Traitement du langage et systèmes de dialogue pour faciliter l'accès à la justice
Texte intégral
Figure


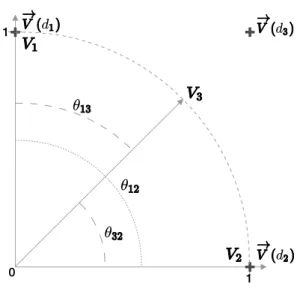

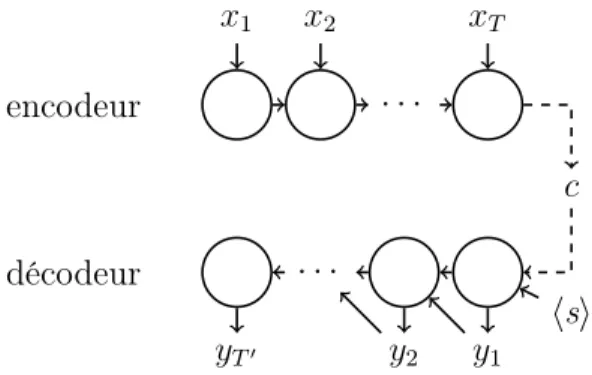
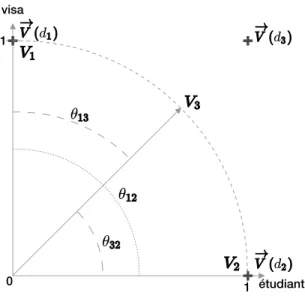
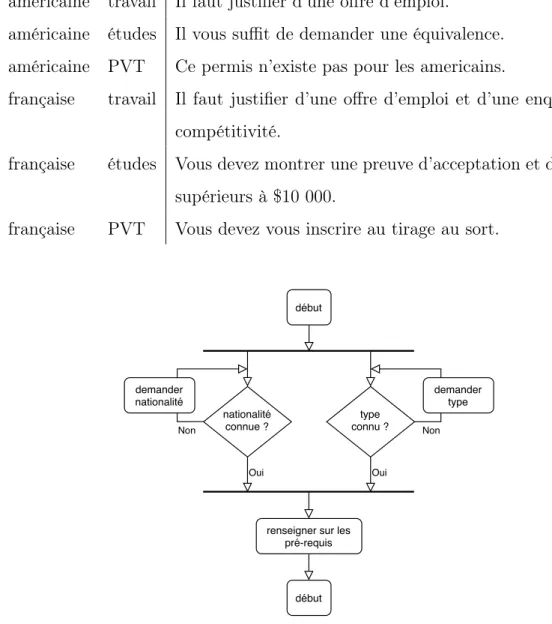


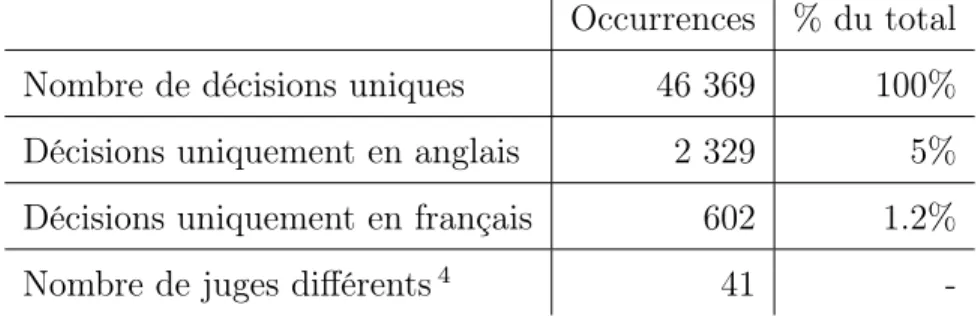
Documents relatifs
Nous avons décrit ici SIRC, un système d’aide à la rédaction de contrats, se fondant sur une étude structurelle et linguistique de contrats et mettant à profit une base de données
Dans ce chapitre, nous avons montré la disponibilité de techniques de traitement numérique du signal pour l’égalisation du canal optique et la compensation du bruit de phase des
Dans cette thèse, nous avons proposé une méthodologie d’ingénierie système (IS) guidée par les modèles (ou Model-Driven Systems Engineering MDSE) avec une spécialisation
Par l’entremise d’une étude de cas, nous avons observé le déroulement de la négociation de 2002-2003 entre la Ville de Montréal et le Syndicat professionnel des scientifiques
l’individu est de plus en plus central comme objet et sujet du droit de la famille privé et du droit social, il nous semble logique de présumer que le droit québécois de la famille
La foi dans le bouddhisme de Nichiren Daishonin ne nous enseigne pas à nous en remettre passivement à un pouvoir extérieur; elle nous apprend plutôt que, grâce à notre prière
Quand nous avons commencé à nous réunir, nous les enfants de disparus, on s’est rendu compte que… à un moment donné dans la vie, chacun avait pensé : "Si ça se trouve mon
À la demande du CONSEIL DES INDUSTRIES BIOALIMENTAIRES DE L'ÎLE DE MONTRÉAL, nous avons procédé à l’examen de l'état des produits et charges du projet. « Réseau Bioalimentaire
