HAL Id: hal-02606929
https://hal.inrae.fr/hal-02606929
Submitted on 16 May 2020
HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
l’estimation d’un modèle quelconque et son utilisation
en prédiction
Benjamin Renard
To cite this version:
Benjamin Renard. BaM ! (Bayesian Modeling): Un code de calcul pour l’estimation d’un modèle quelconque et son utilisation en prédiction. [Rapport de recherche] irstea. 2017, pp.90. �hal-02606929�
PROGRAMME MEEM (DGPR / SRNH) - IRSTEA 2017
Connaissance et prévention des risques naturels et hydrauliques
Ces travaux bénéficient du soutien du Ministère chargé de l’environnement, de l’énergie et de la mer
par décision de subvention n°2102049246
DECEMBRE 2017
Benjamin RENARD
Irstea, Unité de recherche « Hydrologie-Hydraulique » (HHLY)
5 rue de la Doua 69100 Villeurbanne
www.irstea.fr
BaM ! (Bayesian Modeling)
Un code de calcul pour
l’estimation d’un modèle
quelconque et son utilisation
en prédiction
- 3 -
Table des matie res
I. INTRODUCTION ________________________________________________________________ 7
I.1 CONTEXTE : LE LOGICIEL BARATINAGE ET SON EVOLUTION ___________________________________ 7 I.2 LA COURBE DE TARAGE EST UN MODELE COMME UN AUTRE ___________________________________ 7 I.3 OBJECTIFS ET PLAN DU RAPPORT _____________________________________________________ 7
II. PRINCIPES GENERAUX __________________________________________________________ 9
II.1 L’OBJET « MODELE » ____________________________________________________________ 9 II.2 ESTIMATION _________________________________________________________________ 12
II.2.1 PRINCIPE GENERAL ____________________________________________________________ 12 II.2.2 MODELE POUR LES ERREURS STRUCTURELLES __________________________________________ 13 II.2.3 MODELE POUR LES ERREURS SUR LES DONNEES _________________________________________ 14 II.2.4 INFERENCE BAYESIENNE ________________________________________________________ 16 II.3 PREDICTION __________________________________________________________________ 18
III. EXEMPLES D’APPLICATION _____________________________________________________ 21
III.1 COURBES DE TARAGE :BARATIN ___________________________________________________ 21 III.1.1 DONNEES ET MODELE _________________________________________________________ 21 III.1.2 RESULTATS _________________________________________________________________ 22 III.2 COURBES DE TARAGEA DOUBLE NIVEAU : LE MODELE SFD(STAGE-FALL-DISCHARGE) ______________ 25 III.2.1 DONNEES ET MODELE _________________________________________________________ 25 III.2.2 RESULTATS _________________________________________________________________ 26 III.3 REGRESSION LINEAIRE MULTIPLE ___________________________________________________ 28
III.3.1 DONNEES ET MODELE _________________________________________________________ 28
III.3.2 RESULTATS _________________________________________________________________ 29 III.4 MODELE HYDROLOGIQUE :GR4J __________________________________________________ 31 III.4.1 DONNEES ET MODELE _________________________________________________________ 31 III.4.2 RESULTATS _________________________________________________________________ 32 III.5 TRANSPORT SEDIMENTAIRE ______________________________________________________ 35
III.5.1 DONNEES ET MODELE _________________________________________________________ 35
III.5.2 RESULTATS _________________________________________________________________ 36 III.6 ORTHORECTIFICATION __________________________________________________________ 38 III.6.1 DONNEES ET MODELE _________________________________________________________ 38 III.6.2 RESULTATS _________________________________________________________________ 42 III.7 EXEMPLES AVEC DIFFERENTS TYPES D’ERREURS AFFECTANT LES DONNEES ________________________ 44 III.7.1 DONNEES ET MODELE _________________________________________________________ 44
III.7.2 RESULTATS _________________________________________________________________ 45
IV. CONCLUSIONS ET PERSPECTIVES ________________________________________________ 48
IV.1 RESUME DES ACTIONS ENTREPRISES CETTE ANNEE _______________________________________ 48 IV.2 INCLUSION D’AUTRES MODELES ____________________________________________________ 48 IV.3 REFLEXION A MENER SUR LES MODELES D’ERREURS SUR LES OBSERVATIONS _____________________ 49
- 4 -
IV.4 DEVELOPPEMENT D’UNE INTERFACE GRAPHIQUE ________________________________________ 49
V. ANNEXE 1 : FORMALISATION MATHEMATIQUE ____________________________________ 51
V.1 NOTATIONS __________________________________________________________________ 51 V.2 MODELE D’ERREURS ____________________________________________________________ 51 V.2.1 ERREURS STRUCTURELLES _______________________________________________________ 51 V.2.2 ERREURS SUR LES DONNEES ______________________________________________________ 51 V.3 VRAISEMBLANCE ______________________________________________________________ 52
V.3.1 CAS OU LES VARIABLES D’ENTREE SONT SANS INCERTITUDE _________________________________ 52
V.3.2 CAS GENERAL _______________________________________________________________ 52 V.4 DISTRIBUTION A PRIORI __________________________________________________________ 53 V.4.1 CAS OU LES VARIABLES D’ENTREE SONT SANS INCERTITUDE _________________________________ 53 V.4.2 CAS GENERAL _______________________________________________________________ 53 V.5 DISTRIBUTION A POSTERIORI ______________________________________________________ 53 V.5.1 CAS OU LES VARIABLES D’ENTREE SONT SANS INCERTITUDE _________________________________ 53
V.5.2 CAS GENERAL _______________________________________________________________ 54 V.6 ALGORITHME MCMC ___________________________________________________________ 54
VI. ANNEXE 2 : PILOTAGE DE L’EXECUTABLE BAM.EXE _________________________________ 55
VI.1 PRINCIPE GENERAL ____________________________________________________________ 55 VI.2 CONTROLEUR GENERAL _________________________________________________________ 55 VI.3 CONTROLE DES ACTIONS QUE BAM DOIT EXECUTER ______________________________________ 56 VI.4 CONFIGURATION DU MODELE A ESTIMER _____________________________________________ 56 VI.4.1 DEFINITION DU MODELE ET SPECIFICATION DES A PRIORI __________________________________ 56
VI.4.2 INFORMATIONS COMPLEMENTAIRES REQUISES PAR LE MODELE ______________________________ 59 VI.5 CONFIGURATION DE L’INFERENCE __________________________________________________ 60 VI.5.1 CONFIGURATION DES DONNEES ___________________________________________________ 60 VI.5.2 SPECIFICATION DES MODELES D’ERREURS STRUCTURELLES _________________________________ 61 VI.6 CONFIGURATION DES ACTIONS DE L’EXECUTABLE ________________________________________ 62 VI.6.1 SIMULATIONS MCMC _________________________________________________________ 62
VI.6.2 POSTPROCESSING DES SIMULATIONS MCMC(“COOKING”) ________________________________ 62
VI.6.3 RÉSUMÉ DES SIMULATIONS MCMC ________________________________________________ 63
VI.6.4 ANALYSE DES RESIDUS _________________________________________________________ 63 VI.6.5 PREDICTION ________________________________________________________________ 64
VII. ANNEXE 3 : DESCRIPTION DES MODELES DISPONIBLES ______________________________ 67
VII.1 BARATIN __________________________________________________________________ 68 VII.1.1 OBJECTIF _________________________________________________________________ 68
VII.1.2 DESCRIPTION ______________________________________________________________ 68
VII.1.3 FORMULATION MATHEMATIQUE _________________________________________________ 68 VII.1.4 EXEMPLES DE FICHIERS DE CONFIGURATION __________________________________________ 69 VII.2 SFD(STAGE-FALL-DISCHARGE) ___________________________________________________ 70 VII.2.1 OBJECTIF _________________________________________________________________ 70 VII.2.2 DESCRIPTION ______________________________________________________________ 70 VII.2.3 FORMULATION MATHEMATIQUE _________________________________________________ 70
