Mécanismes cryptographiques pour la génération de clefs et l'authentification.
175
0
0
Texte intégral
Figure


+3

Outline
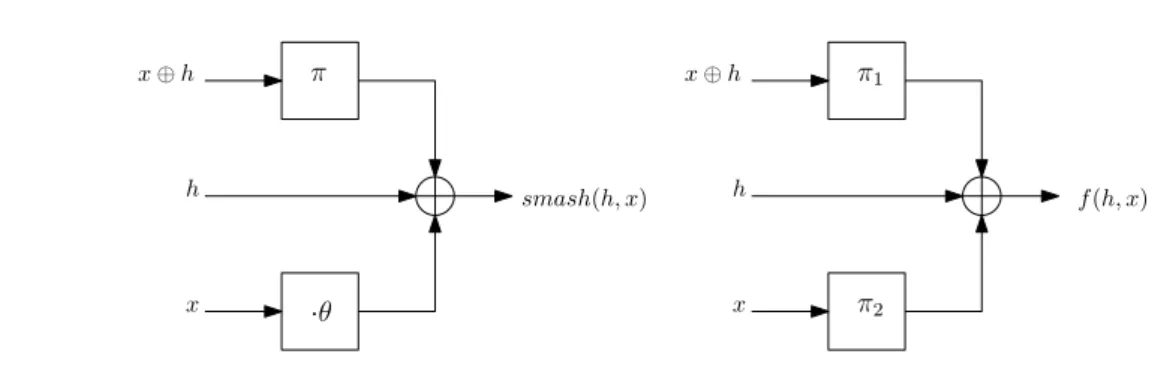
Une attaque en collision contre toutes les versions précédentes de SMASH
Optimalité de la preuve et attaques
Attaque connue en seconde préimage contre le mode cascade
Mode cascade avec tramage
Attaque contre le mode cascade sans tramage
Attaque en seconde préimage contre le mode cascade avec tramage
Attaque contre une famille de fonctions de hachage universelle à sens unique
Documents relatifs