Conception et analyse d'algorithmes parallèles en temps pour l'accélération de simulations numériques d'équations d'évolution
127
0
0
Texte intégral
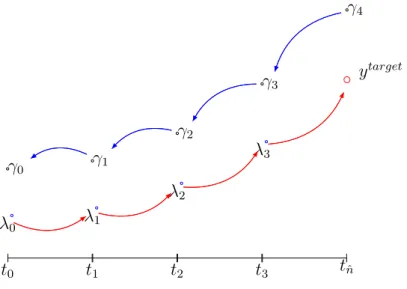
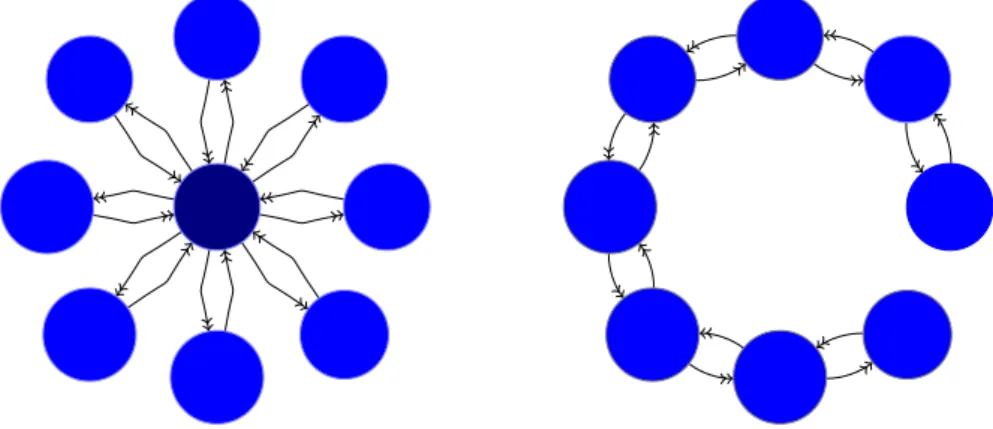
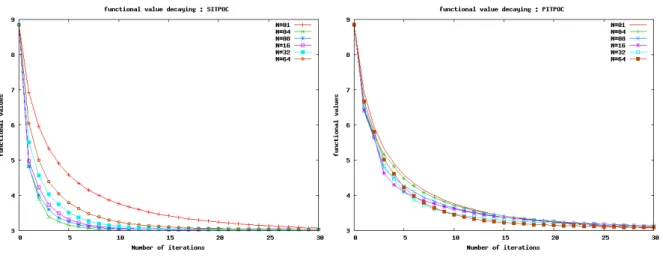