VII.2.4 EXEMPLES DE FICHIERS DE CONFIGURATION __________________________________________ 70 VII.3 REGRESSION LINEAIRE MULTIPLE __________________________________________________ 73
- 5 -
VII.3.1 OBJECTIF _________________________________________________________________ 73
VII.3.2 DESCRIPTION ______________________________________________________________ 73
VII.3.3 FORMULATION MATHEMATIQUE _________________________________________________ 73 VII.3.4 EXEMPLES DE FICHIERS DE CONFIGURATION __________________________________________ 74 VII.4 GR4J _____________________________________________________________________ 75 VII.4.1 OBJECTIF _________________________________________________________________ 75 VII.4.2 DESCRIPTION ______________________________________________________________ 75
VII.4.3 FORMULATION MATHEMATIQUE _________________________________________________ 75
VII.4.4 EXEMPLES DE FICHIERS DE CONFIGURATION __________________________________________ 75 VII.5 TRANSPORT SEDIMENTAIRE ______________________________________________________ 78 VII.5.1 OBJECTIF _________________________________________________________________ 78 VII.5.2 DESCRIPTION ______________________________________________________________ 78 VII.5.3 FORMULATION MATHEMATIQUE _________________________________________________ 78 VII.5.4 EXEMPLES DE FICHIERS DE CONFIGURATION __________________________________________ 79 VII.6 ORTHORECTIFICATION _________________________________________________________ 82
VII.6.1 OBJECTIF _________________________________________________________________ 82 VII.6.2 DESCRIPTION ______________________________________________________________ 82 VII.6.3 FORMULATION MATHEMATIQUE _________________________________________________ 82 VII.6.4 EXEMPLES DE FICHIERS DE CONFIGURATION __________________________________________ 84
- 7 -
I. Introduction
I.1 Contexte : le logiciel BaRatinAGE et son évolution
La méthode d’estimation de courbes de tarage BaRatin (Bayesian Rating curve, Le Coz et al. 2014) a été développée ces dernières années, en particulier dans le cadre de la convention liant le SCHAPI et Irstea. Le code de calcul de BaRatin est actuellement diffusé accompagné de son interface graphique BaRatinAGE1, et des sessions de formation sont régulièrement organisées pour accompagner les utilisateurs dans leur prise en main du logiciel et des aspects méthodologiques sous-jacents. A ce jour, BaRatinAGE compte plus d’une centaine d’utilisateurs déclarés, issus des services de l’état (DREAL, SPC, agences de l’eau, etc.), d’entreprises privées et de bureaux d’étude (CNR, EDF, Log-Hydro, etc.), ainsi que d’universités ou de services hydrométriques en France et à l’étranger (universités de Grenoble, de Waterloo (Canada), de Washington (US), de Brasilia (Brésil), USGS (US), Regional Councils en Nouvelle-Zélande, etc.).
BaRatinAGE ne considère actuellement que le cas des courbes de tarage dites simples, pour lesquelles le débit est déterminé à partir de la hauteur d’eau seulement. Les récents travaux de thèse de Valentin Mansanarez (2016) ont permis de mettre en place des modèles de courbes de tarage dites complexes, pour lesquelles le débit ne dépend pas uniquement de la hauteur, mais également d’autres variables d’entrée. Trois cas ont été étudiés : l’hystérésis hydraulique (variable supplémentaire : le gradient limnimétrique), l’influence aval variable (variable supplémentaire : une seconde hauteur auxiliaire), et les détarages morphodynamiques (variable supplémentaire : la période de validité de la courbe).
Nous souhaitons à terme intégrer ces modèles de courbes de tarage complexes au sein du logiciel BaRAtinAGE. Cette intégration n’est néanmoins pas triviale : en effet, le code de calcul BaRatin est actuellement restreint aux modèles possédant une unique variable d’entrée (la hauteur) et une unique variable de sortie (le débit). Il est donc nécessaire de généraliser ce code de calcul pour qu’il puisse gérer des modèles possédant plusieurs variables d’entrée.
I.2 La courbe de tarage est un modèle comme un autre
Il nous est apparu qu’une partie non négligeable du code de calcul de BaRatin est en fait totalement indépendante du modèle de courbe de tarage utilisé. Ceci implique qu’il pourrait en principe s’appliquer (moyennant quelques modifications) à n’importe quel modèle : un modèle de courbe de tarage complexe, mais aussi un modèle de régression linéaire, un modèle hydrologique, un modèle de transport sédimentaire, etc. La nécessité de faire évoluer le code pour intégrer les travaux de Mansanarez (2016) nous semble donc une excellente opportunité pour voir plus loin que le seul cas des courbes de tarage complexe : l’objectif est de généraliser le code pour qu’il puisse gérer un modèle quelconque – ou tout du moins une grande variété de modèles. Cette version généralisée du code de calcul BaRatin est nommée BaM, pour Bayesian Modeling.
I.3 Objectifs et plan du rapport
Les objectifs principaux de ce rapport sont les suivants : 1. présenter les principes généraux de BaM ;
2. illustrer l’application de BaM sur une gamme variée de modèles ;
3. documenter les méthodes et les modèles qui sont implémentés dans BaM ;
4. expliquer l’utilisation des fichiers de configuration qui permettent de piloter l’exécutable BaM.exe.
- 8 -
Le rapport est divisé en deux grandes parties. La première partie se veut aussi didactique que possible et évite donc de rentrer dans tous les détails techniques sous-jacents à BaM. Elle est composée d’une première section où les principes généraux de BaM sont décrits (section II), d’une seconde section illustrant l’application de BaM à six modèles distincts (section III), et d’une troisième section qui discute des perspectives découlant du travail effectué cette année (section IV). La seconde partie du rapport est beaucoup plus technique, et comporte trois annexes qui documentent l’implémentation de BaM. L’annexe 1 (section V) décrit le formalisme statistique utilisé dans BaM ; l’annexe 2 (section VI) décrit les fichiers de configuration utilisés pour piloter l’exécutable BaM.exe ; enfin, l’annexe 3 (section VII) décrit les six modèles qui sont implémentés dans BaM à la date d’écriture de ce rapport.
- 9 -
II. Principes généraux
Cette section commence par définir ce qu’est un modèle dans BaM : nous présentons un objet générique qui englobe une grande diversité de modèles utilisés en pratique (section II.1). Tout comme BaRatin, l’objectif de BaM est d’estimer les paramètres du modèle (ainsi que leurs incertitudes), et d’effectuer des prédictions à partir du modèle (assorties de leurs incertitudes). Les deux sous-sections suivantes décrivent donc de manière générale les étapes d’estimation (section II.2) et de prédiction (section II.3).
II.1 L’objet « modèle »
Dans BaM, un modèle est défini comme une fonction (déterministe) qui calcule une ou plusieurs variable(s) de sortie à partir d’une ou plusieurs variable(s) d’entrée. Cette fonction dépend d’un certain nombre de paramètres qui sont généralement inconnus et qui devront donc être estimés. La Figure II-1 schématise l’objet « modèle » manipulé dans BaM. Cet objet comprend au minimum les éléments suivants :
un certain nombre de variables d’entrée. Le nombre NX de ces variables n’est pas
limité ;
un vecteur de paramètres θ qui doivent être estimés. La taille de ce vecteur (Npar) n’est pas limitée ;
une fonction M X θ( ; ) qui permet de calculer, à partir des variables d’entrée et des paramètres, les valeurs prises par les variables de sortie ;
un certain nombre de variables de sortie. Le nombre NY de ces variables n’est pas limité.
