Acceleration of the retrieval of past experiences in Case Based Reasoning : application for preliminary design in Chemical Engineering
6
0
0
Texte intégral
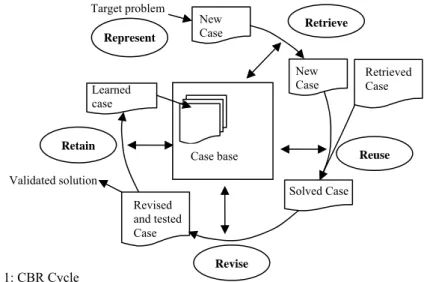
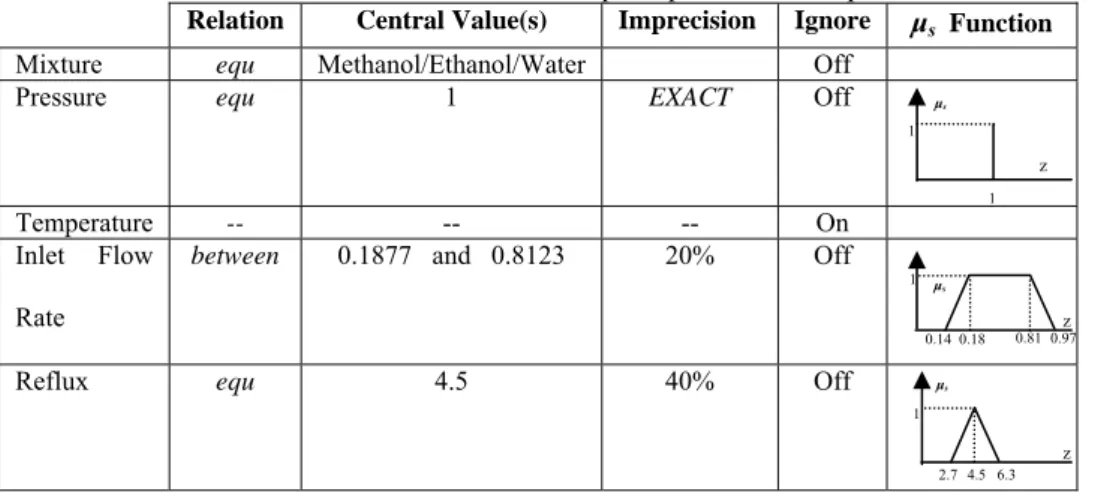
Figure
Documents relatifs
