Amélioration de la méthode d'échantillonnage en deux cycles et application à l'estimation du total de la population
70
0
0
Texte intégral
Figure


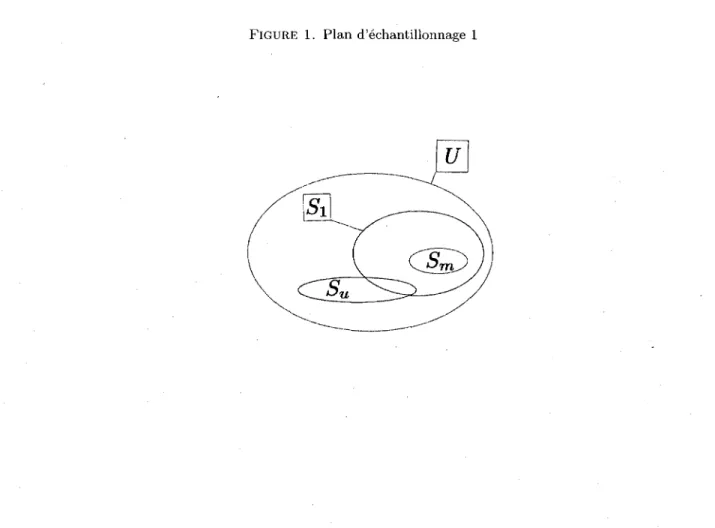

+2
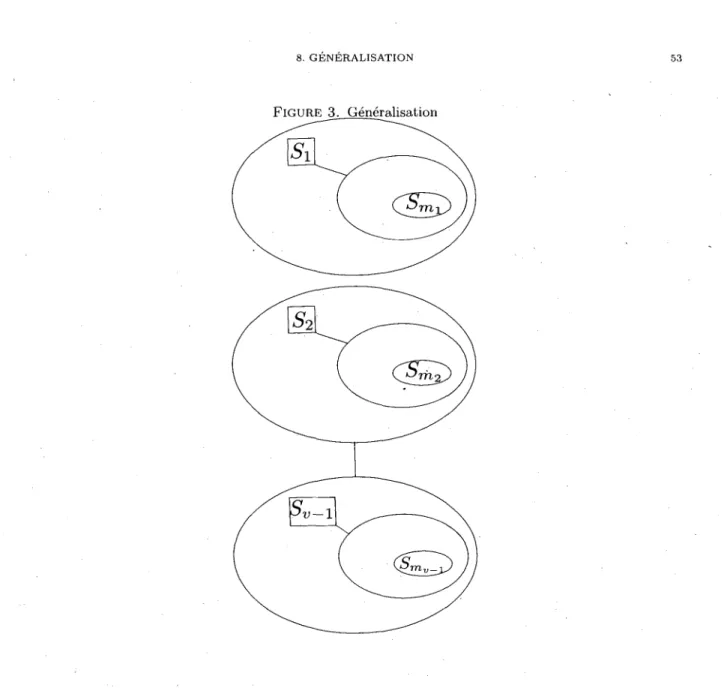
Documents relatifs
