Système de recommandations utilisant une combinaison de filtrage collaboratif et de segmentation pour des données implicites
Texte intégral
Figure
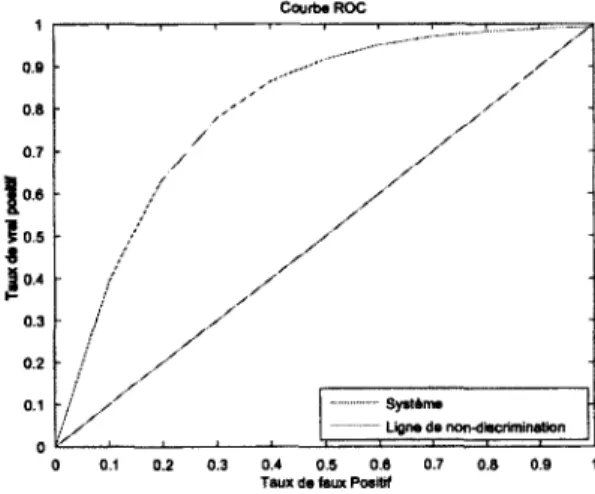


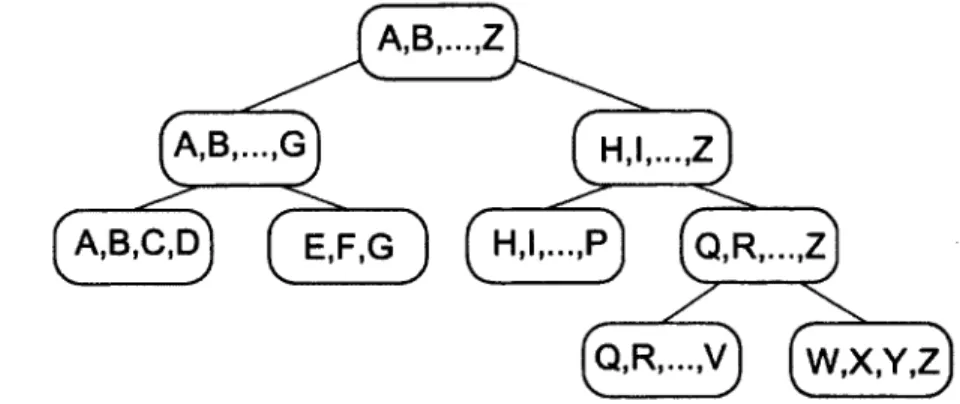
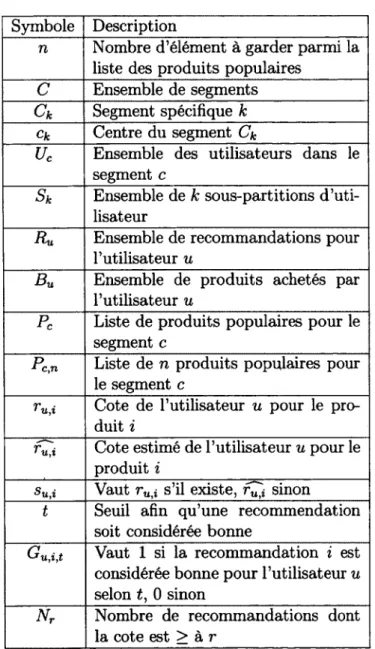
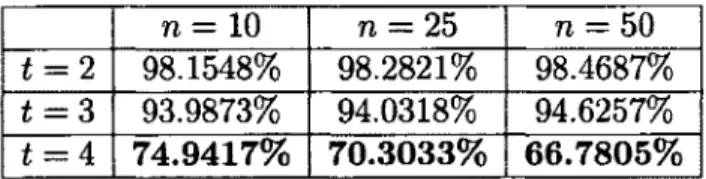
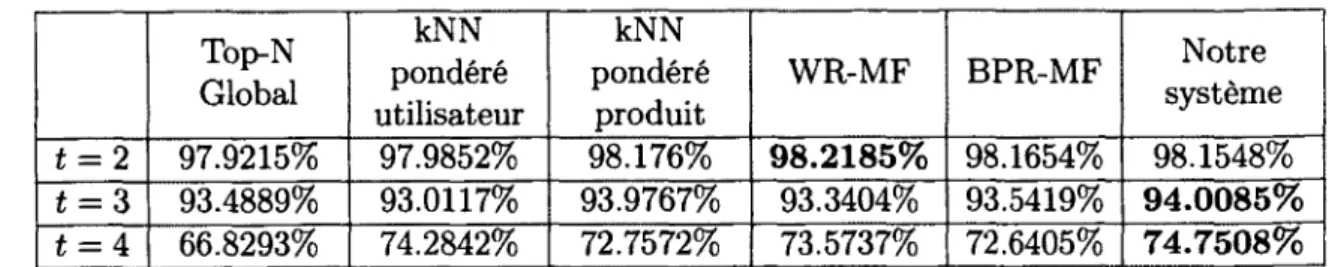
Documents relatifs
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
The workshops will all take place at the Capital Hall level of the Congress Centre: Regression Modelling Strategies (Biostatistics Section) in 1B from 8:30 to 17:00, Selected Topics
Le principe de compétition est illustré avec des masques verticaux et horizontaux. Cette première compétition concerne les neurones représentant une même
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Les membres du groupe de travail se réunissent deux fois, voire plus si nécessaire, pour élaborer, à partir de l’argumentaire scientifique et des propositions
Le module de pré-analyse met en oeuvre un filtre de comptage afin d’étudier en profondeur l’intérêt implicite des utilisateurs : le filtre permet de compter le nombre de fois
Les chorographies, guides et récits de voyage peuvent donc s’avérer être précieux dans le cadre d’études portant sur l’histoire des mentalités, sur l’historiographie
In Figure 6 are displayed boxplots of Monte Carlo and non-stationary Kac-Rice estimators of the average number of crossings of the level 1 C 1 (100) with an increasing time step size