En plus de ces éléments obligatoires, un modèle peut comporter les éléments optionnels suivants :
des informations de configuration du modèle. Le contenu de ces informations est totalement spécifique au modèle utilisé : il peut s’agir par exemple d’un fichier d’options, de conditions initiales pour un modèle hydrologique, de données topographiques pour un modèle hydraulique, etc.
le modèle peut retourner un certain nombre de paramètres dérivés, c’est-à-dire de paramètres qui s’écrivent comme une fonction des paramètres initiaux θ ;
le modèle peut également retourner un certain nombre de variables d’état : il s’agit en fait de variables de sortie supplémentaires, à la différence près que les variables d’état sont en général non observables. Elles visent plutôt à informer sur l’état du modèle au cours de ses simulations, et ne sont pas utilisées pour estimer les paramètres du modèle.
- 10 -
Figure II-1. Schématisation de l’objet « modèle » manipulé par BaM.
Il est intéressant de décliner cet objet « modèle » générique pour des modèles bien connus, afin de le rendre plus concret. La Figure II-2 illustre le cas du modèle de courbe de tarage BaRatin. Ce modèle possède une unique variable d’entrée (la hauteur), une unique variable de sortie (le débit), et un certain nombre de paramètres décrivant les contrôles hydrauliques qui gouvernent la relation hauteur-débit. En guise de configuration, BaRatin nécessite de définir une matrice des contrôles, qui décrit la succession des contrôles hydrauliques lorsque la hauteur d’eau augmente. Enfin, BaRatin retourne également les paramètres « offset » de chaque contrôle hydraulique (c’est-à-dire le b de l’équation Qa h( b)c) qui sont déduits des autres paramètres par continuité de la courbe de tarage : dans le vocabulaire de BaM, il s’agit de paramètres dérivés.
- 11 -
La Figure II-3 illustre le cas du modèle hydrologique GR4J (Perrin et al. 2003). Ce modèle possède deux variables d’entrée (la précipitation et l’évapotranspiration potentielle), une unique variable de sortie (le débit), et six paramètres (les quatre paramètres principaux du modèle, ainsi que les taux de remplissage initial des deux réservoirs du modèle). Un fichier de configuration décrivant un certain nombre d’options du modèle est nécessaire pour utiliser GR4J. Enfin, GR4J retourne deux variables d’état, qui décrivent l’évolution des taux de remplissage des deux réservoirs du modèle au cours du temps. La différence entre ces deux variables d’état et la variable de sortie (débit) est que la seconde est observable : on pourra donc directement comparer les débits simulés à des débits observés. A l’inverse, il n’existe pas de mesure directe des variables d’états, car les réservoirs de GR4J sont des objets conceptuels plutôt que des entités existant réellement dans le bassin versant.
Figure II-3. Déclinaison de l’objet « modèle » pour le modèle hydrologique GR4J.
L’objet « modèle » illustré en Figure II-1 se veut aussi général que possible, et devrait être déclinable pour de nombreux modèles utilisés en pratique. Six modèles sont actuellement implémentés dans BaM sous ce formalisme : BaRatin, un modèle de courbe de tarage à double niveau, régression linéaire multiple, GR4J, un modèle de transport sédimentaire et un modèle d’orthorectification. Ces six modèles sont décrits en détail dans la section VII, et leur utilisation dans BaM est illustrée dans la section III. Il sera possible dans le futur d’implémenter d’autres modèles sous ce même formalisme (voir discussion en section IV). La principale limitation que nous présageons est liée au fait que toutes les variables d’entrée, de sortie et d’état sont supposées être définies sur la même grille (par exemple sur les mêmes pas de temps pour un modèle dynamique). En l’état actuel, BaM ne pourrait ainsi pas directement accueillir un modèle qui utiliserait des données horaires en entrée et qui produirait des données journalières en sortie, par exemple. Il serait a minima nécessaire de modifier l’interface d’un tel modèle pour qu’il produise des données horaires en sortie (par interpolation des sorties journalières brutes par exemple). En principe, cette limitation pourrait être levée, au prix d’une complexification non négligeable du code de BaM : nous laissons donc cette possibilité en suspens pour le moment.
- 12 -
II.2 Estimation
II.2.1 Principe général
Les simulations du modèle dépendent de paramètres inconnus θ (ou au moins imparfaitement connus) qu’il faut donc estimer. Le principe général de l’estimation est de comparer les simulations du modèle avec des observations de ses variables de sortie, et d’ajuster les paramètres de sorte que simulations et observations s’accordent « au mieux » (le sens précis de ce dernier terme sera discuté en section II.2.4). La Figure II-4 illustre le principe de l’estimation, et montre que la comparaison entre simulations et observations réclame de considérer trois sources d’erreurs :
1. les observations des variables de sortie du modèle sont incertaines et ne sont donc pas parfaites : les valeurs observées ne sont pas égales aux vraies valeurs. La différence entre les deux est appelée l’erreur sur les données de sortie ;
2. les simulations du modèle sont obtenues en utilisant des observations des variables d’entrée du modèle. Comme précédemment, ces observations sont incertaines à cause d’erreurs sur les données d’entrée ;
3. un modèle étant une simplification de la réalité, on ne s’attend pas à ce que ses simulations soient égales aux vraies valeurs des variables de sortie, même en l’absence de toute erreur sur les données. Cette différence entre valeurs simulée et vraie est appelée l’erreur structurelle.
Dans BaM, l’estimation des paramètres est réalisée en utilisant des modèles statistiques explicites pour décrire ces trois sources d’erreurs : on parle de modèles d’erreurs, par opposition au modèle (tout court) dont on cherche à estimer les paramètres. Les modèles d’erreurs utilisés dans BaM sont décrits dans les prochaines sections II.2.2 et II.2.3. Une fois ces modèles d’erreurs spécifiés, l’estimation des paramètres est réalisée par inférence Bayésienne, comme décrit en section II.2.4.
- 13 - II.2.2 Modèle pour les erreurs structurelles
L’erreur structurelle correspond à la différence entre la vraie valeur de la variable de sortie y t
et la valeur simulée par le modèle ˆy , à un pas de temps donné t t . Précisons pour commencer
que ces notations sont simplificatrices pour deux raisons :
1. Il peut y avoir plusieurs variables de sorties ; nous présentons ici le modèle d’erreur structurelle pour une quelconque de ces variables, sachant que chaque variable est équipée d’un modèle similaire.
2. Nous interprétons t comme un pas de temps, mais certains modèles n’ont pas de notion de temps (par exemple, une régression linéaire entre le débit moyen interannuel et la taille d’un bassin versant ne ferait pas intervenir le temps). De manière plus générale, t est en fait simplement un index.
Ces simplifications volontaires ont pour but d’éviter d’alourdir les notations et de rendre le modèle d’erreur plus intuitif. Le modèle d’erreur structurelle utilisé dans BaM est le suivant2
:
1 2
ˆ ; ~ 0; ˆ
t t t t t
y y N y (1) Le modèle d’erreur de l’équation (1) peut se lire de la façon suivante : la vraie valeur est égale à la valeur simulée plus une erreur structurelle. Cette erreur structurelle est une réalisation d’une variable aléatoire Gaussienne, de moyenne nulle et dont l’écart-type est une fonction affine de la valeur simulée t 12yˆt. On fait de plus l’hypothèse que les erreurs
structurelles sont indépendantes d’un pas de temps à un autre.
