilité du neurone va augmenter ou diminuer, ce qui fera que l'information va se propager ou non.
Les synapses possèdent une sorte de "mémoire" qui leur permet d'ajuster leur fonctionnement. En fonction de leur "histoire", c'est-à-dire de leur activation répétée ou non entre deux neurones, les connexions synaptiques vont donc se modifier.
III.3. Modélisation simplifiée d’un neurone
La modélisation consiste à mettre en œuvre un système de réseau neuronaux sous un aspect non pas biologique mais artificiel, cela suppose que d’après le principe biologique on aura une correspondance pour chaque élément composant le neurone biologique, donc une modélisation pour chacun d’entre eux.
Un neurone formel est un automate défini par : - des entrées qui peuvent être :
• Binaires (-1,1) ou (0,1).
• Réelles.
- Les poids de pondération des entrées .
- La fonction d’activation f du neurone qui définit son état interne en fonction de son entrée, elle peut être :
• Binaire à seuil (généralement, la fonction de Heaviside ou la fonction signe).
• Linéaire à seuil.
On peut simplifier ces données par le schéma suivant :
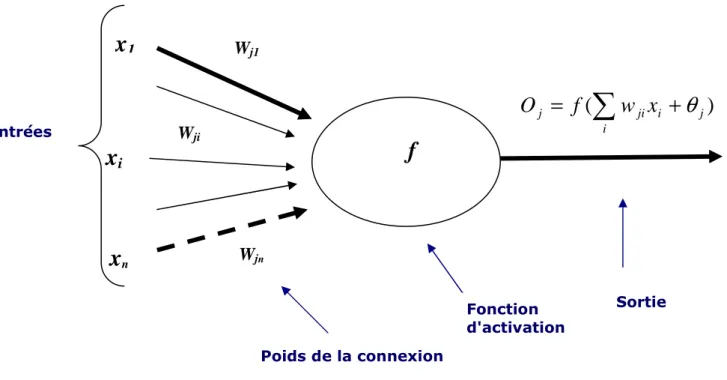
On peut donc, d’après la Figure 10, définir un neurone formel j par les paramètres suivants :
Un ensemble des connexions (ou synapses) dont chacune se caractérise par un poids réel. Le signal xi se trouvant à l’entrée qui est connectée au neurone j , est multiplié
par le poids de la connexion wji, qui est le poids de la connexion dirigée du neurone i
vers le neurone j.
Figure 10 : Neurone Formel j
)
(
∑
+
=
i j i ji jf
w
x
O
θ
Entréesx
nx
i Wjix
1 Wj1 Wjn Poids de la connexion Fonction d'activationf
SortieL’entrée nette de l’unité j :
∑
∑
=
=
=
+
=
n
i
i
ji
n
i
j
i
ji
j
w
x
w
x
net
0
1
θ
w : représente le poids entre les unités i et j ji θj : désigne le seuil d’activation (biais) de l’unité j
où :
wj0 = θj , x0 = +1 et n est le nombre d’entrées.
Le seuil θj propre au neurone j qui est un nombre réel et qui représente la limite à partir de laquelle le neurone s’activera. Ce seuil peut jouer le rôle de poids de la connexion qui existe entre l’entrée fixée à +1 et le neurone j.
Activation de l’unité j ou bien la sortie de l’unité j :
)
(
jj
f
net
o
=
f : Fonction d’activation ou de transfert, la fonction sigmoïde est la plus utilisée.
IV. caractéristiques d’un réseau
En générale le réseau est caractérisé par :
Architecture qui dépend de type d’interconnexion. Choix de fonction d’activation.
IV.1. Les architectures usuelles des réseaux des neurones
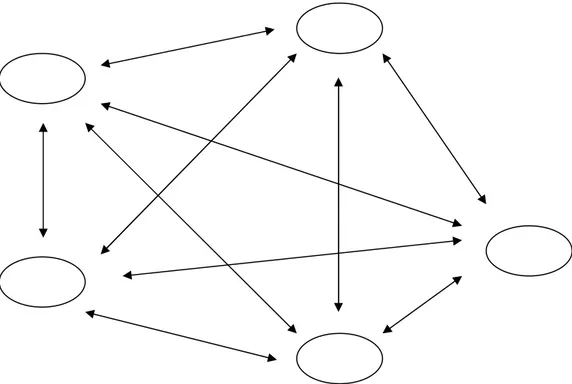
Les neurones sont connectées entre eux de diverses manières : réseaux totalement
interconnectées, réseaux à couches (ou réseaux de type feedforward), et réseaux récurrents. Les figures suivantes montrent ces architectures :
Couche d’entrée Couche(s) cachée(s) Couche de sortie
Figure 12 : Réseau à couches