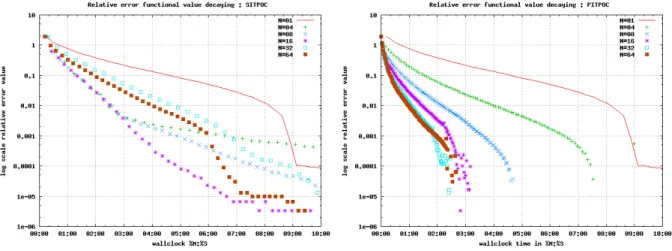
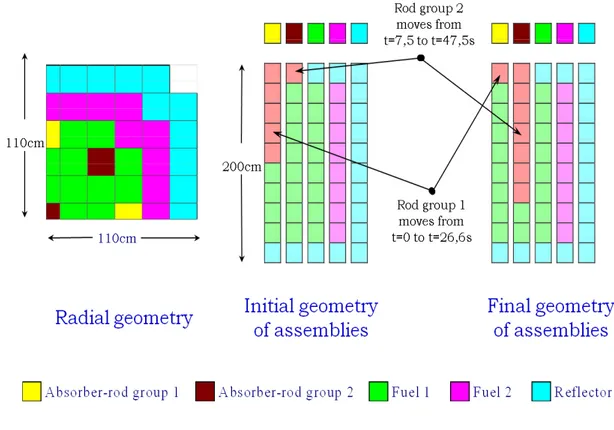
Figure
+7
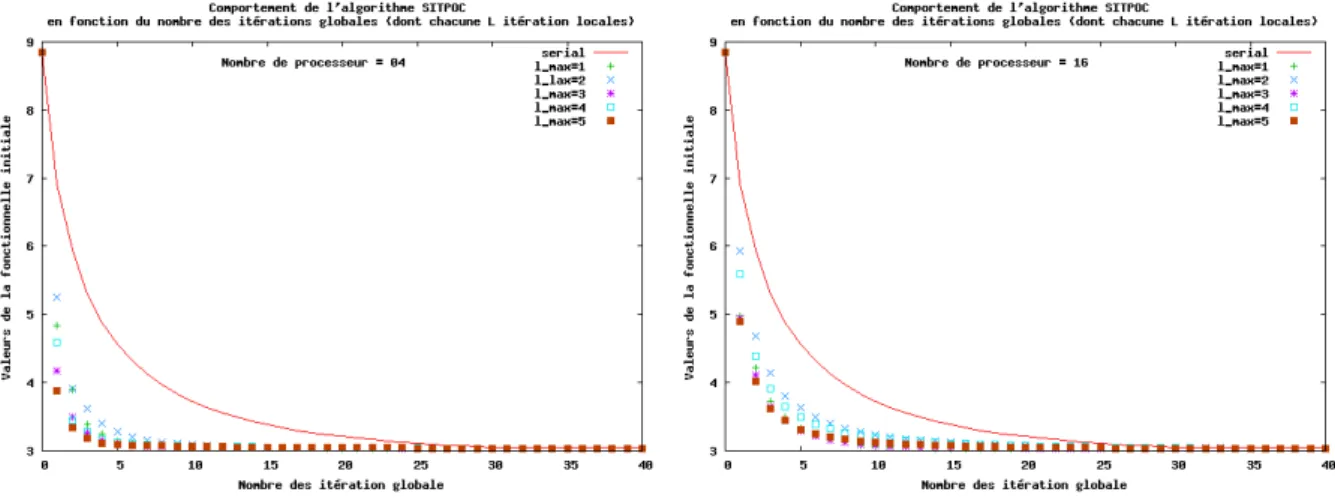
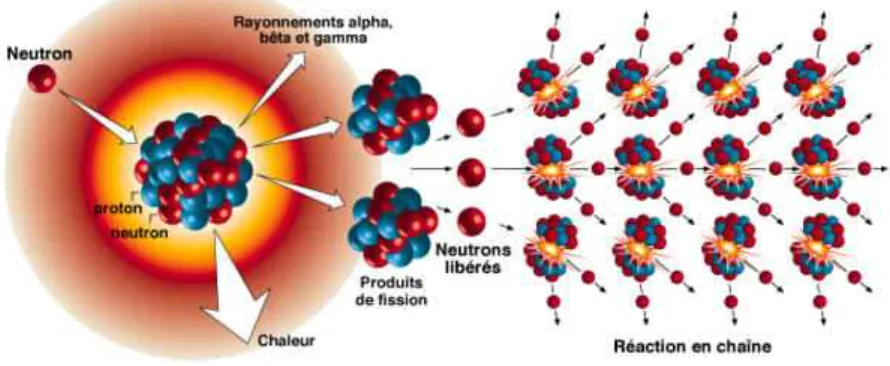

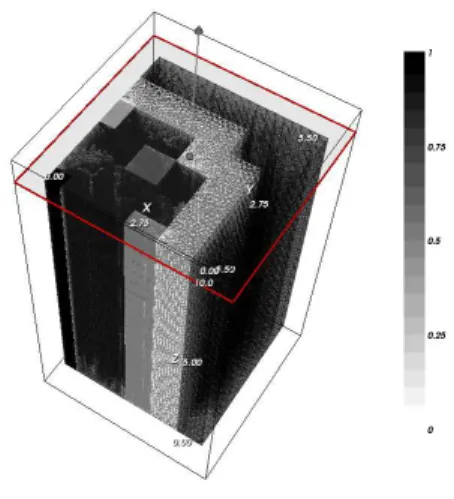
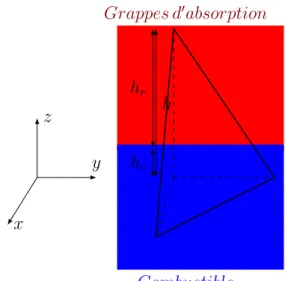
Documents relatifs