La Figure II-5 illustre ce modèle d’erreurs structurelles. On considère le cas d’un modèle qui simulerait un débit ˆy (par exemple, une courbe de tarage ou un modèle hydrologique). La t
figure de gauche correspond au cas où l’écart-type des erreurs est constant et vaut 100 m3 .s-1. Dans la figure de droite, cet écart-type croît avec le débit simulé, suivant la relation
ˆ 10 0.2
t yt
. En conséquence, les erreurs sont plus importantes durant la période de crue, et inversement sont plus faibles quand le débit diminue.
Figure II-5. Illustration du modèle d’erreurs structurelles. La courbe noire correspond aux
débits simulés par le modèle yˆt, les courbes vertes et rouges correspondent aux vrais débits
ˆt t
y pour deux réalisations des erreurs structurelles t. Les deux figures diffèrent par les
valeurs des paramètres 1 et 2 qui contrôlent l’écart-type des erreurs.
- 14 -
En pratique, les paramètres 1 et 2 qui gouvernent l’écart-type des erreurs structurelles sont inconnus et doivent donc être estimés en même temps que les paramètres θ du modèle. Précisons enfin que BaM offre la possibilité d’utiliser d’autres relations que la relation affine
1 2ˆ
t yt
(voir section V.2 pour plus de détails). II.2.3 Modèle pour les erreurs sur les données
Une erreur sur les données correspond à la différence entre la vraie valeur d’une variable et la valeur mesurée / observée. Ces erreurs affectent à la fois les variables d’entrée et les variables de sortie du modèle. Nous présentons le modèle d’erreur utilisé dans BaM pour une variable de sortie y et son observation correspondante t y , sachant que ce même modèle d’erreur est t
utilisable pour toutes les variables d’entrée et de sortie. De plus, nous adoptons une présentation pas à pas de ce modèle d’erreur, en partant du cas le plus simple pour aller vers des modèles d’erreur plus complexes.
Le modèle d’erreur le plus simple consiste à simplement ignorer les erreurs affectant les observations y , c’est-à-dire à supposer que t yt yt. Ceci est adéquat pour les variables mesurées avec très peu d’incertitude, ou dont l’incertitude est négligeable devant celle d’autres variables.
Le modèle d’erreur le plus classique consiste à supposer que la variable observée est égale à la vraie valeur plus une erreur d’observation Gaussienne :
; ~ 0;
t t t t
y y N u (2) On supposera également que les erreurs t sont indépendantes d’un pas de temps à un autre. Précisons que l’écart-type des erreurs u est ici supposé connu : sa valeur devrait être fixée à la suite d’une analyse d’incertitude du processus de mesure / d’observation ayant conduit aux valeurs observées y . Ceci constitue une différence importante entre les erreurs d’observation t
et les erreurs structurelles. Les premières existent indépendamment du modèle que l’on cherche à estimer, et il est donc possible d’évaluer leurs caractéristiques (ici, u) avant l’étape d’estimation du modèle. A l’inverse, les erreurs structurelles sont par définition liées aux simulations du modèle : on ne peut donc pas estimer leurs caractéristiques avant d’avoir estimé les paramètres du modèle.
Le panneau gauche de la Figure II-6 illustre ce modèle d’erreur. Le caractère indépendant des erreurs t conduit à une série d’observations qui est très bruitée par rapport aux vraies valeurs. Ceci peut être jugé inadéquat pour certains processus d’observation. Un modèle d’erreur alternatif consiste à supposer que la variable observée est égale à la vraie valeur plus une erreur systématique :
; ~ 0;
t t
y y N b (3) La principale différence entre les modèles d’erreur (2) et (3) est que l’erreur systématique ne varie pas avec le temps : la même erreur affectera donc tous les pas de temps, comme illustré dans le panneau central de la Figure II-6. L’erreur peut également être interprétée comme un biais inconnu (si le biais était connu, on le corrigerait !). Cependant, même si on ne connait pas précisément la valeur de ce biais, on peut lui affecter une incertitude, qui est ici contrôlée par l’écart-type b, qui est supposé connu.
- 15 - Insistons sur le vocabulaire qui est adopté dans BaM :
les erreurs t sont appelées erreurs indépendantes ou erreurs non-systématiques ;
l’erreur est appelée biais inconnu ou erreur systématique.
On trouve parfois dans la littérature l’expression « erreurs aléatoires » pour désigner les erreurs t. Nous préférons cependant éviter cette expression, car d’après l’équation (3), l’erreur systématique est également une réalisation d’une variable aléatoire ! Mais cette unique réalisation affecte de manière systématique tous les pas de temps, alors que dans le cas des erreurs indépendantes t, une nouvelle réalisation est générée à chaque pas de temps. Dans de nombreux cas, le processus d’observation conduira à considérer à la fois les erreurs systématiques et non-systématiques. Ceci conduit au modèle mixte suivant, illustré dans le panneau de droite de la Figure II-6 :
; ~ 0; ; ~ 0;
t t t t
y y N b N u (4)
Figure II-6. Illustration du modèle d’erreurs sur les données. La courbe noire correspond aux
vrais débits yt, les courbes vertes et rouges correspondent aux débits observés pour deux
réalisations des erreurs d’observation. Gauche : erreurs indépendantes t avec u100m .s3 -1 ; centre : erreur systématique avec b100m .s3 -1 ; droite : erreurs mixtes t.
Les modèles d’erreur (2), (3) et (4) supposent que les écart-types u et b sont constants (en statistiques, on parle d’erreurs homoscédastiques). Ceci est trop restrictif dans certains cas : par exemple, on observe souvent que l’incertitude est proportionnelle à l’observation (correspondant à une incertitude relative constante). Pour pouvoir gérer ce type de situation, on peut généraliser le modèle d’erreurs indépendantes (2) de la façon suivante :
; ~ 0;1
t t t t t
y y u N (5) Dans l’équation (5), l’erreur *
t ut t
a un écart-type égal à u , qui varie maintenant avec le ttemps : ceci permet donc de gérer toute situation où l’incertitude absolue des observations n’est pas constante (on parle d’erreurs hétéroscédastiques). Précisons que les valeurs de u t
sont toujours supposées connues, et devront donc être spécifiées par l’utilisateur, idéalement suite à une analyse d’incertitude du processus d’observation. A titre d’exemple, le panneau de
- 16 -
gauche de la Figure II-7 illustre le cas où ut 0.15yt, correspondant à une incertitude relative constante de 15%3.
On peut procéder de façon identique pour l’erreur systématique , ce qui conduit au modèle d’erreur suivant :
; ~ 0;1
t t t
y y b N (6) Ce modèle d’erreur est illustré dans le panneau central de la Figure II-7, toujours dans le cas d’une incertitude relative constante de 15%. Son interprétation est assez subtile : en effet, l’erreur est toujours constante dans le temps et est donc bien systématique. Néanmoins, l’effet de cette erreur sur les observations, donné par *
t bt
, varie cette fois dans le temps !Finalement, on peut considérer un modèle d’erreur mixte incluant erreurs systématiques et non-systématiques, comme illustré dans le panneau de droite de la Figure II-7:
; ~ 0;1 ; ~ 0;1
t t t t t t
y y b u N N (7) Le modèle d’erreur (7) est celui qui est effectivement implémenté dans BaM, car c’est le modèle le plus général : il englobe tous les autres modèles d’erreur (2)-(6) comme des cas particuliers. Par exemple, en spécifiant bt 0 et ut constante, on retombe sur le modèle d’erreurs homoscédastiques indépendantes (2). De plus, BaM offre la possibilité de spécifier des modèles d’erreurs différents par groupe d’observations, ce qui peut être utile dans certains cas : ceci sera illustré en section III.7.
Figure II-7. Illustration du modèle d’erreurs sur les données. La courbe noire correspond aux
vrais débits yt, les courbes vertes et rouges correspondent aux débits observés pour deux
réalisations des erreurs d’observation. Gauche : erreurs indépendantes utt avec ut 0.15yt ; centre : erreurs systématiques bt avec bt 0.15yt ; droite : erreurs mixtes bt utt.
