Spatio-temporal thermal-aware scheduling for homogeneous high-performance computing datacenters
15
0
0
Texte intégral
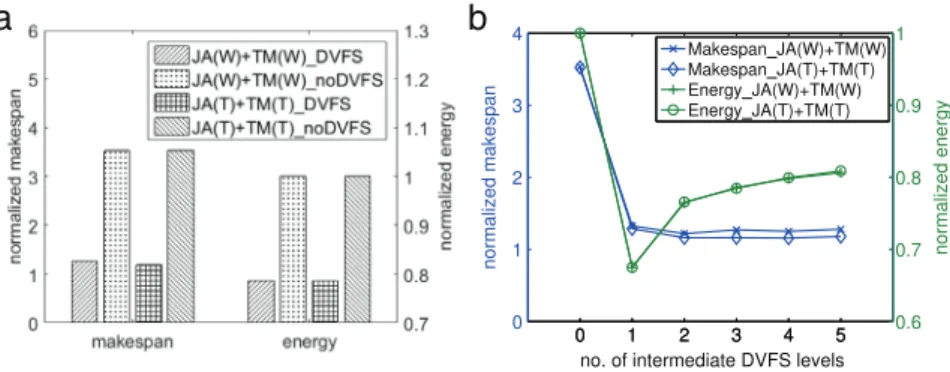
Figure
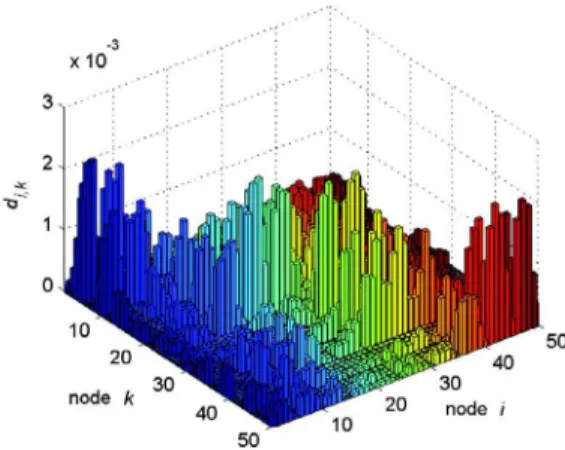
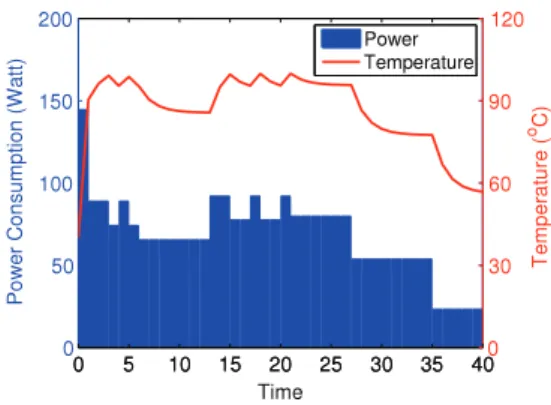

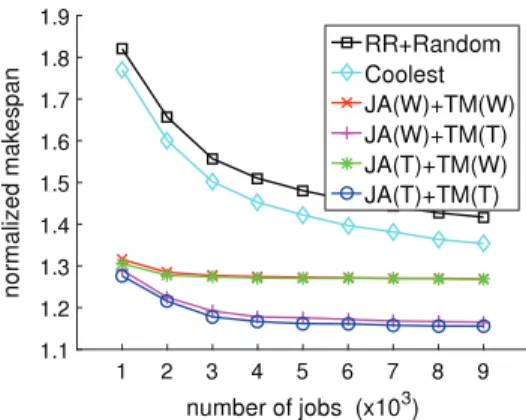
+3
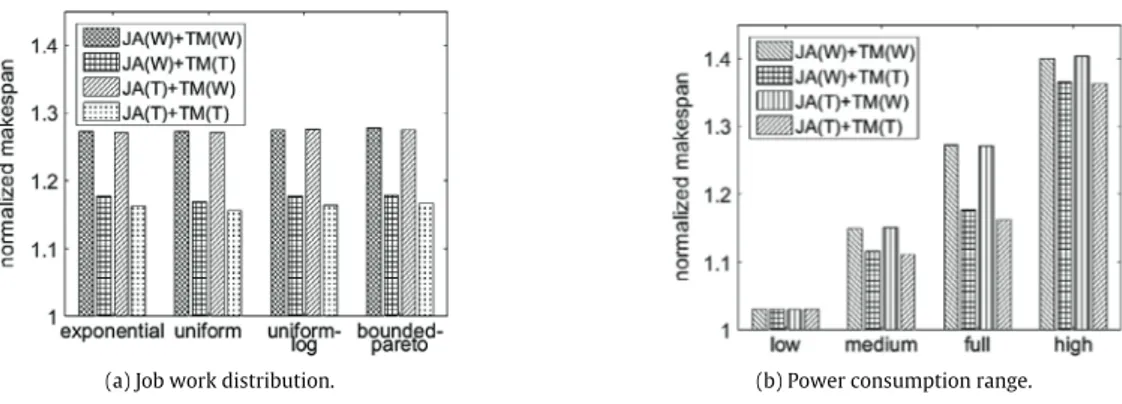
Documents relatifs