II.2.4 Inférence Bayésienne
BaM utilise le formalisme Bayésien pour estimer les paramètres θ du modèle, ainsi que les paramètres inconnus γ du modèle d’erreur structurelle. Les principes généraux de cette approche ne sont pas rappelés dans ce rapport : le lecteur pourra se référer aux supports de
- 17 -
formation existants4 ou à l’aide du logiciel BaRatinAGE. Comme dans toute analyse Bayésienne, l’estimation des paramètres se fait sous forme probabiliste : le produit final est une distribution a posteriori des paramètres θ et γ , qui fournit directement l’incertitude affectant les paramètres estimés. Cette distribution a posteriori combine deux sources d’information : l’information portée par les données utilisées pour l’estimation, quantifiée via la vraisemblance, et toute information exogène aux données, que l’utilisateur peut spécifier via la distribution a priori. La Figure II-8 résume les différentes étapes de l’estimation Bayésienne implémentée dans BaM.
Une distribution a priori est spécifiée indépendamment pour chaque composante
k des vecteurs
1,...,
par
N
θ
et γ . Typiquement, l’utilisateur spécifiera que
k suit une distribution a priori Gaussienne, de moyenne m et d’écart-type k s donnés. La moyenne k m ks’interprète comme la valeur la plus probable a priori, et l’écart-type s comme l’incertitude k
sur cette valeur (avant d’avoir observé les données utilisées pour l’estimation). Ceci est identique à l’approche implémentée dans le logiciel BaRatinAGE. BaM propose toutefois deux nouveautés en termes de spécification des distributions a priori :
1. La distribution n’est pas forcément Gaussienne : BaM propose un catalogue de distributions incluant les distributions uniforme, log-normale, exponentielle, etc. ; 2. Il est possible de fixer la valeur d’un paramètre, en sélectionnant une distribution a
priori particulière dénommée FIX. Ce paramètre ne sera donc pas estimé, et sera fixé à la valeur spécifiée par l’utilisateur.
La vraisemblance utilisée dans BaM découle directement des modèles d’erreurs spécifiés pour les erreurs sur les données d’entrée/sortie et pour les erreurs structurelles (voir section précédente) : aucune action supplémentaire n’est donc requise de la part de l’utilisateur pour évaluer la vraisemblance. L’expression mathématique de cette vraisemblance est donnée dans l’annexe 1 (section V.3). La formule de Bayes combine ensuite la distribution a priori et la vraisemblance pour donner la distribution a posteriori des paramètres inconnus θ et γ .
Etant donné qu’il existe généralement plusieurs paramètres à estimer, la distribution a posteriori est multidimensionnelle est n’est donc pas facile à visualiser ou à utiliser. Pour contourner cette difficulté, BaM génère un grand nombre de valeurs issues de la distribution a posteriori, en utilisant un algorithme de Monte Carlo par Chaîne de Markov (MCMC). Comme pour l’analyse Bayésienne, nous ne détaillons pas les principes généraux des algorithmes MCMC dans ce rapport : le lecteur pourra se référer aux supports de formation existants ou à l’aide du logiciel BaRatinAGE (l’algorithme MCMC utilisé étant identique dans BaM et dans BaRatinAGE).
En introduction de cette section II.2, nous mentionnions que l’estimation est généralement basée sur la comparaison des simulations du modèle et des observations, les paramètres estimés étant ajustés de sorte que simulations et observations s’accordent « au mieux ». Dans la cadre de l’analyse Bayésienne décrite ici, la signification de l’expression « au mieux » est un peu particulière : en fait, on ne cherche pas à estimer une unique valeur des paramètres, mais on recherche plutôt l’ensemble des paramètres qui rendent les simulations du modèle compatibles avec les modèles d’erreurs spécifiés (voir section précédente). Ceci est à comparer avec une approche plus classique qui viserait à chercher le vecteur de paramètre qui minimise une certaine fonction cible (approche par les moindres carrés typiquement). Dans l’analyse Bayésienne, il n’est pas nécessaire de choisir une fonction cible, mais à la place il est nécessaire de spécifier des modèles d’erreurs. L’avantage est que le résultat fournit
- 18 -
directement l’incertitude sur les paramètres estimés (quantifiée via leur distribution a posteriori). De plus, il reste possible d’extraire un vecteur de paramètre particulier qui pourrait être considéré comme « le meilleur » : on choisira pour cela le vecteur de paramètre qui maximise la densité de la distribution a posteriori (appelé estimateur maxpost dans le cadre de BaM).
Figure II-8. Schématisation de l’inférence Bayésienne appliquée dans BaM.
II.3 Prédiction
Le modèle ayant été estimé, il est à présent possible de l’utiliser pour réaliser des prédictions. Dans BaM, le mot « prédiction » est utilisé dans un sens très général : il désigne toute simulation du modèle visant à estimer les valeurs prises par les variables de sortie, pour des variables d’entrée données. Ceci englobe plusieurs situations, parmi lesquelles (la liste n’est pas exhaustive) :
La prévision, lorsque les variables d’entrée correspondent à des valeurs futures. C’est le cas par exemple lorsqu’on utilise un modèle hydrologique forcé avec des précipitations futures, prévues par un modèle météorologique, pour réaliser une prévision des débits ;
La reconstruction, lorsque les variables d’entrée correspondent à des valeurs passées qui ont effectivement été observées. C’est le cas par exemple lorsqu’on utilise une courbe de tarage pour calculer les débits à partir des hauteurs observées ;
Le barème, lorsqu’on réalise un abaque des valeurs prises par les variables de sortie pour un ensemble de valeurs des variables d’entrée, généralement organisées en grille. C’est le cas par exemple de la représentation classique d’une courbe de tarage, où le débit est calculé sur une grille de valeurs de hauteur.
Dans BaM, tout type de prédiction est réalisé de la même manière, résumée en Figure II-9. L’utilisateur doit tout d’abord fournir les variables d’entrée à utiliser pour la prédiction. Le modèle est alors utilisé avec ses paramètres estimés pour fournir les valeurs simulées des variables de sortie. Ces valeurs simulées peuvent finalement être perturbées en utilisant le modèle d’erreur structurelle, pour fournir une estimation des « vraies » valeurs des variables
- 19 -
de sortie. Dans ce processus, trois sources d’incertitudes apparaissent : l’incertitude sur les données d’entrée, l’incertitude sur les paramètres du modèle (incertitude paramétrique) et l’incertitude induite par le modèle d’erreur structurelle (incertitude structurelle). L’utilisateur a le choix d’activer ou de désactiver chacune de ces trois sources d’incertitude. Plus précisément, chaque source d’incertitude est gérée de la façon suivante :
Incertitude sur les données d’entrée : si l’utilisateur fournit une unique réalisation des données d’entrée, alors cette incertitude n’est pas propagée, et le modèle tournera une seule fois en utilisant cette unique réalisation en entrée. L’utilisateur peut néanmoins fournir plusieurs réalisations possibles des données d’entrée (qui représentent leur incertitude), auquel cas le modèle tournera autant de fois qu’il y a de réalisations. Le résultat prendra donc la forme de plusieurs réalisations possibles des variables de sortie, qui représentent l’incertitude résultant des incertitudes sur les données d’entrée. On parle de propagation Monte Carlo des incertitudes, ou de façon plus imagée, d’ « approche spaghetti » (chaque réalisation étant un unique spaghetto). Précisons que s’il y a plusieurs variables d’entrée, on peut choisir d’activer la propagation des incertitudes pour certaines, et de la désactiver pour d’autres.
Incertitude paramétrique : si la propagation est désactivée, alors un unique vecteur de paramètres du modèle est utilisé (le paramètre maxpost). Si la propagation est activée, alors de nombreux vecteurs de paramètres sont utilisés, et ces paramètres sont simulés dans la distribution a posteriori (en pratique, on utilise directement les simulations MCMC déjà réalisées). Il existe également une option qui permet de simuler ces paramètres dans la distribution a priori.
Incertitude structurelle : si la propagation est désactivée, alors les valeurs simulées par le modèle sont utilisées telles quelles. Si la propagation est activée, chaque spaghetto simulé par le modèle est perturbé par des erreurs structurelles, générées à partir du modèle d’erreurs structurelles spécifié, dont les paramètres γ ont été estimés (voir section précédente). S’il y a plusieurs variables de sortie, on peut choisir d’activer la propagation des incertitudes pour certaines, et de la désactiver pour d’autres.
- 20 -
Pour rendre le processus de prédiction de BaM plus concret, considérons le cas du modèle de courbe de tarage BaRatin. On pourra typiquement réaliser les prédictions suivantes :
Courbe de tarage a priori. On utilise en entrée une grille de valeurs de hauteur, sans incertitude ; les paramètres sont simulés depuis la distribution a priori ; les erreurs structurelles ne sont pas activées.
Courbe de tarage maxpost. On ne propage aucune source d’incertitude : on utilise en entrée une grille de valeurs de hauteur, sans incertitude ; l’unique vecteur de paramètres maxpost est utilisé ; les erreurs structurelles ne sont pas activées.
Incertitudes affectant la courbe de tarage. Pour calculer l’incertitude totale, on active à la fois l’incertitude paramétrique et l’incertitude structurelle : on utilise en entrée une grille de valeurs de hauteur, sans incertitude ; les paramètres sont simulés depuis la distribution a posteriori ; les erreurs structurelles sont activées. On peut également calculer uniquement l’incertitude paramétrique : on procède comme précédemment, mais en désactivant les erreurs structurelles.
Chroniques de débit et leurs incertitudes. On procède comme pour les deux points précédents, mais en utilisant une chronique de hauteurs observées en entrée (plutôt qu’une grille de valeurs). Puisqu’il s’agit de hauteurs observées, elles sont potentiellement incertaines, et il est donc possible d’activer la propagation de l’incertitude sur les données d’entrée, en plus des incertitudes paramétrique et structurelle.
Pour finir, notons que le processus de prédiction décrit ici ne fait aucunement intervenir le modèle d’erreur sur les données de sortie, contrairement au processus d’estimation (voir Figure II-4). La raison principale est que l’objectif d’une prédiction est de prédire les vraies valeurs des variables de sortie, et non pas leurs valeurs mesurées, entachées d’erreur. On peut cependant légitimement vouloir comparer une prédiction avec des valeurs effectivement observées ; mais dans ce cas, l’incertitude de mesure/d’observation affecte la valeur observée, et non pas les simulations du modèle. Une comparaison prédiction / observation réclamera donc de comparer deux quantités incertaines.
- 21 -
III. Exemples d’application
Cette section illustre l’utilisation de BaM pour les six modèles qui sont actuellement implémentés: le modèle de courbe de tarage BaRatin, un modèle de courbe de tarage à double niveau, une régression linéaire multiple, le modèle hydrologique GR4J, un modèle de transport sédimentaire et un modèle d’orthorectification. L’objectif de ces cas d’étude est avant tout de donner des exemples concrets des analyses qui peuvent être effectuées avec BaM : ils doivent donc être considérés comme des exercices illustratifs, plutôt que comme des analyses en profondeur des différents jeux de données traités. En complément de cette application aux six modèles, nous proposons également un septième cas d’étude illustrant les différents types d’erreur (systématiques et non-systématiques, voir section II.2.3) qui peuvent être utilisés pour quantifier l’incertitude sur les données.
III.1 Courbes de tarage : BaRatin
III.1.1 Données et modèle
Etant donné que BaM est une généralisation de BaRatin, il devrait être capable de reproduire toutes les analyses que BaRatin propose : c’est ce qui est illustré ici. La station analysée est l’Ardèche à Sauze-Saint-Martin, qui contrôle un bassin versant de 2240 km². L’analyse hydraulique de cette station suggère que le contrôle en bas débit est assuré par un radier naturel qui peut être assimilé à un contrôle par seuil rectangulaire, alors qu’à plus haut débit un unique contrôle par un chenal rectangulaire large prévaut. Ceci conduit au modèle de courbe de tarage suivant :
1 2 1 1 1 2 2 2 2 ( ) si ( ) ( ) si c c a h b h Q h a h b h (8)
En pratique, les paramètres inconnus à estimer sont θ
1, , ,a c1 1 2,a c2, 2
. Les paramètres 1b et b sont déduits par continuité, et sont donc considérés comme des paramètres dérivés. 2
L’analyse des propriétés physiques de chaque contrôle (forme, dimensions, pente, rugosité) permet de spécifier des distributions a priori pour chaque paramètre. Les distributions utilisées ici sont données dans le Tableau III-1. Pour plus de détails sur l’analyse hydraulique de cette station ayant conduit à ces a priori, le lecteur peut consulter l’article de Le Coz et al. (2014).
Tableau III-1. Distributions a priori utilisées.
Paramètre 1 a 1 c1 2 a 2 c 2
Distribution
a priori N
0.5;0.25
N
53;10
N
1.5;0.025
N
1.5;0.5
N
144;45
N
1.67;0.025
Pour estimer les paramètres, nous disposons d’un jeu de 38 jaugeages, visibles dans la Figure III-5. Nous supposons ici que les hauteurs jaugées sont sans incertitude, et nous utilisons le modèle classique d’erreurs indépendantes pour les débits jaugés (équation (5)). Les jaugeages à bas débit sont affectés d’une incertitude forfaitaire variant de 5% à 10% en fonction de la méthode utilisée. La plupart des jaugeages à haut débit ont été réalisés à partir de mesures de surface LS-PIV (Large-Scale Particle Image Velocimetry) : ils sont donc affectés d’une incertitude plus importante de 20%.
Enfin, nous utilisons le modèle d’erreur structurelle de l’équation (1), supposant que l’écart-type des erreurs structurelles est une fonction affine du débit : t 12yˆt.
- 22 - III.1.2 Résultats
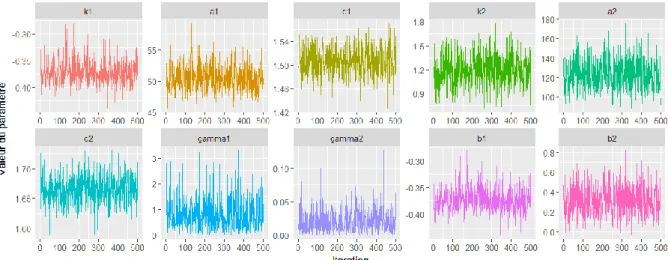
La Figure III-1 montre les simulations MCMC effectuées par BaM. Les graphiques montrent 500 itérations qui correspondent à un post-traitement des 100 000 itérations réellement effectuées (voir section VI.6.2 pour plus de détails sur ce post-traitement). Ce graphique est principalement utilisé pour vérifier visuellement que les simulations MCMC ont bien convergé : en l’occurrence, rien n’indique le contraire.
Figure III-1. Simulations MCMC issus de la distribution a posteriori pour les 6 paramètres de la
courbe de tarage θ, les deux paramètres du modèle d’erreur structurelle γ, ainsi que les deux
paramètres dérivés
b b1, 2
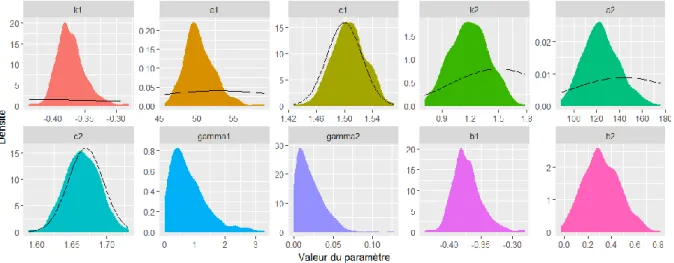
.Les simulations MCMC peuvent être directement utilisées pour estimer la distribution a posteriori de chaque paramètre (qui représente leur incertitude), comme illustré en Figure III-2. Les distributions a priori sont également reportées pour comparaison. Les résultats suggèrent que les paramètres
1, ,a1 2,a2
de la courbe de tarage sont assez bien identifiés grâce aux jaugeages (la distribution a posteriori étant bien plus précise que l’a priori). On note tout de même une incertitude qui reste assez marquée pour la hauteur d’activation du second contrôle 2, qui est comprise entre 0.9 et 1.5 m. Les paramètres
c c sont quant à eux 1, 2
similaires a priori et a posteriori, ce qui s’explique par l’utilisation d’une distribution a priori très précise pour ces paramètres, qui représentent des exposants théoriques dépendant uniquement du type de contrôle hydraulique. Les paramètres γ du modèle d’erreur structurelle sont eux aussi identifiés assez précisément : le paramètre 10.3 s’interprète comme une erreur-type incompressible d’environ 0.3 m3.s-1 lorsque le débit tend vers zéro, alors que le paramètre 2 0.01 s’interprète comme une erreur-type relative d’environ 1% pour les plus hauts débits, ce qui est assez faible. Observons enfin que BaM fournit également la distribution a posteriori des paramètres dérivés b1 et b . En l’occurrence, la continuité de la 2courbe de tarage conduit aux équations suivantes :
1 2 1 1 1/ 1 2 2 2 1 2 c c b a b b a (9)- 23 -
On observe qu’effectivement, les distributions a posteriori de b1 et 1 sont rigoureusement identiques. Le paramètre dérivé b est une combinaison plus complexe des autres paramètres 2
de la courbe de tarage, ce qui n’empêche pas d’accéder à sa distribution a posteriori par simple propagation Monte Carlo (i.e. en recalculant la seconde ligne de l’équation (9) pour toutes les simulations MCMC de
1, , ,a c1 1 2,a c2, 2
).Figure III-2. Distributions a posteriori pour chaque paramètre estimées à partir des simulations MCMC. Les courbes noires représentent les distributions a priori.
En guise de nouveauté par rapport à BaRatin, BaM propose une analyse des résidus basée sur la comparaison des sorties simulées et observées (toutes les simulations étant réalisées avec les paramètres maxpost). La Figure III-3a montre que dans le présent cas d’étude, les débits simulés sont globalement en accord avec les débits observés, même si les points semblent s’éloigner plus sensiblement de la diagonale pour les hauts débits. Ceci est confirmé par la Figure III-3b, qui montre que la variabilité des résidus (observé – simulé) a tendance à augmenter avec le débit. C’est un cas typique d’hétéroscédasticité, qui a deux origines possibles : (i) l’incertitude des débits observés augmente avec le débit (puisqu’elle est constante en relatif) ; (ii) l’écart-type des erreurs structurelles est supposé augmenter linéairement avec le débit. Les modèles d’erreur utilisés dans BaM prennent explicitement en compte ces deux sources d’hétéroscédasticité, et il est possible de vérifier que ces modèles d’erreur sont correctement spécifiés. Pour cela, on calcule les résidus standardisés (voir section VI.6.4 pour les détails techniques) et on vérifie qu’ils sont approximativement homoscédastiques (variance constante) : c’est ce que suggère la Figure III-3c pour le présent cas d’étude. Si ce n’était pas le cas, il conviendrait de remettre en question les modèles d’erreur utilisés (erreurs d’observation et/ou erreurs structurelles).
- 24 -
(a) (b) (c)
Figure III-3. Analyse des résidus. (a) comparaison entre débits observés et simulés ; (b) résidus en fonction du débit simulé ; (c) résidus standardisés en fonction du débit simulé.
Le modèle ayant été estimé et la pertinence des modèles d’erreur ayant été évaluée via l’analyse des résidus, il est à présent possible de réaliser des prédictions. La Figure III-4a montre la représentation classique en courbe de tarage. Il s’avère que pour les hauts débits, l’incertitude autour de cette courbe est quasi-exclusivement paramétrique, ce qui n’est pas étonnant étant donné la faible valeur estimée 2 1%. Cependant, la situation s’inverse pour les bas débits (Figure III-4b), ce qui s’explique par l’estimation très précise des trois paramètres du premier contrôle (voir Figure III-2).
(a) (b)
Figure III-4. Exemples de prédictions réalisées avec BaM. (a) courbe de tarage maxpost (courbe noire), intervalles d’incertitude paramétrique (rose) et totale (rouge) à 95%, et jaugeages avec
intervalles d’incertitude à 95% ; (b) comme (a), mais avec un zoom sur les faibles hauteurs et une échelle logarithmique en débit.
Il est également possible de calculer une chronique de débit à partir d’un limnigramme et de la courbe de tarage estimée. En guise d’illustration, nous avons utilisé le limnigramme de la crue de septembre 1980. Une incertitude sur ce limnigramme a été prise en compte, en supposant des erreurs indépendantes dont l’écart-type est égal à 2.5% du tirant d’eau. La
- 25 -
Figure III-5 suggère que cette incertitude sur les hauteurs enregistrées contribue de manière non négligeable à l’incertitude totale des débits estimés.
(c)
Figure III-5. Exemples de prédictions réalisées avec BaM : hydrogramme maxpost (noir) pour la crue de septembre 1980, intervalle d’incertitude à 95% due à l’incertitude sur les hauteurs
(jaune) et intervalle d’incertitude totale à 95% (rouge).
III.2 Courbes de tarage à double niveau : le modèle SFD
(Stage-Fall-Discharge)
III.2.1 Données et modèle
Une courbe de tarage à double niveau est nécessaire lorsque le niveau d’eau à la station hydrométrique est soumis à une influence aval variable, typiquement un barrage qui régule la hauteur d’eau. Le calcul du débit nécessite dans ce cas de connaitre la hauteur h à la station 1
hydrométrique principale, mais aussi une hauteur h auxiliaire, généralement mesurée en aval 2
de la station (mais en amont du barrage).
La station du Rhône à Valence, contrôlant un bassin versant de 66 450 km², est soumise à l’influence du barrage de Beauchastel. Mansanarez et al. (2016) ont proposé le modèle de courbe de tarage à double niveau suivant pour cette station :
3 8 1 1 2 1 2 7 4 1 2 1 2 6 1 5 ( ) ( ) si ( ) ( , ) ( ) sinon h h h h h Q h h h (10)
La première ligne de cette équation décrit le régime influencé par l’aval, alors que la seconde ligne décrit le régime non influencé. La transition d’un régime à l’autre se fait suivant une hauteur de transition , qui varie en fonction de la hauteur auxiliaire h , et qui est calculée 2 par continuité de la courbe de tarage. Cette hauteur de transition est considérée comme une variable d’état du modèle. L’équation (10) est adaptée au cas d’un contrôle par un chenal rectangulaire large unique, ce qui est le cas pour le Rhône à Valence.
L’analyse des propriétés physiques des chenaux de contrôle permet de spécifier des distributions a priori pour chaque paramètre. Les distributions utilisées ici (Tableau III-2) sont
- 26 -
identiques à celles utilisées par Mansanarez et al. (2016), qui fournissent plus de détails sur l’analyse hydraulique sous-jacente.
Tableau III-2. Distributions a priori utilisées.
Paramètre 1 2 3 4
Distribution a priori N
6000;901
N
5;1
N
1.67;0.025
N
3900;50
Paramètre 5 6 7 8
Distribution a priori N
5;1
N
171;46
N
0;0.025
N
1.67;0.025
Pour estimer les paramètres, nous disposons d’un jeu de 68 jaugeages, visibles dans la Figure III-7. Nous supposons que les hauteurs jaugées sont sans incertitude, et nous utilisons le modèle classique d’erreurs indépendantes pour les débits jaugés (équation (5)), avec une incertitude forfaitaire de 10%. Enfin, nous utilisons le modèle d’erreur structurelle de l’équation (1), supposant que l’écart-type des erreurs structurelles est une fonction affine du débit : t 12yˆt.III.2.2 Résultats
La Figure III-6 montre les distributions a posteriori et a priori des paramètres du modèle. On observe que pour certains paramètres, les deux distributions sont très proches. C’est le cas pour les paramètres 3 et 8, qui représentent l’exposant de la relation puissance : ceci est similaire à ce qui est observé pour les courbes de tarage simples (voir cas d’étude précédent). C’est également le cas pour le paramètre 4, qui représente la distance le long de la rivière entre les deux mesures de hauteur : il est donc important de mesurer cette distance aussi précisément que possible, puisqu’il semble difficile de l’identifier à partir des seuls jaugeages. Pour les autres paramètres, les distributions a posteriori sont plus précises que les distributions a priori, ce qui suggère que ces paramètres peuvent être identifiés à partir des jaugeages à des degrés divers.
Figure III-6. Distributions a posteriori pour les 8 paramètres du modèle θ et les deux
paramètres du modèle d’erreur structurelle γ.
La Figure III-7 montre la représentation classique d’une courbe de tarage à double niveau comme plusieurs relations h1Q calculées pour des hauteurs h données. Cette 2
- 27 -
représentation illustre des relations différenciées pour les faibles hauteurs h (correspondant à 1
un régime influencé par le barrage), qui convergent toutes vers une unique relation pour les fortes hauteurs h (correspondant à un régime non influencé). L’adéquation avec les 1
jaugeages (coloriés en fonction de la valeur h ) est globalement excellente. 2
Figure III-7. Courbes de tarage à double niveau, représentées comme une relation h1-débit
coloriée en fonction de la hauteur h2. Les bandes représentent les intervalles d’incertitude totale
à 95%. Les jaugeages sont également représentés de façon similaire, avec leur incertitude à 95%.
La courbe de tarage à double niveau ayant été estimée, il est possible de calculer une chronique de débit à partir de deux limnigrammes h et 1 h , comme illustré en Figure III-8 2
pour la crue d’octobre 1993. Le panneau supérieur montre les deux limnigrammes, ainsi que la hauteur de transition estimée (qui est une variable d’état du modèle) accompagnée de son incertitude : dès que le limnigramme h passe au-dessus de la hauteur de transition, 1
l’écoulement ne subit plus l’influence aval du barrage. Le panneau inférieur montre la chronique de débit accompagnée de son incertitude totale, qui est globalement assez faible. L’ensemble des résultats présentés dans ce cas d’étude reproduit fidèlement les résultats présentés par Mansanarez et al. (2016), qui avaient été obtenus avec un code de calcul différent : ceci donne confiance dans l’implémentation du modèle, de l’estimation et des prédictions dans BaM.
- 28 -
Figure III-8. Chroniques de hauteur (panneau supérieur) et de débit (panneau inférieur) pour la
crue d’octobre 1993. Panneau supérieur : hauteur à la station principale h1 (bleu), à la station
auxiliaire h2 (vert) et hauteur de transition entre les régimes influencés et non influencés (noir,
avec intervalle d’incertitude à 95% en rouge). Panneau inférieur : débit estimé par le modèle, avec intervalle d’incertitude à 95%.
III.3 Régression linéaire multiple
III.3.1 Données et modèle
La régression linéaire multiple est un outil statistique qui vise à prédire les valeurs prises par une variable de sortie à partir d’un certain nombre de variables d’entrée, ou covariables, en utilisant une relation linéaire. Les applications de la régression sont innombrables. En hydrologie, on l’utilise par exemple pour prédire des quantiles de crues sur des bassins non jaugés, à partir de caractéristiques du bassin versant (surface, altitude, pluviométrie) : voir par exemple la méthode Crupedix (CTGREF et al. 1980-1982) et ses améliorations (Cipriani et al. 2012).
Dans ce cas d’étude, nous nous livrons à un exercice visant à estimer, pour un bassin versant
i, le débit de crue biennal Qi (exprimé en lame d’eau en mm) à partir de trois covariables : la
surface du bassin versant Si, la moyenne sur le bassin des pluies journalières décennales Pi, et
l’altitude moyenne du bassin Zi (pour plus de détails sur le calcul de ces covariables, voir
Cipriani et al. 2012). Le modèle de régression utilisé est le suivant :
0 1 2 2
- 29 -
Les données utilisées pour cet exercice proviennent de 45 stations hydrométriques situées dans le quart sud-est de la France. Ces stations sont issues du jeu de référence compilé par Giuntoli et al. (2012), et se caractérisent par une ancienneté minimale de 40 ans et une qualité des données jugée bonne. Pour chaque station, les maxima annuels sont extraits de la chronique des débits journaliers, et le débit biennal est simplement estimé comme la médiane empirique de cet échantillon. Sur les 45 stations disponibles, seules 30 sont utilisées pour l’étape d’estimation des paramètres. Les 15 stations restantes sont utilisées pour la validation du modèle de régression, en comparant les débits biennaux prédits par le modèle à partir des seules covariables, et ceux directement calculés en utilisant la série de débits journaliers.
Figure III-9. Localisation des stations hydrométriques utilisées : 30 stations pour l’estimation (bleu), 15 stations pour la validation (rouge).
Nous supposons que les valeurs de toutes les covariables sont connues sans incertitude. De plus, nous négligeons également l’incertitude sur les valeurs observées de ln(Qi), considérant que l’estimation d’un débit biennal basée sur plus de 40 ans de données conduit à une incertitude d’échantillonnage très faible. Enfin, nous utilisons un modèle d’erreur structurelle où l’écart-type des erreurs structurelles est constant.
III.3.2 Résultats
La Figure III-10 montre les distributions a posteriori des paramètres de la régression. On remarque que la superficie du bassin versant n’a pas d’effet significatif, puisque la distribution du paramètre correspondant est répartie de part et d’autre de zéro. Rappelons néanmoins que les débits ont été préalablement convertis en lame d’eau en mm. Les deux autres covariables (précipitation décennale moyennée sur le bassin et altitude moyenne) ont un effet positif sur le débit biennal.
- 30 -
Figure III-10. Distributions a posteriori des paramètres de la régression et de l’écart-type des erreurs structurelles.
La Figure III-11a compare les débits biennaux observés et prédits pour les bassins ayant servi à estimer le modèle. Globalement l’accord est acceptable, mais les incertitudes autour des débits prédits sont très importantes : la régression permet d’estimer un ordre de grandeur du débit biennal, mais la précision autour de cette estimation est très faible. La Figure III-11b effectue la même comparaison pour les 15 bassins de validation : on n’observe pas de dégradation particulière de la qualité des prédictions, mais les incertitudes de prédictions sont toujours très importantes.
Figure III-11. Comparaison entre les débits biennaux observés (i.e. calculés directement à partir des chroniques de débit) et simulés par le modèle de régression. Panneau de gauche : 30
stations utilisées pour l’estimation des paramètres, panneau de droite : 15 stations de validation.